Docs Prettier reformat (#13483)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: UltralyticsAssistant <web@ultralytics.com>
This commit is contained in:
parent
2f2e81614f
commit
e5185ccf63
90 changed files with 763 additions and 742 deletions
|
|
@ -13,7 +13,7 @@ This guide provides a comprehensive overview of three fundamental types of data
|
|||
### Visual Samples
|
||||
|
||||
| Line Graph | Bar Plot | Pie Chart |
|
||||
|:------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------------:|
|
||||
| :----------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------: |
|
||||
|  |  |  |
|
||||
|
||||
### Why Graphs are Important
|
||||
|
|
@ -72,7 +72,7 @@ This guide provides a comprehensive overview of three fundamental types of data
|
|||
out.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
|
||||
=== "Multiple Lines"
|
||||
|
||||
```python
|
||||
|
|
@ -183,7 +183,7 @@ This guide provides a comprehensive overview of three fundamental types of data
|
|||
out.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
|
||||
=== "Bar Plot"
|
||||
|
||||
```python
|
||||
|
|
@ -233,7 +233,7 @@ This guide provides a comprehensive overview of three fundamental types of data
|
|||
out.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
|
||||
=== "Area chart"
|
||||
|
||||
```python
|
||||
|
|
@ -292,7 +292,7 @@ This guide provides a comprehensive overview of three fundamental types of data
|
|||
Here's a table with the `Analytics` arguments:
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|----------------|-------------------|---------------|----------------------------------------------------------------------------------|
|
||||
| -------------- | ----------------- | ------------- | -------------------------------------------------------------------------------- |
|
||||
| `type` | `str` | `None` | Type of data or object. |
|
||||
| `im0_shape` | `tuple` | `None` | Shape of the initial image. |
|
||||
| `writer` | `cv2.VideoWriter` | `None` | Object for writing video files. |
|
||||
|
|
@ -312,7 +312,7 @@ Here's a table with the `Analytics` arguments:
|
|||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| --------- | ------- | -------------- | ----------------------------------------------------------- |
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
|
|
|
|||
|
|
@ -38,7 +38,7 @@ This guide assumes that you already have a working Raspberry Pi OS install and h
|
|||
First, we need to install the Edge TPU runtime. There are many different versions available, so you need to choose the right version for your operating system.
|
||||
|
||||
| Raspberry Pi OS | High frequency mode | Version to download |
|
||||
|-----------------|:-------------------:|--------------------------------------------|
|
||||
| --------------- | :-----------------: | ------------------------------------------ |
|
||||
| Bullseye 32bit | No | `libedgetpu1-std_ ... .bullseye_armhf.deb` |
|
||||
| Bullseye 64bit | No | `libedgetpu1-std_ ... .bullseye_arm64.deb` |
|
||||
| Bullseye 32bit | Yes | `libedgetpu1-max_ ... .bullseye_armhf.deb` |
|
||||
|
|
@ -64,10 +64,10 @@ After installing the runtime, you need to plug in your Coral Edge TPU into a USB
|
|||
|
||||
```bash
|
||||
# If you installed the standard version
|
||||
sudo apt remove libedgetpu1-std
|
||||
sudo apt remove libedgetpu1-std
|
||||
|
||||
# If you installed the high frequency version
|
||||
sudo apt remove libedgetpu1-max
|
||||
sudo apt remove libedgetpu1-max
|
||||
```
|
||||
|
||||
## Export your model to a Edge TPU compatible model
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ Every consideration regarding the data should closely align with [your project's
|
|||
|
||||
## Setting Up Classes and Collecting Data
|
||||
|
||||
Collecting images and video for a computer vision project involves defining the number of classes, sourcing data, and considering ethical implications. Before you start gathering your data, you need to be clear about:
|
||||
Collecting images and video for a computer vision project involves defining the number of classes, sourcing data, and considering ethical implications. Before you start gathering your data, you need to be clear about:
|
||||
|
||||
### Choosing the Right Classes for Your Project
|
||||
|
||||
|
|
@ -31,13 +31,13 @@ Something to note is that starting with more specific classes can be very helpfu
|
|||
|
||||
### Sources of Data
|
||||
|
||||
You can use public datasets or gather your own custom data. Public datasets like those on [Kaggle](https://www.kaggle.com/datasets) and [Google Dataset Search Engine](https://datasetsearch.research.google.com/) offer well-annotated, standardized data, making them great starting points for training and validating models.
|
||||
You can use public datasets or gather your own custom data. Public datasets like those on [Kaggle](https://www.kaggle.com/datasets) and [Google Dataset Search Engine](https://datasetsearch.research.google.com/) offer well-annotated, standardized data, making them great starting points for training and validating models.
|
||||
|
||||
Custom data collection, on the other hand, allows you to customize your dataset to your specific needs. You might capture images and videos with cameras or drones, scrape the web for images, or use existing internal data from your organization. Custom data gives you more control over its quality and relevance. Combining both public and custom data sources helps create a diverse and comprehensive dataset.
|
||||
|
||||
### Avoiding Bias in Data Collection
|
||||
|
||||
Bias occurs when certain groups or scenarios are underrepresented or overrepresented in your dataset. It leads to a model that performs well on some data but poorly on others. It's crucial to avoid bias so that your computer vision model can perform well in a variety of scenarios.
|
||||
Bias occurs when certain groups or scenarios are underrepresented or overrepresented in your dataset. It leads to a model that performs well on some data but poorly on others. It's crucial to avoid bias so that your computer vision model can perform well in a variety of scenarios.
|
||||
|
||||
Here is how you can avoid bias while collecting data:
|
||||
|
||||
|
|
@ -67,7 +67,7 @@ Depending on the specific requirements of a [computer vision task](../tasks/inde
|
|||
|
||||
### Common Annotation Formats
|
||||
|
||||
After selecting a type of annotation, it's important to choose the appropriate format for storing and sharing annotations.
|
||||
After selecting a type of annotation, it's important to choose the appropriate format for storing and sharing annotations.
|
||||
|
||||
Commonly used formats include [COCO](../datasets/detect/coco.md), which supports various annotation types like object detection, keypoint detection, stuff segmentation, panoptic segmentation, and image captioning, stored in JSON. [Pascal VOC](../datasets/detect/voc.md) uses XML files and is popular for object detection tasks. YOLO, on the other hand, creates a .txt file for each image, containing annotations like object class, coordinates, height, and width, making it suitable for object detection.
|
||||
|
||||
|
|
@ -84,7 +84,7 @@ Regularly reviewing and updating your labeling rules will help keep your annotat
|
|||
|
||||
### Popular Annotation Tools
|
||||
|
||||
Let's say you are ready to annotate now. There are several open-source tools available to help streamline the data annotation process. Here are some useful open annotation tools:
|
||||
Let's say you are ready to annotate now. There are several open-source tools available to help streamline the data annotation process. Here are some useful open annotation tools:
|
||||
|
||||
- **[Label Studio](https://github.com/HumanSignal/label-studio)**: A flexible tool that supports a wide range of annotation tasks and includes features for managing projects and quality control.
|
||||
- **[CVAT](https://github.com/cvat-ai/cvat)**: A powerful tool that supports various annotation formats and customizable workflows, making it suitable for complex projects.
|
||||
|
|
@ -98,7 +98,7 @@ These open-source tools are budget-friendly and provide a range of features to m
|
|||
|
||||
### Some More Things to Consider Before Annotating Data
|
||||
|
||||
Before you dive into annotating your data, there are a few more things to keep in mind. You should be aware of accuracy, precision, outliers, and quality control to avoid labeling your data in a counterproductive manner.
|
||||
Before you dive into annotating your data, there are a few more things to keep in mind. You should be aware of accuracy, precision, outliers, and quality control to avoid labeling your data in a counterproductive manner.
|
||||
|
||||
#### Understanding Accuracy and Precision
|
||||
|
||||
|
|
@ -135,6 +135,7 @@ While reviewing, if you find errors, correct them and update the guidelines to a
|
|||
Here are some questions that might encounter while collecting and annotating data:
|
||||
|
||||
- **Q1:** What is active learning in the context of data annotation?
|
||||
|
||||
- **A1:** Active learning in data annotation is a technique where a machine learning model iteratively selects the most informative data points for labeling. This improves the model's performance with fewer labeled examples. By focusing on the most valuable data, active learning accelerates the training process and improves the model's ability to generalize from limited data.
|
||||
|
||||
<p align="center">
|
||||
|
|
@ -142,9 +143,11 @@ Here are some questions that might encounter while collecting and annotating dat
|
|||
</p>
|
||||
|
||||
- **Q2:** How does automated annotation work?
|
||||
|
||||
- **A2:** Automated annotation uses pre-trained models and algorithms to label data without needing human effort. These models, which have been trained on large datasets, can identify patterns and features in new data. Techniques like transfer learning adjust these models for specific tasks, and active learning helps by selecting the most useful data points for labeling. However, this approach is only possible in certain cases where the model has been trained on sufficiently similar data and tasks.
|
||||
|
||||
- **Q3:** How many images do I need to collect for [YOLOv8 custom training](../modes/train.md)?
|
||||
|
||||
- **A3:** For transfer learning and object detection, a good general rule of thumb is to have a minimum of a few hundred annotated objects per class. However, when training a model to detect just one class, it is advisable to start with at least 100 annotated images and train for around 100 epochs. For complex tasks, you may need thousands of images per class to achieve reliable model performance.
|
||||
|
||||
## Share Your Thoughts with the Community
|
||||
|
|
|
|||
|
|
@ -63,9 +63,11 @@ Other tasks, like [object detection](../tasks/detect.md), are not suitable as th
|
|||
The order of model selection, dataset preparation, and training approach depends on the specifics of your project. Here are a few tips to help you decide:
|
||||
|
||||
- **Clear Understanding of the Problem**: If your problem and objectives are well-defined, start with model selection. Then, prepare your dataset and decide on the training approach based on the model's requirements.
|
||||
|
||||
- **Example**: Start by selecting a model for a traffic monitoring system that estimates vehicle speeds. Choose an object tracking model, gather and annotate highway videos, and then train the model with techniques for real-time video processing.
|
||||
|
||||
- **Unique or Limited Data**: If your project is constrained by unique or limited data, begin with dataset preparation. For instance, if you have a rare dataset of medical images, annotate and prepare the data first. Then, select a model that performs well on such data, followed by choosing a suitable training approach.
|
||||
|
||||
- **Example**: Prepare the data first for a facial recognition system with a small dataset. Annotate it, then select a model that works well with limited data, such as a pre-trained model for transfer learning. Finally, decide on a training approach, including data augmentation, to expand the dataset.
|
||||
|
||||
- **Need for Experimentation**: In projects where experimentation is crucial, start with the training approach. This is common in research projects where you might initially test different training techniques. Refine your model selection after identifying a promising method and prepare the dataset based on your findings.
|
||||
|
|
@ -118,6 +120,7 @@ Here are some questions that might encounter while defining your computer vision
|
|||
</p>
|
||||
|
||||
- **Q2:** Can the scope of a computer vision project change after the problem statement is defined?
|
||||
|
||||
- **A2:** Yes, the scope of a computer vision project can change as new information becomes available or as project requirements evolve. It's important to regularly review and adjust the problem statement and objectives to reflect any new insights or changes in project direction.
|
||||
|
||||
- **Q3:** What are some common challenges in defining the problem for a computer vision project?
|
||||
|
|
@ -130,7 +133,7 @@ Connecting with other computer vision enthusiasts can be incredibly helpful for
|
|||
### Community Support Channels
|
||||
|
||||
- **GitHub Issues:** Head over to the YOLOv8 GitHub repository. You can use the [Issues tab](https://github.com/ultralytics/ultralytics/issues) to raise questions, report bugs, and suggest features. The community and maintainers can assist with specific problems you encounter.
|
||||
- **Ultralytics Discord Server:** Become part of the [Ultralytics Discord server](https://ultralytics.com/discord/). Connect with fellow users and developers, seek support, exchange knowledge, and discuss ideas.
|
||||
- **Ultralytics Discord Server:** Become part of the [Ultralytics Discord server](https://ultralytics.com/discord/). Connect with fellow users and developers, seek support, exchange knowledge, and discuss ideas.
|
||||
|
||||
### Comprehensive Guides and Documentation
|
||||
|
||||
|
|
|
|||
|
|
@ -23,8 +23,8 @@ Measuring the gap between two objects is known as distance calculation within a
|
|||
|
||||
## Visuals
|
||||
|
||||
| Distance Calculation using Ultralytics YOLOv8 |
|
||||
|:-----------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| Distance Calculation using Ultralytics YOLOv8 |
|
||||
| :---------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
|  |
|
||||
|
||||
## Advantages of Distance Calculation?
|
||||
|
|
@ -82,7 +82,7 @@ Measuring the gap between two objects is known as distance calculation within a
|
|||
### Arguments `DistanceCalculation()`
|
||||
|
||||
| `Name` | `Type` | `Default` | Description |
|
||||
|--------------------|---------|-----------------|-----------------------------------------------------------|
|
||||
| ------------------ | ------- | --------------- | --------------------------------------------------------- |
|
||||
| `names` | `dict` | `None` | Dictionary mapping class indices to class names. |
|
||||
| `pixels_per_meter` | `int` | `10` | Conversion factor from pixels to meters. |
|
||||
| `view_img` | `bool` | `False` | Flag to indicate if the video stream should be displayed. |
|
||||
|
|
@ -93,7 +93,7 @@ Measuring the gap between two objects is known as distance calculation within a
|
|||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| --------- | ------- | -------------- | ----------------------------------------------------------- |
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
|
|
|
|||
|
|
@ -168,7 +168,7 @@ Setup and configuration of an X11 or Wayland display server is outside the scope
|
|||
|
||||
??? info "Use GPUs"
|
||||
If you're using [GPUs](#using-gpus), you can add the `--gpus all` flag to the command.
|
||||
|
||||
|
||||
=== "X11"
|
||||
|
||||
If you're using X11, you can run the following command to allow the Docker container to access the X11 socket:
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
|
|||
## Real World Applications
|
||||
|
||||
| Transportation | Retail |
|
||||
|:-----------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| :---------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
|  |  |
|
||||
| Ultralytics YOLOv8 Transportation Heatmap | Ultralytics YOLOv8 Retail Heatmap |
|
||||
|
||||
|
|
@ -119,7 +119,7 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
|
|||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
|
||||
=== "Polygon Counting"
|
||||
```python
|
||||
import cv2
|
||||
|
|
@ -271,7 +271,7 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
|
|||
### Arguments `Heatmap()`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|--------------------|------------------|--------------------|-------------------------------------------------------------------|
|
||||
| ------------------ | ---------------- | ------------------ | ----------------------------------------------------------------- |
|
||||
| `classes_names` | `dict` | `None` | Dictionary of class names. |
|
||||
| `imw` | `int` | `0` | Image width. |
|
||||
| `imh` | `int` | `0` | Image height. |
|
||||
|
|
@ -293,7 +293,7 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
|
|||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| --------- | ------- | -------------- | ----------------------------------------------------------- |
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
|
|
@ -304,7 +304,7 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
|
|||
### Heatmap COLORMAPs
|
||||
|
||||
| Colormap Name | Description |
|
||||
|---------------------------------|----------------------------------------|
|
||||
| ------------------------------- | -------------------------------------- |
|
||||
| `cv::COLORMAP_AUTUMN` | Autumn color map |
|
||||
| `cv::COLORMAP_BONE` | Bone color map |
|
||||
| `cv::COLORMAP_JET` | Jet color map |
|
||||
|
|
|
|||
|
|
@ -116,36 +116,37 @@ This YAML file contains the best-performing hyperparameters found during the tun
|
|||
- **Format**: YAML
|
||||
- **Usage**: Hyperparameter results
|
||||
- **Example**:
|
||||
```yaml
|
||||
# 558/900 iterations complete ✅ (45536.81s)
|
||||
# Results saved to /usr/src/ultralytics/runs/detect/tune
|
||||
# Best fitness=0.64297 observed at iteration 498
|
||||
# Best fitness metrics are {'metrics/precision(B)': 0.87247, 'metrics/recall(B)': 0.71387, 'metrics/mAP50(B)': 0.79106, 'metrics/mAP50-95(B)': 0.62651, 'val/box_loss': 2.79884, 'val/cls_loss': 2.72386, 'val/dfl_loss': 0.68503, 'fitness': 0.64297}
|
||||
# Best fitness model is /usr/src/ultralytics/runs/detect/train498
|
||||
# Best fitness hyperparameters are printed below.
|
||||
|
||||
lr0: 0.00269
|
||||
lrf: 0.00288
|
||||
momentum: 0.73375
|
||||
weight_decay: 0.00015
|
||||
warmup_epochs: 1.22935
|
||||
warmup_momentum: 0.1525
|
||||
box: 18.27875
|
||||
cls: 1.32899
|
||||
dfl: 0.56016
|
||||
hsv_h: 0.01148
|
||||
hsv_s: 0.53554
|
||||
hsv_v: 0.13636
|
||||
degrees: 0.0
|
||||
translate: 0.12431
|
||||
scale: 0.07643
|
||||
shear: 0.0
|
||||
perspective: 0.0
|
||||
flipud: 0.0
|
||||
fliplr: 0.08631
|
||||
mosaic: 0.42551
|
||||
mixup: 0.0
|
||||
copy_paste: 0.0
|
||||
```yaml
|
||||
# 558/900 iterations complete ✅ (45536.81s)
|
||||
# Results saved to /usr/src/ultralytics/runs/detect/tune
|
||||
# Best fitness=0.64297 observed at iteration 498
|
||||
# Best fitness metrics are {'metrics/precision(B)': 0.87247, 'metrics/recall(B)': 0.71387, 'metrics/mAP50(B)': 0.79106, 'metrics/mAP50-95(B)': 0.62651, 'val/box_loss': 2.79884, 'val/cls_loss': 2.72386, 'val/dfl_loss': 0.68503, 'fitness': 0.64297}
|
||||
# Best fitness model is /usr/src/ultralytics/runs/detect/train498
|
||||
# Best fitness hyperparameters are printed below.
|
||||
|
||||
lr0: 0.00269
|
||||
lrf: 0.00288
|
||||
momentum: 0.73375
|
||||
weight_decay: 0.00015
|
||||
warmup_epochs: 1.22935
|
||||
warmup_momentum: 0.1525
|
||||
box: 18.27875
|
||||
cls: 1.32899
|
||||
dfl: 0.56016
|
||||
hsv_h: 0.01148
|
||||
hsv_s: 0.53554
|
||||
hsv_v: 0.13636
|
||||
degrees: 0.0
|
||||
translate: 0.12431
|
||||
scale: 0.07643
|
||||
shear: 0.0
|
||||
perspective: 0.0
|
||||
flipud: 0.0
|
||||
fliplr: 0.08631
|
||||
mosaic: 0.42551
|
||||
mixup: 0.0
|
||||
copy_paste: 0.0
|
||||
```
|
||||
|
||||
#### best_fitness.png
|
||||
|
|
|
|||
|
|
@ -44,7 +44,7 @@ Here's a compilation of in-depth guides to help you master different aspects of
|
|||
- [OpenVINO Latency vs Throughput Modes](optimizing-openvino-latency-vs-throughput-modes.md) - Learn latency and throughput optimization techniques for peak YOLO inference performance.
|
||||
- [Steps of a Computer Vision Project ](steps-of-a-cv-project.md) 🚀 NEW: Learn about the key steps involved in a computer vision project, including defining goals, selecting models, preparing data, and evaluating results.
|
||||
- [Defining A Computer Vision Project's Goals](defining-project-goals.md) 🚀 NEW: Walk through how to effectively define clear and measurable goals for your computer vision project. Learn the importance of a well-defined problem statement and how it creates a roadmap for your project.
|
||||
- - [Data Collection and Annotation](data-collection-and-annotation.md)🚀 NEW: Explore the tools, techniques, and best practices for collecting and annotating data to create high-quality inputs for your computer vision models.
|
||||
- [Data Collection and Annotation](data-collection-and-annotation.md)🚀 NEW: Explore the tools, techniques, and best practices for collecting and annotating data to create high-quality inputs for your computer vision models.
|
||||
- [Preprocessing Annotated Data](preprocessing_annotated_data.md)🚀 NEW: Learn about preprocessing and augmenting image data in computer vision projects using YOLOv8, including normalization, dataset augmentation, splitting, and exploratory data analysis (EDA).
|
||||
|
||||
## Contribute to Our Guides
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ There are two types of instance segmentation tracking available in the Ultralyti
|
|||
## Samples
|
||||
|
||||
| Instance Segmentation | Instance Segmentation + Object Tracking |
|
||||
|:---------------------------------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| :-------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
|  |  |
|
||||
| Ultralytics Instance Segmentation 😍 | Ultralytics Instance Segmentation with Object Tracking 🔥 |
|
||||
|
||||
|
|
@ -126,7 +126,7 @@ There are two types of instance segmentation tracking available in the Ultralyti
|
|||
### `seg_bbox` Arguments
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|---------------|---------|-----------------|----------------------------------------|
|
||||
| ------------- | ------- | --------------- | -------------------------------------- |
|
||||
| `mask` | `array` | `None` | Segmentation mask coordinates |
|
||||
| `mask_color` | `tuple` | `(255, 0, 255)` | Mask color for every segmented box |
|
||||
| `det_label` | `str` | `None` | Label for segmented object |
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
## Recipe Walk Through
|
||||
|
||||
1. Begin with the necessary imports
|
||||
1. Begin with the necessary imports
|
||||
|
||||
```python
|
||||
from pathlib import Path
|
||||
|
|
@ -31,7 +31,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
***
|
||||
|
||||
2. Load a model and run `predict()` method on a source.
|
||||
2. Load a model and run `predict()` method on a source.
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
|
@ -58,7 +58,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
***
|
||||
|
||||
3. Now iterate over the results and the contours. For workflows that want to save an image to file, the source image `base-name` and the detection `class-label` are retrieved for later use (optional).
|
||||
3. Now iterate over the results and the contours. For workflows that want to save an image to file, the source image `base-name` and the detection `class-label` are retrieved for later use (optional).
|
||||
|
||||
```{ .py .annotate }
|
||||
# (2) Iterate detection results (helpful for multiple images)
|
||||
|
|
@ -81,7 +81,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
***
|
||||
|
||||
4. Start with generating a binary mask from the source image and then draw a filled contour onto the mask. This will allow the object to be isolated from the other parts of the image. An example from `bus.jpg` for one of the detected `person` class objects is shown on the right.
|
||||
4. Start with generating a binary mask from the source image and then draw a filled contour onto the mask. This will allow the object to be isolated from the other parts of the image. An example from `bus.jpg` for one of the detected `person` class objects is shown on the right.
|
||||
|
||||
{ width="240", align="right" }
|
||||
|
||||
|
|
@ -140,7 +140,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
***
|
||||
|
||||
5. Next there are 2 options for how to move forward with the image from this point and a subsequent option for each.
|
||||
5. Next there are 2 options for how to move forward with the image from this point and a subsequent option for each.
|
||||
|
||||
### Object Isolation Options
|
||||
|
||||
|
|
@ -251,7 +251,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
***
|
||||
|
||||
6. <u>What to do next is entirely left to you as the developer.</u> A basic example of one possible next step (saving the image to file for future use) is shown.
|
||||
6. <u>What to do next is entirely left to you as the developer.</u> A basic example of one possible next step (saving the image to file for future use) is shown.
|
||||
|
||||
- **NOTE:** this step is optional and can be skipped if not required for your specific use case.
|
||||
|
||||
|
|
|
|||
|
|
@ -29,7 +29,7 @@ Without further ado, let's dive in!
|
|||
- It includes 6 class labels, each with its total instance counts listed below.
|
||||
|
||||
| Class Label | Instance Count |
|
||||
|:------------|:--------------:|
|
||||
| :---------- | :------------: |
|
||||
| Apple | 7049 |
|
||||
| Grapes | 7202 |
|
||||
| Pineapple | 1613 |
|
||||
|
|
@ -173,7 +173,7 @@ The rows index the label files, each corresponding to an image in your dataset,
|
|||
fold_lbl_distrb.loc[f"split_{n}"] = ratio
|
||||
```
|
||||
|
||||
The ideal scenario is for all class ratios to be reasonably similar for each split and across classes. This, however, will be subject to the specifics of your dataset.
|
||||
The ideal scenario is for all class ratios to be reasonably similar for each split and across classes. This, however, will be subject to the specifics of your dataset.
|
||||
|
||||
4. Next, we create the directories and dataset YAML files for each split.
|
||||
|
||||
|
|
@ -219,7 +219,7 @@ The rows index the label files, each corresponding to an image in your dataset,
|
|||
|
||||
5. Lastly, copy images and labels into the respective directory ('train' or 'val') for each split.
|
||||
|
||||
- __NOTE:__ The time required for this portion of the code will vary based on the size of your dataset and your system hardware.
|
||||
- **NOTE:** The time required for this portion of the code will vary based on the size of your dataset and your system hardware.
|
||||
|
||||
```python
|
||||
for image, label in zip(images, labels):
|
||||
|
|
|
|||
|
|
@ -263,7 +263,7 @@ NCNN is a high-performance neural network inference framework optimized for the
|
|||
The following table provides a snapshot of the various deployment options available for YOLOv8 models, helping you to assess which may best fit your project needs based on several critical criteria. For an in-depth look at each deployment option's format, please see the [Ultralytics documentation page on export formats](../modes/export.md#export-formats).
|
||||
|
||||
| Deployment Option | Performance Benchmarks | Compatibility and Integration | Community Support and Ecosystem | Case Studies | Maintenance and Updates | Security Considerations | Hardware Acceleration |
|
||||
|-------------------|-------------------------------------------------|------------------------------------------------|-----------------------------------------------|--------------------------------------------|---------------------------------------------|---------------------------------------------------|------------------------------------|
|
||||
| ----------------- | ----------------------------------------------- | ---------------------------------------------- | --------------------------------------------- | ------------------------------------------ | ------------------------------------------- | ------------------------------------------------- | ---------------------------------- |
|
||||
| PyTorch | Good flexibility; may trade off raw performance | Excellent with Python libraries | Extensive resources and community | Research and prototypes | Regular, active development | Dependent on deployment environment | CUDA support for GPU acceleration |
|
||||
| TorchScript | Better for production than PyTorch | Smooth transition from PyTorch to C++ | Specialized but narrower than PyTorch | Industry where Python is a bottleneck | Consistent updates with PyTorch | Improved security without full Python | Inherits CUDA support from PyTorch |
|
||||
| ONNX | Variable depending on runtime | High across different frameworks | Broad ecosystem, supported by many orgs | Flexibility across ML frameworks | Regular updates for new operations | Ensure secure conversion and deployment practices | Various hardware optimizations |
|
||||
|
|
|
|||
|
|
@ -22,14 +22,14 @@ NVIDIA Jetson is a series of embedded computing boards designed to bring acceler
|
|||
|
||||
[Jetson Orin](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-orin/) is the latest iteration of the NVIDIA Jetson family based on NVIDIA Ampere architecture which brings drastically improved AI performance when compared to the previous generations. Below table compared few of the Jetson devices in the ecosystem.
|
||||
|
||||
| | Jetson AGX Orin 64GB | Jetson Orin NX 16GB | Jetson Orin Nano 8GB | Jetson AGX Xavier | Jetson Xavier NX | Jetson Nano |
|
||||
|-------------------|------------------------------------------------------------------|-----------------------------------------------------------------|---------------------------------------------------------------|-------------------------------------------------------------|--------------------------------------------------------------|---------------------------------------------|
|
||||
| AI Performance | 275 TOPS | 100 TOPS | 40 TOPs | 32 TOPS | 21 TOPS | 472 GFLOPS |
|
||||
| GPU | 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores | 512-core NVIDIA Volta architecture GPU with 64 Tensor Cores | 384-core NVIDIA Volta™ architecture GPU with 48 Tensor Cores | 128-core NVIDIA Maxwell™ architecture GPU |
|
||||
| GPU Max Frequency | 1.3 GHz | 918 MHz | 625 MHz | 1377 MHz | 1100 MHz | 921MHz |
|
||||
| CPU | 12-core NVIDIA Arm® Cortex A78AE v8.2 64-bit CPU 3MB L2 + 6MB L3 | 8-core NVIDIA Arm® Cortex A78AE v8.2 64-bit CPU 2MB L2 + 4MB L3 | 6-core Arm® Cortex®-A78AE v8.2 64-bit CPU 1.5MB L2 + 4MB L3 | 8-core NVIDIA Carmel Arm®v8.2 64-bit CPU 8MB L2 + 4MB L3 | 6-core NVIDIA Carmel Arm®v8.2 64-bit CPU 6MB L2 + 4MB L3 | Quad-Core Arm® Cortex®-A57 MPCore processor |
|
||||
| CPU Max Frequency | 2.2 GHz | 2.0 GHz | 1.5 GHz | 2.2 GHz | 1.9 GHz | 1.43GHz |
|
||||
| Memory | 64GB 256-bit LPDDR5 204.8GB/s | 16GB 128-bit LPDDR5 102.4GB/s | 8GB 128-bit LPDDR5 68 GB/s | 32GB 256-bit LPDDR4x 136.5GB/s | 8GB 128-bit LPDDR4x 59.7GB/s | 4GB 64-bit LPDDR4 25.6GB/s" |
|
||||
| | Jetson AGX Orin 64GB | Jetson Orin NX 16GB | Jetson Orin Nano 8GB | Jetson AGX Xavier | Jetson Xavier NX | Jetson Nano |
|
||||
| ----------------- | ----------------------------------------------------------------- | ---------------------------------------------------------------- | ------------------------------------------------------------- | ----------------------------------------------------------- | ------------------------------------------------------------- | --------------------------------------------- |
|
||||
| AI Performance | 275 TOPS | 100 TOPS | 40 TOPs | 32 TOPS | 21 TOPS | 472 GFLOPS |
|
||||
| GPU | 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores | 512-core NVIDIA Volta architecture GPU with 64 Tensor Cores | 384-core NVIDIA Volta™ architecture GPU with 48 Tensor Cores | 128-core NVIDIA Maxwell™ architecture GPU |
|
||||
| GPU Max Frequency | 1.3 GHz | 918 MHz | 625 MHz | 1377 MHz | 1100 MHz | 921MHz |
|
||||
| CPU | 12-core NVIDIA Arm® Cortex A78AE v8.2 64-bit CPU 3MB L2 + 6MB L3 | 8-core NVIDIA Arm® Cortex A78AE v8.2 64-bit CPU 2MB L2 + 4MB L3 | 6-core Arm® Cortex®-A78AE v8.2 64-bit CPU 1.5MB L2 + 4MB L3 | 8-core NVIDIA Carmel Arm®v8.2 64-bit CPU 8MB L2 + 4MB L3 | 6-core NVIDIA Carmel Arm®v8.2 64-bit CPU 6MB L2 + 4MB L3 | Quad-Core Arm® Cortex®-A57 MPCore processor |
|
||||
| CPU Max Frequency | 2.2 GHz | 2.0 GHz | 1.5 GHz | 2.2 GHz | 1.9 GHz | 1.43GHz |
|
||||
| Memory | 64GB 256-bit LPDDR5 204.8GB/s | 16GB 128-bit LPDDR5 102.4GB/s | 8GB 128-bit LPDDR5 68 GB/s | 32GB 256-bit LPDDR4x 136.5GB/s | 8GB 128-bit LPDDR4x 59.7GB/s | 4GB 64-bit LPDDR4 25.6GB/s" |
|
||||
|
||||
For a more detailed comparison table, please visit the **Technical Specifications** section of [official NVIDIA Jetson page](https://developer.nvidia.com/embedded/jetson-modules).
|
||||
|
||||
|
|
|
|||
|
|
@ -72,7 +72,7 @@ Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
|
|||
### Arguments `model.predict`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------------|----------------|------------------------|----------------------------------------------------------------------------|
|
||||
| --------------- | -------------- | ---------------------- | -------------------------------------------------------------------------- |
|
||||
| `source` | `str` | `'ultralytics/assets'` | source directory for images or videos |
|
||||
| `conf` | `float` | `0.25` | object confidence threshold for detection |
|
||||
| `iou` | `float` | `0.7` | intersection over union (IoU) threshold for NMS |
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
|
|||
## Real World Applications
|
||||
|
||||
| Logistics | Aquaculture |
|
||||
|:-------------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| :-----------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
|  |  |
|
||||
| Conveyor Belt Packets Counting Using Ultralytics YOLOv8 | Fish Counting in Sea using Ultralytics YOLOv8 |
|
||||
|
||||
|
|
@ -89,7 +89,7 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
|
|||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
|
||||
=== "Count in Polygon"
|
||||
|
||||
```python
|
||||
|
|
@ -131,7 +131,7 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
|
|||
video_writer.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
|
||||
=== "Count in Line"
|
||||
|
||||
```python
|
||||
|
|
@ -225,7 +225,7 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
|
|||
Here's a table with the `ObjectCounter` arguments:
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|----------------------|---------|----------------------------|------------------------------------------------------------------------|
|
||||
| -------------------- | ------- | -------------------------- | ---------------------------------------------------------------------- |
|
||||
| `classes_names` | `dict` | `None` | Dictionary of class names. |
|
||||
| `reg_pts` | `list` | `[(20, 400), (1260, 400)]` | List of points defining the counting region. |
|
||||
| `count_reg_color` | `tuple` | `(255, 0, 255)` | RGB color of the counting region. |
|
||||
|
|
@ -245,7 +245,7 @@ Here's a table with the `ObjectCounter` arguments:
|
|||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| --------- | ------- | -------------- | ----------------------------------------------------------- |
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
|
|
|
|||
|
|
@ -18,10 +18,10 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
|
|||
|
||||
## Visuals
|
||||
|
||||
| Airport Luggage |
|
||||
|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| Airport Luggage |
|
||||
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
|  |
|
||||
| Suitcases Cropping at airport conveyor belt using Ultralytics YOLOv8 |
|
||||
| Suitcases Cropping at airport conveyor belt using Ultralytics YOLOv8 |
|
||||
|
||||
!!! Example "Object Cropping using YOLOv8 Example"
|
||||
|
||||
|
|
@ -84,7 +84,7 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
|
|||
### Arguments `model.predict`
|
||||
|
||||
| Argument | Type | Default | Description |
|
||||
|-----------------|----------------|------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| --------------- | -------------- | ---------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| `source` | `str` | `'ultralytics/assets'` | Specifies the data source for inference. Can be an image path, video file, directory, URL, or device ID for live feeds. Supports a wide range of formats and sources, enabling flexible application across different types of input. |
|
||||
| `conf` | `float` | `0.25` | Sets the minimum confidence threshold for detections. Objects detected with confidence below this threshold will be disregarded. Adjusting this value can help reduce false positives. |
|
||||
| `iou` | `float` | `0.7` | Intersection Over Union (IoU) threshold for Non-Maximum Suppression (NMS). Lower values result in fewer detections by eliminating overlapping boxes, useful for reducing duplicates. |
|
||||
|
|
|
|||
|
|
@ -36,12 +36,12 @@ Throughput optimization is crucial for scenarios serving numerous inference requ
|
|||
|
||||
1. **OpenVINO Performance Hints:** A high-level, future-proof method to enhance throughput across devices using performance hints.
|
||||
|
||||
```python
|
||||
import openvino.properties.hint as hints
|
||||
```python
|
||||
import openvino.properties.hint as hints
|
||||
|
||||
config = {hints.performance_mode: hints.PerformanceMode.THROUGHPUT}
|
||||
compiled_model = core.compile_model(model, "GPU", config)
|
||||
```
|
||||
config = {hints.performance_mode: hints.PerformanceMode.THROUGHPUT}
|
||||
compiled_model = core.compile_model(model, "GPU", config)
|
||||
```
|
||||
|
||||
2. **Explicit Batching and Streams:** A more granular approach involving explicit batching and the use of streams for advanced performance tuning.
|
||||
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultr
|
|||
## Real World Applications
|
||||
|
||||
| Parking Management System | Parking Management System |
|
||||
|:-------------------------------------------------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
|  |  |
|
||||
| Parking management Aerial View using Ultralytics YOLOv8 | Parking management Top View using Ultralytics YOLOv8 |
|
||||
|
||||
|
|
@ -101,7 +101,7 @@ Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultr
|
|||
### Optional Arguments `ParkingManagement`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|--------------------------|---------|-------------------|----------------------------------------|
|
||||
| ------------------------ | ------- | ----------------- | -------------------------------------- |
|
||||
| `model_path` | `str` | `None` | Path to the YOLOv8 model. |
|
||||
| `txt_color` | `tuple` | `(0, 0, 0)` | RGB color tuple for text. |
|
||||
| `bg_color` | `tuple` | `(255, 255, 255)` | RGB color tuple for background. |
|
||||
|
|
@ -112,7 +112,7 @@ Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultr
|
|||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| --------- | ------- | -------------- | ----------------------------------------------------------- |
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: data preprocessing, computer vision, image resizing, normalization, da
|
|||
|
||||
## Introduction
|
||||
|
||||
After you've defined your computer vision [project's goals](./defining-project-goals.md) and [collected and annotated data](./data-collection-and-annotation.md), the next step is to preprocess annotated data and prepare it for model training. Clean and consistent data are vital to creating a model that performs well.
|
||||
After you've defined your computer vision [project's goals](./defining-project-goals.md) and [collected and annotated data](./data-collection-and-annotation.md), the next step is to preprocess annotated data and prepare it for model training. Clean and consistent data are vital to creating a model that performs well.
|
||||
|
||||
Preprocessing is a step in the [computer vision project workflow](./steps-of-a-cv-project.md) that includes resizing images, normalizing pixel values, augmenting the dataset, and splitting the data into training, validation, and test sets. Let's explore the essential techniques and best practices for cleaning your data!
|
||||
|
||||
|
|
@ -22,7 +22,7 @@ We are already collecting and annotating our data carefully with multiple consid
|
|||
|
||||
## Data Preprocessing Techniques
|
||||
|
||||
One of the first and foremost steps in data preprocessing is resizing. Some models are designed to handle variable input sizes, but many models require a consistent input size. Resizing images makes them uniform and reduces computational complexity.
|
||||
One of the first and foremost steps in data preprocessing is resizing. Some models are designed to handle variable input sizes, but many models require a consistent input size. Resizing images makes them uniform and reduces computational complexity.
|
||||
|
||||
### Resizing Images
|
||||
|
||||
|
|
@ -31,12 +31,12 @@ You can resize your images using the following methods:
|
|||
- **Bilinear Interpolation**: Smooths pixel values by taking a weighted average of the four nearest pixel values.
|
||||
- **Nearest Neighbor**: Assigns the nearest pixel value without averaging, leading to a blocky image but faster computation.
|
||||
|
||||
To make resizing a simpler task, you can use the following tools:
|
||||
To make resizing a simpler task, you can use the following tools:
|
||||
|
||||
- **OpenCV**: A popular computer vision library with extensive functions for image processing.
|
||||
- **PIL (Pillow)**: A Python Imaging Library for opening, manipulating, and saving image files.
|
||||
|
||||
With respect to YOLOv8, the 'imgsz' parameter during [model training](../modes/train.md) allows for flexible input sizes. When set to a specific size, such as 640, the model will resize input images so their largest dimension is 640 pixels while maintaining the original aspect ratio.
|
||||
With respect to YOLOv8, the 'imgsz' parameter during [model training](../modes/train.md) allows for flexible input sizes. When set to a specific size, such as 640, the model will resize input images so their largest dimension is 640 pixels while maintaining the original aspect ratio.
|
||||
|
||||
By evaluating your model's and dataset's specific needs, you can determine whether resizing is a necessary preprocessing step or if your model can efficiently handle images of varying sizes.
|
||||
|
||||
|
|
@ -47,16 +47,16 @@ Another preprocessing technique is normalization. Normalization scales the pixel
|
|||
- **Min-Max Scaling**: Scales pixel values to a range of 0 to 1.
|
||||
- **Z-Score Normalization**: Scales pixel values based on their mean and standard deviation.
|
||||
|
||||
With respect to YOLOv8, normalization is seamlessly handled as part of its preprocessing pipeline during model training. YOLOv8 automatically performs several preprocessing steps, including conversion to RGB, scaling pixel values to the range [0, 1], and normalization using predefined mean and standard deviation values.
|
||||
With respect to YOLOv8, normalization is seamlessly handled as part of its preprocessing pipeline during model training. YOLOv8 automatically performs several preprocessing steps, including conversion to RGB, scaling pixel values to the range [0, 1], and normalization using predefined mean and standard deviation values.
|
||||
|
||||
### Splitting the Dataset
|
||||
|
||||
Once you've cleaned the data, you are ready to split the dataset. Splitting the data into training, validation, and test sets is done to ensure that the model can be evaluated on unseen data to assess its generalization performance. A common split is 70% for training, 20% for validation, and 10% for testing. There are various tools and libraries that you can use to split your data like scikit-learn or TensorFlow.
|
||||
Once you've cleaned the data, you are ready to split the dataset. Splitting the data into training, validation, and test sets is done to ensure that the model can be evaluated on unseen data to assess its generalization performance. A common split is 70% for training, 20% for validation, and 10% for testing. There are various tools and libraries that you can use to split your data like scikit-learn or TensorFlow.
|
||||
|
||||
Consider the following when splitting your dataset:
|
||||
|
||||
- **Maintaining Data Distribution**: Ensure that the data distribution of classes is maintained across training, validation, and test sets.
|
||||
- **Avoiding Data Leakage**: Typically, data augmentation is done after the dataset is split. Data augmentation and any other preprocessing should only be applied to the training set to prevent information from the validation or test sets from influencing the model training.
|
||||
-**Balancing Classes**: For imbalanced datasets, consider techniques such as oversampling the minority class or under-sampling the majority class within the training set.
|
||||
- **Avoiding Data Leakage**: Typically, data augmentation is done after the dataset is split. Data augmentation and any other preprocessing should only be applied to the training set to prevent information from the validation or test sets from influencing the model training. -**Balancing Classes**: For imbalanced datasets, consider techniques such as oversampling the minority class or under-sampling the majority class within the training set.
|
||||
|
||||
### What is Data Augmentation?
|
||||
|
||||
|
|
@ -89,13 +89,13 @@ Also, you can adjust the intensity of these augmentation techniques through spec
|
|||
|
||||
## A Case Study of Preprocessing
|
||||
|
||||
Consider a project aimed at developing a model to detect and classify different types of vehicles in traffic images using YOLOv8. We've collected traffic images and annotated them with bounding boxes and labels.
|
||||
Consider a project aimed at developing a model to detect and classify different types of vehicles in traffic images using YOLOv8. We've collected traffic images and annotated them with bounding boxes and labels.
|
||||
|
||||
Here's what each step of preprocessing would look like for this project:
|
||||
|
||||
- Resizing Images: Since YOLOv8 handles flexible input sizes and performs resizing automatically, manual resizing is not required. The model will adjust the image size according to the specified 'imgsz' parameter during training.
|
||||
- Normalizing Pixel Values: YOLOv8 automatically normalizes pixel values to a range of 0 to 1 during preprocessing, so it's not required.
|
||||
- Splitting the Dataset: Divide the dataset into training (70%), validation (20%), and test (10%) sets using tools like scikit-learn.
|
||||
- Splitting the Dataset: Divide the dataset into training (70%), validation (20%), and test (10%) sets using tools like scikit-learn.
|
||||
- Data Augmentation: Modify the dataset configuration file (.yaml) to include data augmentation techniques such as random crops, horizontal flips, and brightness adjustments.
|
||||
|
||||
These steps make sure the dataset is prepared without any potential issues and is ready for Exploratory Data Analysis (EDA).
|
||||
|
|
@ -104,11 +104,11 @@ These steps make sure the dataset is prepared without any potential issues and i
|
|||
|
||||
After preprocessing and augmenting your dataset, the next step is to gain insights through Exploratory Data Analysis. EDA uses statistical techniques and visualization tools to understand the patterns and distributions in your data. You can identify issues like class imbalances or outliers and make informed decisions about further data preprocessing or model training adjustments.
|
||||
|
||||
### Statistical EDA Techniques
|
||||
### Statistical EDA Techniques
|
||||
|
||||
Statistical techniques often begin with calculating basic metrics such as mean, median, standard deviation, and range. These metrics provide a quick overview of your image dataset's properties, such as pixel intensity distributions. Understanding these basic statistics helps you grasp the overall quality and characteristics of your data, allowing you to spot any irregularities early on.
|
||||
|
||||
### Visual EDA Techniques
|
||||
### Visual EDA Techniques
|
||||
|
||||
Visualizations are key in EDA for image datasets. For example, class imbalance analysis is another vital aspect of EDA. It helps determine if certain classes are underrepresented in your dataset, Visualizing the distribution of different image classes or categories using bar charts can quickly reveal any imbalances. Similarly, outliers can be identified using visualization tools like box plots, which highlight anomalies in pixel intensity or feature distributions. Outlier detection prevents unusual data points from skewing your results.
|
||||
|
||||
|
|
@ -131,9 +131,11 @@ For a more advanced approach to EDA, you can use the Ultralytics Explorer tool.
|
|||
Here are some questions that might come up while you prepare your dataset:
|
||||
|
||||
- **Q1:** How much preprocessing is too much?
|
||||
|
||||
- **A1:** Preprocessing is essential but should be balanced. Overdoing it can lead to loss of critical information, overfitting, increased complexity, and higher computational costs. Focus on necessary steps like resizing, normalization, and basic augmentation, adjusting based on model performance.
|
||||
|
||||
- **Q2:** What are the common pitfalls in EDA?
|
||||
|
||||
- **A2:** Common pitfalls in Exploratory Data Analysis (EDA) include ignoring data quality issues like missing values and outliers, confirmation bias, overfitting visualizations, neglecting data distribution, and overlooking correlations. A systematic approach helps gain accurate and valuable insights.
|
||||
|
||||
## Reach Out and Connect
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@ Queue management using [Ultralytics YOLOv8](https://github.com/ultralytics/ultra
|
|||
## Real World Applications
|
||||
|
||||
| Logistics | Retail |
|
||||
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
| 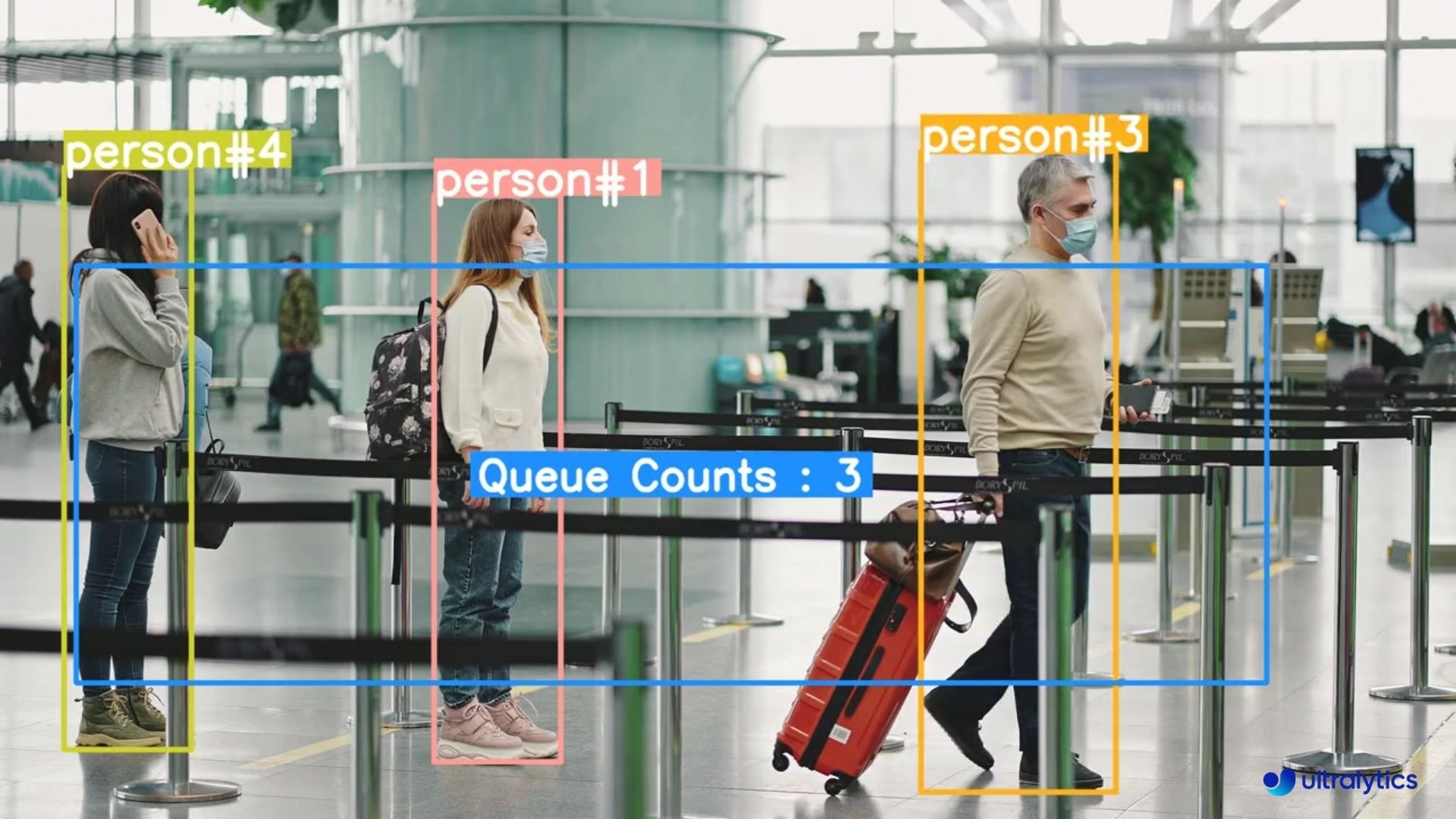 | 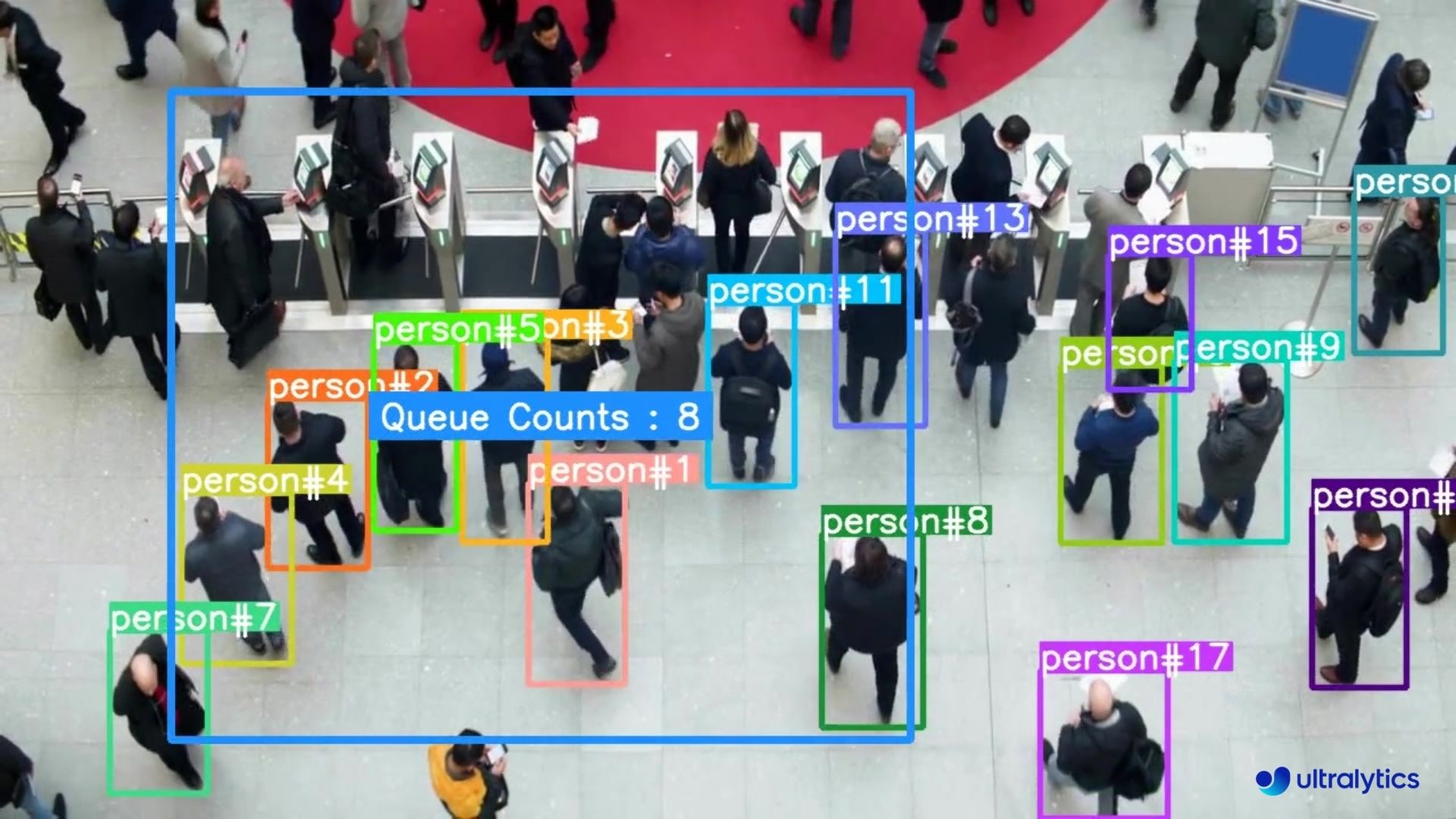 |
|
||||
| Queue management at airport ticket counter Using Ultralytics YOLOv8 | Queue monitoring in crowd Ultralytics YOLOv8 |
|
||||
|
||||
|
|
@ -115,7 +115,7 @@ Queue management using [Ultralytics YOLOv8](https://github.com/ultralytics/ultra
|
|||
### Arguments `QueueManager`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|---------------------|------------------|----------------------------|-------------------------------------------------------------------------------------|
|
||||
| ------------------- | ---------------- | -------------------------- | ----------------------------------------------------------------------------------- |
|
||||
| `classes_names` | `dict` | `model.names` | A dictionary mapping class IDs to class names. |
|
||||
| `reg_pts` | `list of tuples` | `[(20, 400), (1260, 400)]` | Points defining the counting region polygon. Defaults to a predefined rectangle. |
|
||||
| `line_thickness` | `int` | `2` | Thickness of the annotation lines. |
|
||||
|
|
@ -132,7 +132,7 @@ Queue management using [Ultralytics YOLOv8](https://github.com/ultralytics/ultra
|
|||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| --------- | ------- | -------------- | ----------------------------------------------------------- |
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
|
|
|
|||
|
|
@ -29,15 +29,15 @@ Raspberry Pi is a small, affordable, single-board computer. It has become popula
|
|||
|
||||
## Raspberry Pi Series Comparison
|
||||
|
||||
| | Raspberry Pi 3 | Raspberry Pi 4 | Raspberry Pi 5 |
|
||||
|-------------------|----------------------------------------|-----------------------------------------|-----------------------------------------|
|
||||
| CPU | Broadcom BCM2837, Cortex-A53 64Bit SoC | Broadcom BCM2711, Cortex-A72 64Bit SoC | Broadcom BCM2712, Cortex-A76 64Bit SoC |
|
||||
| CPU Max Frequency | 1.4GHz | 1.8GHz | 2.4GHz |
|
||||
| GPU | Videocore IV | Videocore VI | VideoCore VII |
|
||||
| GPU Max Frequency | 400Mhz | 500Mhz | 800Mhz |
|
||||
| Memory | 1GB LPDDR2 SDRAM | 1GB, 2GB, 4GB, 8GB LPDDR4-3200 SDRAM | 4GB, 8GB LPDDR4X-4267 SDRAM |
|
||||
| PCIe | N/A | N/A | 1xPCIe 2.0 Interface |
|
||||
| Max Power Draw | 2.5A@5V | 3A@5V | 5A@5V (PD enabled) |
|
||||
| | Raspberry Pi 3 | Raspberry Pi 4 | Raspberry Pi 5 |
|
||||
| ----------------- | -------------------------------------- | -------------------------------------- | -------------------------------------- |
|
||||
| CPU | Broadcom BCM2837, Cortex-A53 64Bit SoC | Broadcom BCM2711, Cortex-A72 64Bit SoC | Broadcom BCM2712, Cortex-A76 64Bit SoC |
|
||||
| CPU Max Frequency | 1.4GHz | 1.8GHz | 2.4GHz |
|
||||
| GPU | Videocore IV | Videocore VI | VideoCore VII |
|
||||
| GPU Max Frequency | 400Mhz | 500Mhz | 800Mhz |
|
||||
| Memory | 1GB LPDDR2 SDRAM | 1GB, 2GB, 4GB, 8GB LPDDR4-3200 SDRAM | 4GB, 8GB LPDDR4X-4267 SDRAM |
|
||||
| PCIe | N/A | N/A | 1xPCIe 2.0 Interface |
|
||||
| Max Power Draw | 2.5A@5V | 3A@5V | 5A@5V (PD enabled) |
|
||||
|
||||
## What is Raspberry Pi OS?
|
||||
|
||||
|
|
@ -190,7 +190,7 @@ The below table represents the benchmark results for two different models (YOLOv
|
|||
| TF Lite | ✅ | 42.8 | 0.7136 | 1013.27 |
|
||||
| PaddlePaddle | ✅ | 85.5 | 0.7136 | 1560.23 |
|
||||
| NCNN | ✅ | 42.7 | 0.7204 | 211.26 |
|
||||
|
||||
|
||||
=== "YOLOv8n on RPi4"
|
||||
|
||||
| Format | Status | Size on disk (MB) | mAP50-95(B) | Inference time (ms/im) |
|
||||
|
|
@ -267,7 +267,7 @@ rpicam-hello
|
|||
|
||||
!!! Tip
|
||||
|
||||
Learn more about [`rpicam-hello` usage on official Raspberry Pi documentation](https://www.raspberrypi.com/documentation/computers/camera_software.html#rpicam-hello)
|
||||
Learn more about [`rpicam-hello` usage on official Raspberry Pi documentation](https://www.raspberrypi.com/documentation/computers/camera_software.html#rpicam-hello)
|
||||
|
||||
### Inference with Camera
|
||||
|
||||
|
|
@ -329,7 +329,7 @@ There are 2 methods of using the Raspberry Pi Camera to inference YOLOv8 models.
|
|||
rpicam-vid -n -t 0 --inline --listen -o tcp://127.0.0.1:8888
|
||||
```
|
||||
|
||||
Learn more about [`rpicam-vid` usage on official Raspberry Pi documentation](https://www.raspberrypi.com/documentation/computers/camera_software.html#rpicam-vid)
|
||||
Learn more about [`rpicam-vid` usage on official Raspberry Pi documentation](https://www.raspberrypi.com/documentation/computers/camera_software.html#rpicam-vid)
|
||||
|
||||
!!! Example
|
||||
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ keywords: object counting, regions, YOLOv8, computer vision, Ultralytics, effici
|
|||
## Real World Applications
|
||||
|
||||
| Retail | Market Streets |
|
||||
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| :----------------------------------------------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
| 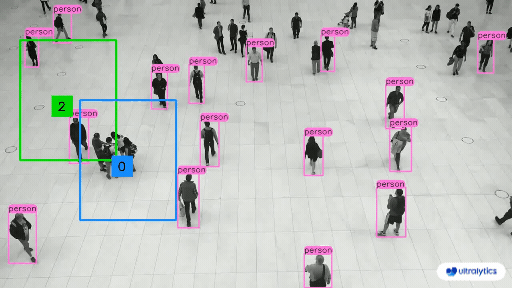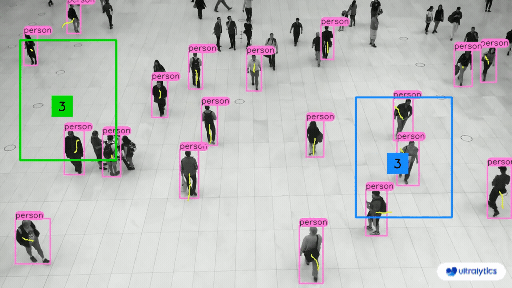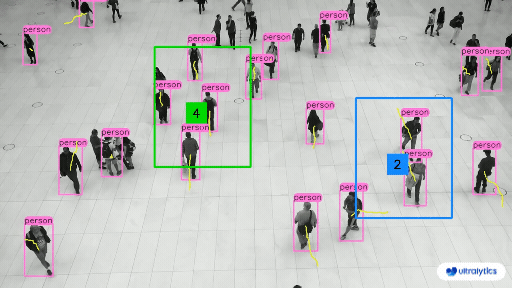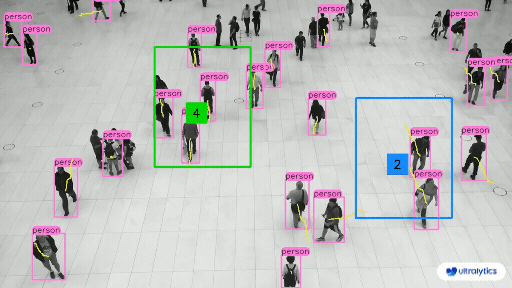 |  |
|
||||
| People Counting in Different Region using Ultralytics YOLOv8 | Crowd Counting in Different Region using Ultralytics YOLOv8 |
|
||||
|
||||
|
|
@ -76,7 +76,7 @@ python yolov8_region_counter.py --source "path/to/video.mp4" --view-img
|
|||
### Optional Arguments
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|----------------------|--------|--------------|--------------------------------------------|
|
||||
| -------------------- | ------ | ------------ | ------------------------------------------ |
|
||||
| `--source` | `str` | `None` | Path to video file, for webcam 0 |
|
||||
| `--line_thickness` | `int` | `2` | Bounding Box thickness |
|
||||
| `--save-img` | `bool` | `False` | Save the predicted video/image |
|
||||
|
|
|
|||
|
|
@ -34,7 +34,7 @@ keywords: Ultralytics YOLOv8, speed estimation, object tracking, computer vision
|
|||
## Real World Applications
|
||||
|
||||
| Transportation | Transportation |
|
||||
|:-------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
|  | 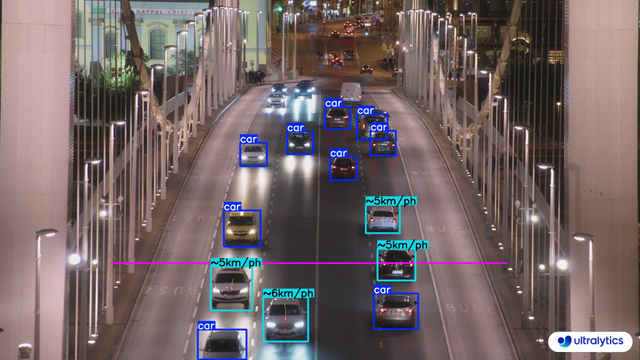 |
|
||||
| Speed Estimation on Road using Ultralytics YOLOv8 | Speed Estimation on Bridge using Ultralytics YOLOv8 |
|
||||
|
||||
|
|
@ -89,7 +89,7 @@ keywords: Ultralytics YOLOv8, speed estimation, object tracking, computer vision
|
|||
### Arguments `SpeedEstimator`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|--------------------|--------|----------------------------|------------------------------------------------------|
|
||||
| ------------------ | ------ | -------------------------- | ---------------------------------------------------- |
|
||||
| `names` | `dict` | `None` | Dictionary of class names. |
|
||||
| `reg_pts` | `list` | `[(20, 400), (1260, 400)]` | List of region points for speed estimation. |
|
||||
| `view_img` | `bool` | `False` | Whether to display the image with annotations. |
|
||||
|
|
@ -100,7 +100,7 @@ keywords: Ultralytics YOLOv8, speed estimation, object tracking, computer vision
|
|||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| --------- | ------- | -------------- | ----------------------------------------------------------- |
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
|
|
|
|||
|
|
@ -41,9 +41,11 @@ The first step in any computer vision project is clearly defining the problem yo
|
|||
Here are some examples of project objectives and the computer vision tasks that can be used to reach these objectives:
|
||||
|
||||
- **Objective:** To develop a system that can monitor and manage the flow of different vehicle types on highways, improving traffic management and safety.
|
||||
|
||||
- **Computer Vision Task:** Object detection is ideal for traffic monitoring because it efficiently locates and identifies multiple vehicles. It is less computationally demanding than image segmentation, which provides unnecessary detail for this task, ensuring faster, real-time analysis.
|
||||
|
||||
- **Objective:** To develop a tool that assists radiologists by providing precise, pixel-level outlines of tumors in medical imaging scans.
|
||||
|
||||
- **Computer Vision Task:** Image segmentation is suitable for medical imaging because it provides accurate and detailed boundaries of tumors that are crucial for assessing size, shape, and treatment planning.
|
||||
|
||||
- **Objective:** To create a digital system that categorizes various documents (e.g., invoices, receipts, legal paperwork) to improve organizational efficiency and document retrieval.
|
||||
|
|
@ -103,7 +105,7 @@ After splitting your data, you can perform data augmentation by applying transfo
|
|||
|
||||
<p align="center">
|
||||
<img width="100%" src="https://www.labellerr.com/blog/content/images/size/w2000/2022/11/banner-data-augmentation--1-.webp" alt="Examples of Data Augmentations">
|
||||
</p>
|
||||
</p>
|
||||
|
||||
Libraries like OpenCV, Albumentations, and TensorFlow offer flexible augmentation functions that you can use. Additionally, some libraries, such as Ultralytics, have [built-in augmentation settings](../modes/train.md) directly within its model training function, simplifying the process.
|
||||
|
||||
|
|
@ -111,7 +113,7 @@ To understand your data better, you can use tools like [Matplotlib](https://matp
|
|||
|
||||
<p align="center">
|
||||
<img width="100%" src="https://github.com/ultralytics/ultralytics/assets/15766192/feb1fe05-58c5-4173-a9ff-e611e3bba3d0" alt="The Ultralytics Explorer Tool">
|
||||
</p>
|
||||
</p>
|
||||
|
||||
By properly [understanding, splitting, and augmenting your data](./preprocessing_annotated_data.md), you can develop a well-trained, validated, and tested model that performs well in real-world applications.
|
||||
|
||||
|
|
@ -165,7 +167,7 @@ Monitoring tools can help you track key performance indicators (KPIs) and detect
|
|||
|
||||
<p align="center">
|
||||
<img width="100%" src="https://www.kdnuggets.com/wp-content/uploads//ai-infinite-training-maintaining-loop.jpg" alt="Model Monitoring">
|
||||
</p>
|
||||
</p>
|
||||
|
||||
In addition to monitoring and maintenance, documentation is also key. Thoroughly document the entire process, including model architecture, training procedures, hyperparameters, data preprocessing steps, and any changes made during deployment and maintenance. Good documentation ensures reproducibility and makes future updates or troubleshooting easier. By effectively monitoring, maintaining, and documenting your model, you can ensure it remains accurate, reliable, and easy to manage over its lifecycle.
|
||||
|
||||
|
|
@ -174,15 +176,19 @@ In addition to monitoring and maintenance, documentation is also key. Thoroughly
|
|||
Here are some common questions that might arise during a computer vision project:
|
||||
|
||||
- **Q1:** How do the steps change if I already have a dataset or data when starting a computer vision project?
|
||||
|
||||
- **A1:** Starting with a pre-existing dataset or data affects the initial steps of your project. In Step 1, along with deciding the computer vision task and model, you'll also need to explore your dataset thoroughly. Understanding its quality, variety, and limitations will guide your choice of model and training approach. Your approach should align closely with the data's characteristics for more effective outcomes. Depending on your data or dataset, you may be able to skip Step 2 as well.
|
||||
|
||||
- **Q2:** I'm not sure what computer vision project to start my AI learning journey with.
|
||||
- **A2:** Check out our [guides on Real-World Projects](./index.md) for inspiration and guidance.
|
||||
- **Q2:** I'm not sure what computer vision project to start my AI learning journey with.
|
||||
|
||||
- **A2:** Check out our [guides on Real-World Projects](./index.md) for inspiration and guidance.
|
||||
|
||||
- **Q3:** I don't want to train a model. I just want to try running a model on an image. How can I do that?
|
||||
|
||||
- **A3:** You can use a pre-trained model to run predictions on an image without training a new model. Check out the [YOLOv8 predict docs page](../modes/predict.md) for instructions on how to use a pre-trained YOLOv8 model to make predictions on your images.
|
||||
|
||||
- **Q4:** Where can I find more detailed articles and updates about computer vision applications and YOLOv8?
|
||||
|
||||
- **A4:** For more detailed articles, updates, and insights about computer vision applications and YOLOv8, visit the [Ultralytics blog page](https://www.ultralytics.com/blog). The blog covers a wide range of topics and provides valuable information to help you stay updated and improve your projects.
|
||||
|
||||
## Engaging with the Community
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ keywords: VisionEye, YOLOv8, Ultralytics, object mapping, object tracking, dista
|
|||
## Samples
|
||||
|
||||
| VisionEye View | VisionEye View With Object Tracking | VisionEye View With Distance Calculation |
|
||||
|:------------------------------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
||||
| :----------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
|  | 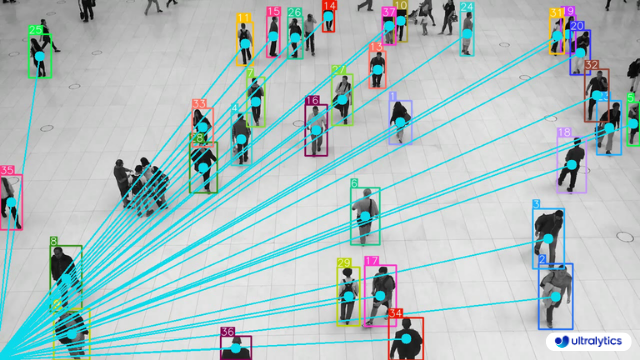 |  |
|
||||
| VisionEye View Object Mapping using Ultralytics YOLOv8 | VisionEye View Object Mapping with Object Tracking using Ultralytics YOLOv8 | VisionEye View with Distance Calculation using Ultralytics YOLOv8 |
|
||||
|
||||
|
|
@ -107,9 +107,9 @@ keywords: VisionEye, YOLOv8, Ultralytics, object mapping, object tracking, dista
|
|||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
|
||||
=== "VisionEye with Distance Calculation"
|
||||
|
||||
|
||||
```python
|
||||
import math
|
||||
|
||||
|
|
@ -170,7 +170,7 @@ keywords: VisionEye, YOLOv8, Ultralytics, object mapping, object tracking, dista
|
|||
### `visioneye` Arguments
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-------------|---------|------------------|--------------------------------|
|
||||
| ----------- | ------- | ---------------- | ------------------------------ |
|
||||
| `color` | `tuple` | `(235, 219, 11)` | Line and object centroid color |
|
||||
| `pin_color` | `tuple` | `(255, 0, 255)` | VisionEye pinpoint color |
|
||||
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ Monitoring workouts through pose estimation with [Ultralytics YOLOv8](https://gi
|
|||
## Real World Applications
|
||||
|
||||
| Workouts Monitoring | Workouts Monitoring |
|
||||
|:----------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------:|
|
||||
| :--------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------: |
|
||||
|  |  |
|
||||
| PushUps Counting | PullUps Counting |
|
||||
|
||||
|
|
@ -117,7 +117,7 @@ Monitoring workouts through pose estimation with [Ultralytics YOLOv8](https://gi
|
|||
### Arguments `AIGym`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-------------------|---------|----------|----------------------------------------------------------------------------------------|
|
||||
| ----------------- | ------- | -------- | -------------------------------------------------------------------------------------- |
|
||||
| `kpts_to_check` | `list` | `None` | List of three keypoints index, for counting specific workout, followed by keypoint Map |
|
||||
| `line_thickness` | `int` | `2` | Thickness of the lines drawn. |
|
||||
| `view_img` | `bool` | `False` | Flag to display the image. |
|
||||
|
|
@ -128,7 +128,7 @@ Monitoring workouts through pose estimation with [Ultralytics YOLOv8](https://gi
|
|||
### Arguments `model.predict`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------------|----------------|------------------------|----------------------------------------------------------------------------|
|
||||
| --------------- | -------------- | ---------------------- | -------------------------------------------------------------------------- |
|
||||
| `source` | `str` | `'ultralytics/assets'` | source directory for images or videos |
|
||||
| `conf` | `float` | `0.25` | object confidence threshold for detection |
|
||||
| `iou` | `float` | `0.7` | intersection over union (IoU) threshold for NMS |
|
||||
|
|
@ -148,7 +148,7 @@ Monitoring workouts through pose estimation with [Ultralytics YOLOv8](https://gi
|
|||
### Arguments `model.track`
|
||||
|
||||
| Name | Type | Default | Description |
|
||||
|-----------|---------|----------------|-------------------------------------------------------------|
|
||||
| --------- | ------- | -------------- | ----------------------------------------------------------- |
|
||||
| `source` | `im0` | `None` | source directory for images or videos |
|
||||
| `persist` | `bool` | `False` | persisting tracks between frames |
|
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' |
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue