Optimize Docs images (#15900)
Signed-off-by: UltralyticsAssistant <web@ultralytics.com> Co-authored-by: UltralyticsAssistant <web@ultralytics.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>
This commit is contained in:
parent
0f9f7b806c
commit
cfebb5f26b
174 changed files with 537 additions and 537 deletions
|
|
@ -21,7 +21,7 @@ The Fast Segment Anything Model (FastSAM) is a novel, real-time CNN-based soluti
|
|||
|
||||
## Model Architecture
|
||||
|
||||

|
||||

|
||||
|
||||
## Overview
|
||||
|
||||
|
|
|
|||
|
|
@ -53,9 +53,9 @@ Here is the comparison of the whole pipeline:
|
|||
|
||||
The performance of MobileSAM and the original SAM are demonstrated using both a point and a box as prompts.
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
With its superior performance, MobileSAM is approximately 5 times smaller and 7 times faster than the current FastSAM. More details are available at the [MobileSAM project page](https://github.com/ChaoningZhang/MobileSAM).
|
||||
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ Real-Time Detection Transformer (RT-DETR), developed by Baidu, is a cutting-edge
|
|||
<strong>Watch:</strong> Real-Time Detection Transformer (RT-DETR)
|
||||
</p>
|
||||
|
||||
 **Overview of Baidu's RT-DETR.** The RT-DETR model architecture diagram shows the last three stages of the backbone {S3, S4, S5} as the input to the encoder. The efficient hybrid encoder transforms multiscale features into a sequence of image features through intrascale feature interaction (AIFI) and cross-scale feature-fusion module (CCFM). The IoU-aware query selection is employed to select a fixed number of image features to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate boxes and confidence scores ([source](https://arxiv.org/pdf/2304.08069.pdf)).
|
||||
 **Overview of Baidu's RT-DETR.** The RT-DETR model architecture diagram shows the last three stages of the backbone {S3, S4, S5} as the input to the encoder. The efficient hybrid encoder transforms multiscale features into a sequence of image features through intrascale feature interaction (AIFI) and cross-scale feature-fusion module (CCFM). The IoU-aware query selection is employed to select a fixed number of image features to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate boxes and confidence scores ([source](https://arxiv.org/pdf/2304.08069.pdf)).
|
||||
|
||||
### Key Features
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: SAM 2, Segment Anything, video segmentation, image segmentation, promp
|
|||
|
||||
SAM 2, the successor to Meta's [Segment Anything Model (SAM)](sam.md), is a cutting-edge tool designed for comprehensive object segmentation in both images and videos. It excels in handling complex visual data through a unified, promptable model architecture that supports real-time processing and zero-shot generalization.
|
||||
|
||||

|
||||

|
||||
|
||||
## Key Features
|
||||
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ The Segment Anything Model, or SAM, is a cutting-edge image segmentation model t
|
|||
|
||||
SAM's advanced design allows it to adapt to new image distributions and tasks without prior knowledge, a feature known as zero-shot transfer. Trained on the expansive [SA-1B dataset](https://ai.facebook.com/datasets/segment-anything/), which contains more than 1 billion masks spread over 11 million carefully curated images, SAM has displayed impressive zero-shot performance, surpassing previous fully supervised results in many cases.
|
||||
|
||||
 **SA-1B Example images.** Dataset images overlaid masks from the newly introduced SA-1B dataset. SA-1B contains 11M diverse, high-resolution, licensed, and privacy protecting images and 1.1B high-quality segmentation masks. These masks were annotated fully automatically by SAM, and as verified by human ratings and numerous experiments, are of high quality and diversity. Images are grouped by number of masks per image for visualization (there are ∼100 masks per image on average).
|
||||
 **SA-1B Example images.** Dataset images overlaid masks from the newly introduced SA-1B dataset. SA-1B contains 11M diverse, high-resolution, licensed, and privacy protecting images and 1.1B high-quality segmentation masks. These masks were annotated fully automatically by SAM, and as verified by human ratings and numerous experiments, are of high quality and diversity. Images are grouped by number of masks per image for visualization (there are ∼100 masks per image on average).
|
||||
|
||||
## Key Features of the Segment Anything Model (SAM)
|
||||
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ keywords: YOLO-NAS, Deci AI, object detection, deep learning, Neural Architectur
|
|||
|
||||
Developed by Deci AI, YOLO-NAS is a groundbreaking object detection foundational model. It is the product of advanced Neural Architecture Search technology, meticulously designed to address the limitations of previous YOLO models. With significant improvements in quantization support and accuracy-latency trade-offs, YOLO-NAS represents a major leap in object detection.
|
||||
|
||||
 **Overview of YOLO-NAS.** YOLO-NAS employs quantization-aware blocks and selective quantization for optimal performance. The model, when converted to its INT8 quantized version, experiences a minimal precision drop, a significant improvement over other models. These advancements culminate in a superior architecture with unprecedented object detection capabilities and outstanding performance.
|
||||
 **Overview of YOLO-NAS.** YOLO-NAS employs quantization-aware blocks and selective quantization for optimal performance. The model, when converted to its INT8 quantized version, experiences a minimal precision drop, a significant improvement over other models. These advancements culminate in a superior architecture with unprecedented object detection capabilities and outstanding performance.
|
||||
|
||||
### Key Features
|
||||
|
||||
|
|
|
|||
|
|
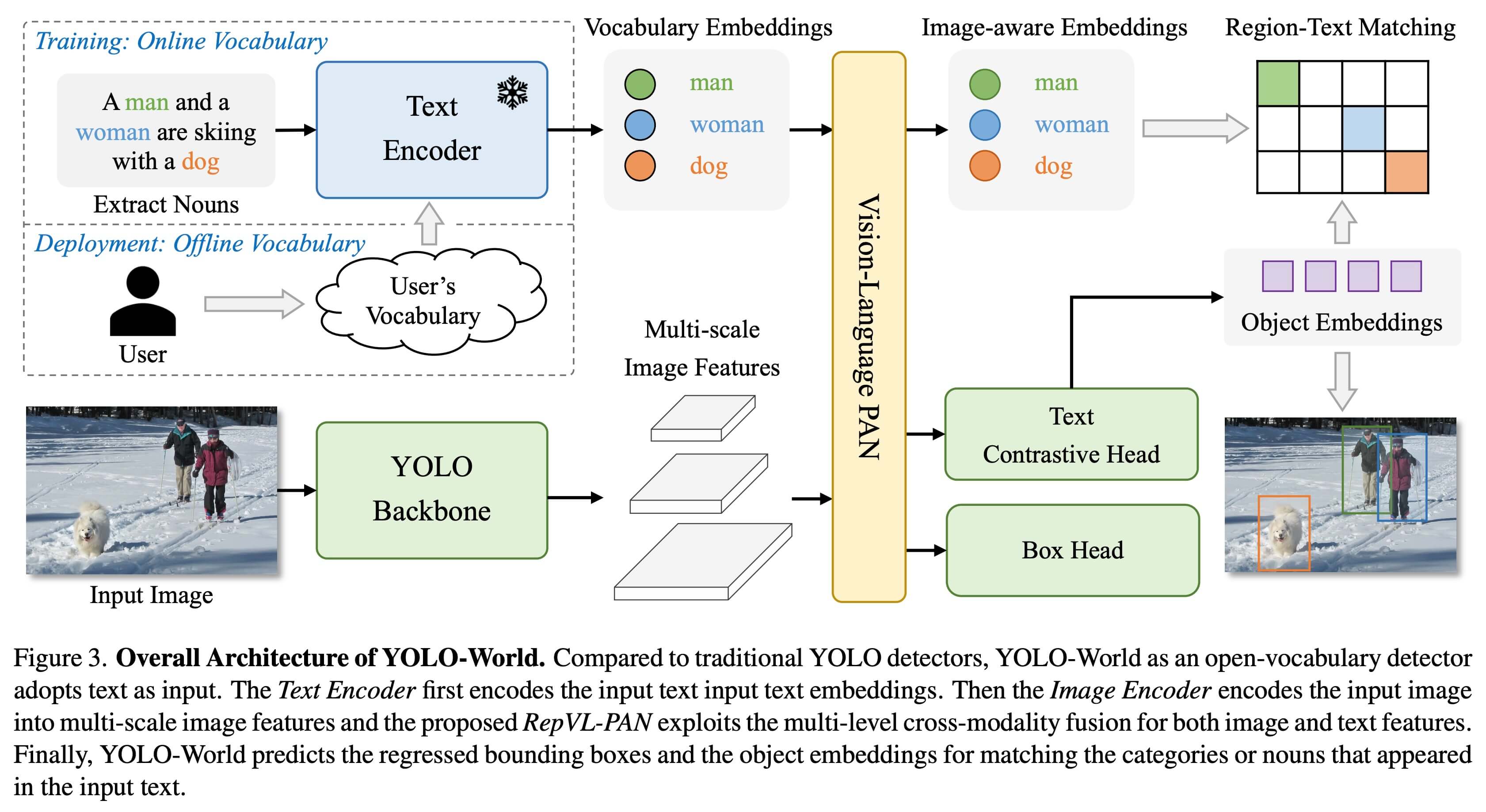
@ -19,7 +19,7 @@ The YOLO-World Model introduces an advanced, real-time [Ultralytics](https://ult
|
|||
<strong>Watch:</strong> YOLO World training workflow on custom dataset
|
||||
</p>
|
||||
|
||||
|
||||

|
||||
|
||||
## Overview
|
||||
|
||||
|
|
@ -195,7 +195,7 @@ Object tracking with YOLO-World model on a video/images is streamlined as follow
|
|||
|
||||
### Set prompts
|
||||
|
||||

|
||||

|
||||
|
||||
The YOLO-World framework allows for the dynamic specification of classes through custom prompts, empowering users to tailor the model to their specific needs **without retraining**. This feature is particularly useful for adapting the model to new domains or specific tasks that were not originally part of the training data. By setting custom prompts, users can essentially guide the model's focus towards objects of interest, enhancing the relevance and accuracy of the detection results.
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: YOLOv10, real-time object detection, NMS-free, deep learning, Tsinghua
|
|||
|
||||
YOLOv10, built on the [Ultralytics](https://ultralytics.com) [Python package](https://pypi.org/project/ultralytics/) by researchers at [Tsinghua University](https://www.tsinghua.edu.cn/en/), introduces a new approach to real-time object detection, addressing both the post-processing and model architecture deficiencies found in previous YOLO versions. By eliminating non-maximum suppression (NMS) and optimizing various model components, YOLOv10 achieves state-of-the-art performance with significantly reduced computational overhead. Extensive experiments demonstrate its superior accuracy-latency trade-offs across multiple model scales.
|
||||
|
||||

|
||||

|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
|
|
@ -91,7 +91,7 @@ YOLOv10 has been extensively tested on standard benchmarks like COCO, demonstrat
|
|||
|
||||
## Comparisons
|
||||
|
||||

|
||||

|
||||
|
||||
Compared to other state-of-the-art detectors:
|
||||
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ This document presents an overview of three closely related object detection mod
|
|||
|
||||
3. **YOLOv3u:** This is an updated version of YOLOv3-Ultralytics that incorporates the anchor-free, objectness-free split head used in YOLOv8 models. YOLOv3u maintains the same backbone and neck architecture as YOLOv3 but with the updated detection head from YOLOv8.
|
||||
|
||||

|
||||

|
||||
|
||||
## Key Features
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: YOLOv4, object detection, real-time detection, Alexey Bochkovskiy, neu
|
|||
|
||||
Welcome to the Ultralytics documentation page for YOLOv4, a state-of-the-art, real-time object detector launched in 2020 by Alexey Bochkovskiy at [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet). YOLOv4 is designed to provide the optimal balance between speed and accuracy, making it an excellent choice for many applications.
|
||||
|
||||
 **YOLOv4 architecture diagram**. Showcasing the intricate network design of YOLOv4, including the backbone, neck, and head components, and their interconnected layers for optimal real-time object detection.
|
||||
 **YOLOv4 architecture diagram**. Showcasing the intricate network design of YOLOv4, including the backbone, neck, and head components, and their interconnected layers for optimal real-time object detection.
|
||||
|
||||
## Introduction
|
||||
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ keywords: YOLOv5, YOLOv5u, object detection, Ultralytics, anchor-free, pre-train
|
|||
|
||||
YOLOv5u represents an advancement in object detection methodologies. Originating from the foundational architecture of the [YOLOv5](https://github.com/ultralytics/yolov5) model developed by Ultralytics, YOLOv5u integrates the anchor-free, objectness-free split head, a feature previously introduced in the [YOLOv8](yolov8.md) models. This adaptation refines the model's architecture, leading to an improved accuracy-speed tradeoff in object detection tasks. Given the empirical results and its derived features, YOLOv5u provides an efficient alternative for those seeking robust solutions in both research and practical applications.
|
||||
|
||||

|
||||

|
||||
|
||||
## Key Features
|
||||
|
||||
|
|
|
|||
|
|
@ -10,8 +10,8 @@ keywords: Meituan YOLOv6, object detection, real-time applications, BiC module,
|
|||
|
||||
[Meituan](https://about.meituan.com/) YOLOv6 is a cutting-edge object detector that offers remarkable balance between speed and accuracy, making it a popular choice for real-time applications. This model introduces several notable enhancements on its architecture and training scheme, including the implementation of a Bi-directional Concatenation (BiC) module, an anchor-aided training (AAT) strategy, and an improved backbone and neck design for state-of-the-art accuracy on the COCO dataset.
|
||||
|
||||

|
||||
 **Overview of YOLOv6.** Model architecture diagram showing the redesigned network components and training strategies that have led to significant performance improvements. (a) The neck of YOLOv6 (N and S are shown). Note for M/L, RepBlocks is replaced with CSPStackRep. (b) The structure of a BiC module. (c) A SimCSPSPPF block. ([source](https://arxiv.org/pdf/2301.05586.pdf)).
|
||||

|
||||
 **Overview of YOLOv6.** Model architecture diagram showing the redesigned network components and training strategies that have led to significant performance improvements. (a) The neck of YOLOv6 (N and S are shown). Note for M/L, RepBlocks is replaced with CSPStackRep. (b) The structure of a BiC module. (c) A SimCSPSPPF block. ([source](https://arxiv.org/pdf/2301.05586.pdf)).
|
||||
|
||||
### Key Features
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: YOLOv7, real-time object detection, Ultralytics, AI, computer vision,
|
|||
|
||||
YOLOv7 is a state-of-the-art real-time object detector that surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS. It has the highest accuracy (56.8% AP) among all known real-time object detectors with 30 FPS or higher on GPU V100. Moreover, YOLOv7 outperforms other object detectors such as YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, and many others in speed and accuracy. The model is trained on the MS COCO dataset from scratch without using any other datasets or pre-trained weights. Source code for YOLOv7 is available on GitHub.
|
||||
|
||||

|
||||

|
||||
|
||||
## Comparison of SOTA object detectors
|
||||
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ keywords: YOLOv8, real-time object detection, YOLO series, Ultralytics, computer
|
|||
|
||||
YOLOv8 is the latest iteration in the YOLO series of real-time object detectors, offering cutting-edge performance in terms of accuracy and speed. Building upon the advancements of previous YOLO versions, YOLOv8 introduces new features and optimizations that make it an ideal choice for various object detection tasks in a wide range of applications.
|
||||
|
||||

|
||||

|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
|
|
|
|||
|
|
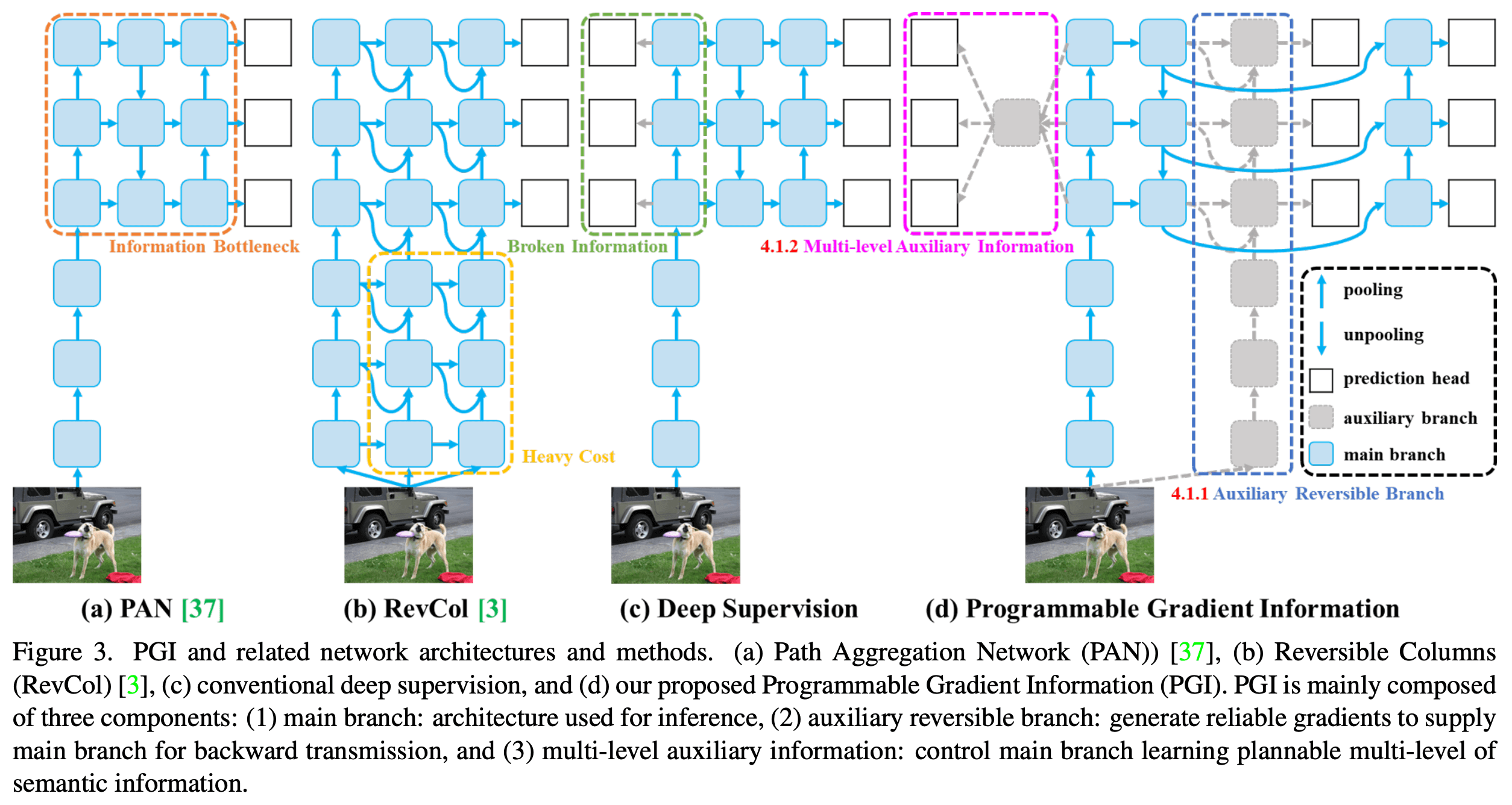
@ -19,7 +19,7 @@ YOLOv9 marks a significant advancement in real-time object detection, introducin
|
|||
<strong>Watch:</strong> YOLOv9 Training on Custom Data using Ultralytics | Industrial Package Dataset
|
||||
</p>
|
||||
|
||||
|
||||

|
||||
|
||||
## Introduction to YOLOv9
|
||||
|
||||
|
|
@ -61,7 +61,7 @@ PGI is a novel concept introduced in YOLOv9 to combat the information bottleneck
|
|||
|
||||
GELAN represents a strategic architectural advancement, enabling YOLOv9 to achieve superior parameter utilization and computational efficiency. Its design allows for flexible integration of various computational blocks, making YOLOv9 adaptable to a wide range of applications without sacrificing speed or accuracy.
|
||||
|
||||

|
||||

|
||||
|
||||
## YOLOv9 Benchmarks
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue