Docs Prettier reformat (#13483)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: UltralyticsAssistant <web@ultralytics.com>
This commit is contained in:
parent
2f2e81614f
commit
e5185ccf63
90 changed files with 763 additions and 742 deletions
|
|
@ -108,29 +108,29 @@ YOLOv5 employs various data augmentation techniques to improve the model's abili
|
|||
|
||||
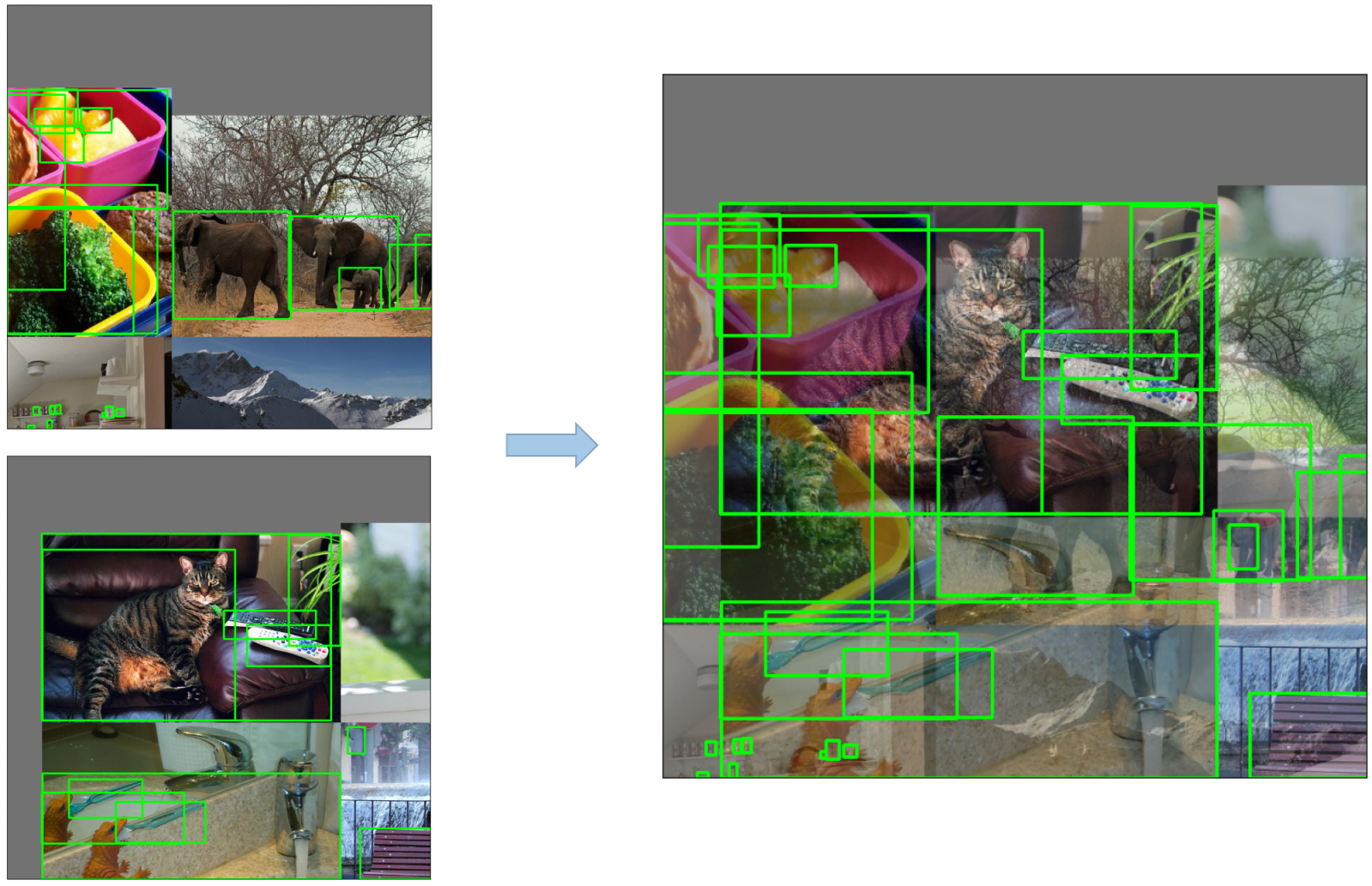
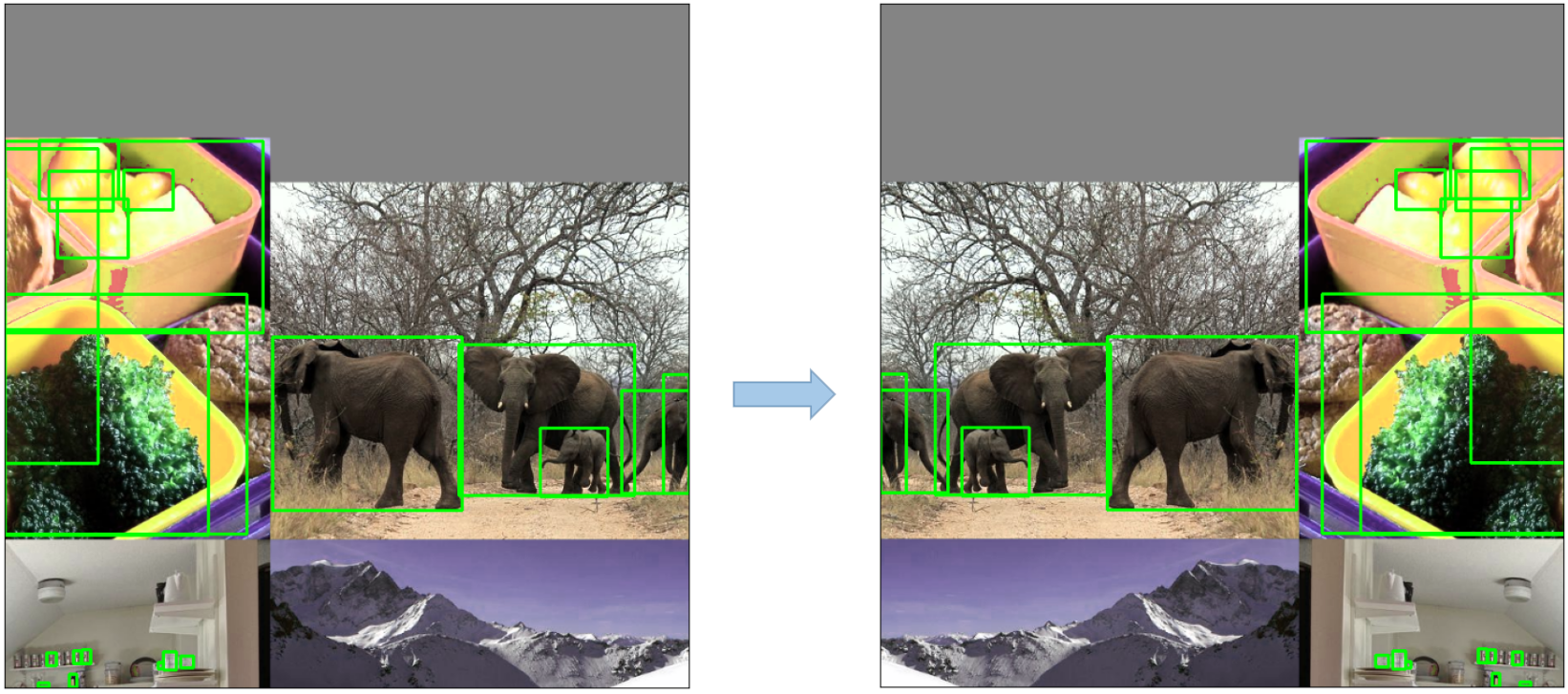
- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage object detection models to better handle various object scales and translations.
|
||||
|
||||

|
||||

|
||||
|
||||
- **Copy-Paste Augmentation**: An innovative data augmentation method that copies random patches from an image and pastes them onto another randomly chosen image, effectively generating a new training sample.
|
||||
|
||||

|
||||

|
||||
|
||||
- **Random Affine Transformations**: This includes random rotation, scaling, translation, and shearing of the images.
|
||||
|
||||

|
||||

|
||||
|
||||
- **MixUp Augmentation**: A method that creates composite images by taking a linear combination of two images and their associated labels.
|
||||
|
||||
|
||||

|
||||
|
||||
- **Albumentations**: A powerful library for image augmenting that supports a wide variety of augmentation techniques.
|
||||
|
||||
- **HSV Augmentation**: Random changes to the Hue, Saturation, and Value of the images.
|
||||
|
||||

|
||||

|
||||
|
||||
- **Random Horizontal Flip**: An augmentation method that randomly flips images horizontally.
|
||||
|
||||
|
||||

|
||||
|
||||
## 3. Training Strategies
|
||||
|
||||
|
|
|
|||
|
|
@ -28,35 +28,35 @@ YOLOv5 has about 30 hyperparameters used for various training settings. These ar
|
|||
# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
|
||||
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
|
||||
|
||||
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
||||
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
|
||||
momentum: 0.937 # SGD momentum/Adam beta1
|
||||
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
||||
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
||||
warmup_momentum: 0.8 # warmup initial momentum
|
||||
warmup_bias_lr: 0.1 # warmup initial bias lr
|
||||
box: 0.05 # box loss gain
|
||||
cls: 0.5 # cls loss gain
|
||||
cls_pw: 1.0 # cls BCELoss positive_weight
|
||||
obj: 1.0 # obj loss gain (scale with pixels)
|
||||
obj_pw: 1.0 # obj BCELoss positive_weight
|
||||
iou_t: 0.20 # IoU training threshold
|
||||
anchor_t: 4.0 # anchor-multiple threshold
|
||||
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
||||
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
|
||||
momentum: 0.937 # SGD momentum/Adam beta1
|
||||
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
||||
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
||||
warmup_momentum: 0.8 # warmup initial momentum
|
||||
warmup_bias_lr: 0.1 # warmup initial bias lr
|
||||
box: 0.05 # box loss gain
|
||||
cls: 0.5 # cls loss gain
|
||||
cls_pw: 1.0 # cls BCELoss positive_weight
|
||||
obj: 1.0 # obj loss gain (scale with pixels)
|
||||
obj_pw: 1.0 # obj BCELoss positive_weight
|
||||
iou_t: 0.20 # IoU training threshold
|
||||
anchor_t: 4.0 # anchor-multiple threshold
|
||||
# anchors: 3 # anchors per output layer (0 to ignore)
|
||||
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
||||
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
||||
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
||||
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
||||
degrees: 0.0 # image rotation (+/- deg)
|
||||
translate: 0.1 # image translation (+/- fraction)
|
||||
scale: 0.5 # image scale (+/- gain)
|
||||
shear: 0.0 # image shear (+/- deg)
|
||||
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
||||
flipud: 0.0 # image flip up-down (probability)
|
||||
fliplr: 0.5 # image flip left-right (probability)
|
||||
mosaic: 1.0 # image mosaic (probability)
|
||||
mixup: 0.0 # image mixup (probability)
|
||||
copy_paste: 0.0 # segment copy-paste (probability)
|
||||
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
||||
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
||||
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
||||
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
||||
degrees: 0.0 # image rotation (+/- deg)
|
||||
translate: 0.1 # image translation (+/- fraction)
|
||||
scale: 0.5 # image scale (+/- gain)
|
||||
shear: 0.0 # image shear (+/- deg)
|
||||
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
||||
flipud: 0.0 # image flip up-down (probability)
|
||||
fliplr: 0.5 # image flip left-right (probability)
|
||||
mosaic: 1.0 # image mosaic (probability)
|
||||
mixup: 0.0 # image mixup (probability)
|
||||
copy_paste: 0.0 # segment copy-paste (probability)
|
||||
```
|
||||
|
||||
## 2. Define Fitness
|
||||
|
|
@ -110,35 +110,35 @@ The main genetic operators are **crossover** and **mutation**. In this work muta
|
|||
# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
|
||||
# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
|
||||
|
||||
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
||||
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
|
||||
momentum: 0.937 # SGD momentum/Adam beta1
|
||||
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
||||
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
||||
warmup_momentum: 0.8 # warmup initial momentum
|
||||
warmup_bias_lr: 0.1 # warmup initial bias lr
|
||||
box: 0.05 # box loss gain
|
||||
cls: 0.5 # cls loss gain
|
||||
cls_pw: 1.0 # cls BCELoss positive_weight
|
||||
obj: 1.0 # obj loss gain (scale with pixels)
|
||||
obj_pw: 1.0 # obj BCELoss positive_weight
|
||||
iou_t: 0.20 # IoU training threshold
|
||||
anchor_t: 4.0 # anchor-multiple threshold
|
||||
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
||||
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
|
||||
momentum: 0.937 # SGD momentum/Adam beta1
|
||||
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
||||
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
||||
warmup_momentum: 0.8 # warmup initial momentum
|
||||
warmup_bias_lr: 0.1 # warmup initial bias lr
|
||||
box: 0.05 # box loss gain
|
||||
cls: 0.5 # cls loss gain
|
||||
cls_pw: 1.0 # cls BCELoss positive_weight
|
||||
obj: 1.0 # obj loss gain (scale with pixels)
|
||||
obj_pw: 1.0 # obj BCELoss positive_weight
|
||||
iou_t: 0.20 # IoU training threshold
|
||||
anchor_t: 4.0 # anchor-multiple threshold
|
||||
# anchors: 3 # anchors per output layer (0 to ignore)
|
||||
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
||||
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
||||
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
||||
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
||||
degrees: 0.0 # image rotation (+/- deg)
|
||||
translate: 0.1 # image translation (+/- fraction)
|
||||
scale: 0.5 # image scale (+/- gain)
|
||||
shear: 0.0 # image shear (+/- deg)
|
||||
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
||||
flipud: 0.0 # image flip up-down (probability)
|
||||
fliplr: 0.5 # image flip left-right (probability)
|
||||
mosaic: 1.0 # image mosaic (probability)
|
||||
mixup: 0.0 # image mixup (probability)
|
||||
copy_paste: 0.0 # segment copy-paste (probability)
|
||||
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
||||
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
||||
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
||||
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
||||
degrees: 0.0 # image rotation (+/- deg)
|
||||
translate: 0.1 # image translation (+/- fraction)
|
||||
scale: 0.5 # image scale (+/- gain)
|
||||
shear: 0.0 # image shear (+/- deg)
|
||||
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
||||
flipud: 0.0 # image flip up-down (probability)
|
||||
fliplr: 0.5 # image flip left-right (probability)
|
||||
mosaic: 1.0 # image mosaic (probability)
|
||||
mixup: 0.0 # image mixup (probability)
|
||||
copy_paste: 0.0 # segment copy-paste (probability)
|
||||
```
|
||||
|
||||
We recommend a minimum of 300 generations of evolution for best results. Note that **evolution is generally expensive and time-consuming**, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ YOLOv5 inference is officially supported in 11 formats:
|
|||
💡 ProTip: Export to ONNX or OpenVINO for up to 3x CPU speedup. See [CPU Benchmarks](https://github.com/ultralytics/yolov5/pull/6613). 💡 ProTip: Export to TensorRT for up to 5x GPU speedup. See [GPU Benchmarks](https://github.com/ultralytics/yolov5/pull/6963).
|
||||
|
||||
| Format | `export.py --include` | Model |
|
||||
|:---------------------------------------------------------------------------|:----------------------|:--------------------------|
|
||||
| :------------------------------------------------------------------------- | :-------------------- | :------------------------ |
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov5s.pt` |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov5s.torchscript` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov5s.onnx` |
|
||||
|
|
|
|||
|
|
@ -143,7 +143,7 @@ python -m torch.distributed.run --nproc_per_node 8 train.py --batch-size 128 --d
|
|||
</details>
|
||||
|
||||
| GPUs<br>A100 | batch-size | CUDA_mem<br><sup>device0 (G) | COCO<br><sup>train | COCO<br><sup>val |
|
||||
|--------------|------------|------------------------------|--------------------|------------------|
|
||||
| ------------ | ---------- | ---------------------------- | ------------------ | ---------------- |
|
||||
| 1x | 16 | 26GB | 20:39 | 0:55 |
|
||||
| 2x | 32 | 26GB | 11:43 | 0:57 |
|
||||
| 4x | 64 | 26GB | 5:57 | 0:55 |
|
||||
|
|
|
|||
|
|
@ -285,42 +285,42 @@ results.pandas().xyxy[0].to_json(orient="records") # JSON img1 predictions
|
|||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"xmin": 749.5,
|
||||
"ymin": 43.5,
|
||||
"xmax": 1148.0,
|
||||
"ymax": 704.5,
|
||||
"confidence": 0.8740234375,
|
||||
"class": 0,
|
||||
"name": "person"
|
||||
},
|
||||
{
|
||||
"xmin": 433.5,
|
||||
"ymin": 433.5,
|
||||
"xmax": 517.5,
|
||||
"ymax": 714.5,
|
||||
"confidence": 0.6879882812,
|
||||
"class": 27,
|
||||
"name": "tie"
|
||||
},
|
||||
{
|
||||
"xmin": 115.25,
|
||||
"ymin": 195.75,
|
||||
"xmax": 1096.0,
|
||||
"ymax": 708.0,
|
||||
"confidence": 0.6254882812,
|
||||
"class": 0,
|
||||
"name": "person"
|
||||
},
|
||||
{
|
||||
"xmin": 986.0,
|
||||
"ymin": 304.0,
|
||||
"xmax": 1028.0,
|
||||
"ymax": 420.0,
|
||||
"confidence": 0.2873535156,
|
||||
"class": 27,
|
||||
"name": "tie"
|
||||
}
|
||||
{
|
||||
"xmin": 749.5,
|
||||
"ymin": 43.5,
|
||||
"xmax": 1148.0,
|
||||
"ymax": 704.5,
|
||||
"confidence": 0.8740234375,
|
||||
"class": 0,
|
||||
"name": "person"
|
||||
},
|
||||
{
|
||||
"xmin": 433.5,
|
||||
"ymin": 433.5,
|
||||
"xmax": 517.5,
|
||||
"ymax": 714.5,
|
||||
"confidence": 0.6879882812,
|
||||
"class": 27,
|
||||
"name": "tie"
|
||||
},
|
||||
{
|
||||
"xmin": 115.25,
|
||||
"ymin": 195.75,
|
||||
"xmax": 1096.0,
|
||||
"ymax": 708.0,
|
||||
"confidence": 0.6254882812,
|
||||
"class": 0,
|
||||
"name": "person"
|
||||
},
|
||||
{
|
||||
"xmin": 986.0,
|
||||
"ymin": 304.0,
|
||||
"xmax": 1028.0,
|
||||
"ymax": 420.0,
|
||||
"confidence": 0.2873535156,
|
||||
"class": 27,
|
||||
"name": "tie"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -308,7 +308,7 @@ The above result is running on **Jetson Xavier NX** with **INT8** and **YOLOv5s
|
|||
The following table summarizes how different models perform on **Jetson Xavier NX**.
|
||||
|
||||
| Model Name | Precision | Inference Size | Inference Time (ms) | FPS |
|
||||
|------------|-----------|----------------|---------------------|-----|
|
||||
| ---------- | --------- | -------------- | ------------------- | --- |
|
||||
| YOLOv5s | FP32 | 320x320 | 16.66 | 60 |
|
||||
| | FP32 | 640x640 | 33.33 | 30 |
|
||||
| | INT8 | 640x640 | 16.66 | 60 |
|
||||
|
|
|
|||
|
|
@ -81,20 +81,20 @@ Export in `YOLOv5 Pytorch` format, then copy the snippet into your training scri
|
|||
|
||||
```yaml
|
||||
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||
path: ../datasets/coco128 # dataset root dir
|
||||
train: images/train2017 # train images (relative to 'path') 128 images
|
||||
val: images/train2017 # val images (relative to 'path') 128 images
|
||||
test: # test images (optional)
|
||||
path: ../datasets/coco128 # dataset root dir
|
||||
train: images/train2017 # train images (relative to 'path') 128 images
|
||||
val: images/train2017 # val images (relative to 'path') 128 images
|
||||
test: # test images (optional)
|
||||
|
||||
# Classes (80 COCO classes)
|
||||
names:
|
||||
0: person
|
||||
1: bicycle
|
||||
2: car
|
||||
# ...
|
||||
77: teddy bear
|
||||
78: hair drier
|
||||
79: toothbrush
|
||||
0: person
|
||||
1: bicycle
|
||||
2: car
|
||||
# ...
|
||||
77: teddy bear
|
||||
78: hair drier
|
||||
79: toothbrush
|
||||
```
|
||||
|
||||
### 2.2 Create Labels
|
||||
|
|
|
|||
|
|
@ -62,40 +62,39 @@ Looking at the model architecture we can see that the model backbone is layers 0
|
|||
```yaml
|
||||
# YOLOv5 v6.0 backbone
|
||||
backbone:
|
||||
# [from, number, module, args]
|
||||
- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2
|
||||
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
|
||||
- [-1, 3, C3, [128]]
|
||||
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
|
||||
- [-1, 6, C3, [256]]
|
||||
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
|
||||
- [-1, 9, C3, [512]]
|
||||
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
|
||||
- [-1, 3, C3, [1024]]
|
||||
- [-1, 1, SPPF, [1024, 5]] # 9
|
||||
|
||||
# [from, number, module, args]
|
||||
- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2
|
||||
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
|
||||
- [-1, 3, C3, [128]]
|
||||
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
|
||||
- [-1, 6, C3, [256]]
|
||||
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
|
||||
- [-1, 9, C3, [512]]
|
||||
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
|
||||
- [-1, 3, C3, [1024]]
|
||||
- [-1, 1, SPPF, [1024, 5]] # 9
|
||||
|
||||
# YOLOv5 v6.0 head
|
||||
head:
|
||||
- [-1, 1, Conv, [512, 1, 1]]
|
||||
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
|
||||
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
|
||||
- [-1, 3, C3, [512, False]] # 13
|
||||
- [-1, 1, Conv, [512, 1, 1]]
|
||||
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
|
||||
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
|
||||
- [-1, 3, C3, [512, False]] # 13
|
||||
|
||||
- [-1, 1, Conv, [256, 1, 1]]
|
||||
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
|
||||
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
|
||||
- [-1, 3, C3, [256, False]] # 17 (P3/8-small)
|
||||
- [-1, 1, Conv, [256, 1, 1]]
|
||||
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
|
||||
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
|
||||
- [-1, 3, C3, [256, False]] # 17 (P3/8-small)
|
||||
|
||||
- [-1, 1, Conv, [256, 3, 2]]
|
||||
- [[-1, 14], 1, Concat, [1]] # cat head P4
|
||||
- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)
|
||||
- [-1, 1, Conv, [256, 3, 2]]
|
||||
- [[-1, 14], 1, Concat, [1]] # cat head P4
|
||||
- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)
|
||||
|
||||
- [-1, 1, Conv, [512, 3, 2]]
|
||||
- [[-1, 10], 1, Concat, [1]] # cat head P5
|
||||
- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)
|
||||
- [-1, 1, Conv, [512, 3, 2]]
|
||||
- [[-1, 10], 1, Concat, [1]] # cat head P5
|
||||
- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)
|
||||
|
||||
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
|
||||
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
|
||||
```
|
||||
|
||||
so we can define the freeze list to contain all modules with 'model.0.' - 'model.9.' in their names:
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue