Optimize Docs images (#15900)
Signed-off-by: UltralyticsAssistant <web@ultralytics.com> Co-authored-by: UltralyticsAssistant <web@ultralytics.com> Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>
This commit is contained in:
parent
0f9f7b806c
commit
cfebb5f26b
174 changed files with 537 additions and 537 deletions
|
|
@ -91,7 +91,7 @@ To train a YOLOv8n model on the African wildlife dataset for 100 epochs with an
|
|||
|
||||
The African wildlife dataset comprises a wide variety of images showcasing diverse animal species and their natural habitats. Below are examples of images from the dataset, each accompanied by its corresponding annotations.
|
||||
|
||||

|
||||

|
||||
|
||||
- **Mosaiced Image**: Here, we present a training batch consisting of mosaiced dataset images. Mosaicing, a training technique, combines multiple images into one, enriching batch diversity. This method helps enhance the model's ability to generalize across different object sizes, aspect ratios, and contexts.
|
||||
|
||||
|
|
|
|||
|
|
@ -70,7 +70,7 @@ To train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image s
|
|||
|
||||
The Argoverse dataset contains a diverse set of sensor data, including camera images, LiDAR point clouds, and HD map information, providing rich context for autonomous driving tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Argoverse 3D Tracking**: This image demonstrates an example of 3D object tracking, where objects are annotated with 3D bounding boxes. The dataset provides LiDAR point clouds and camera images to facilitate the development of models for this task.
|
||||
|
||||
|
|
|
|||
|
|
@ -90,7 +90,7 @@ To train a YOLOv8n model on the brain tumor dataset for 100 epochs with an image
|
|||
|
||||
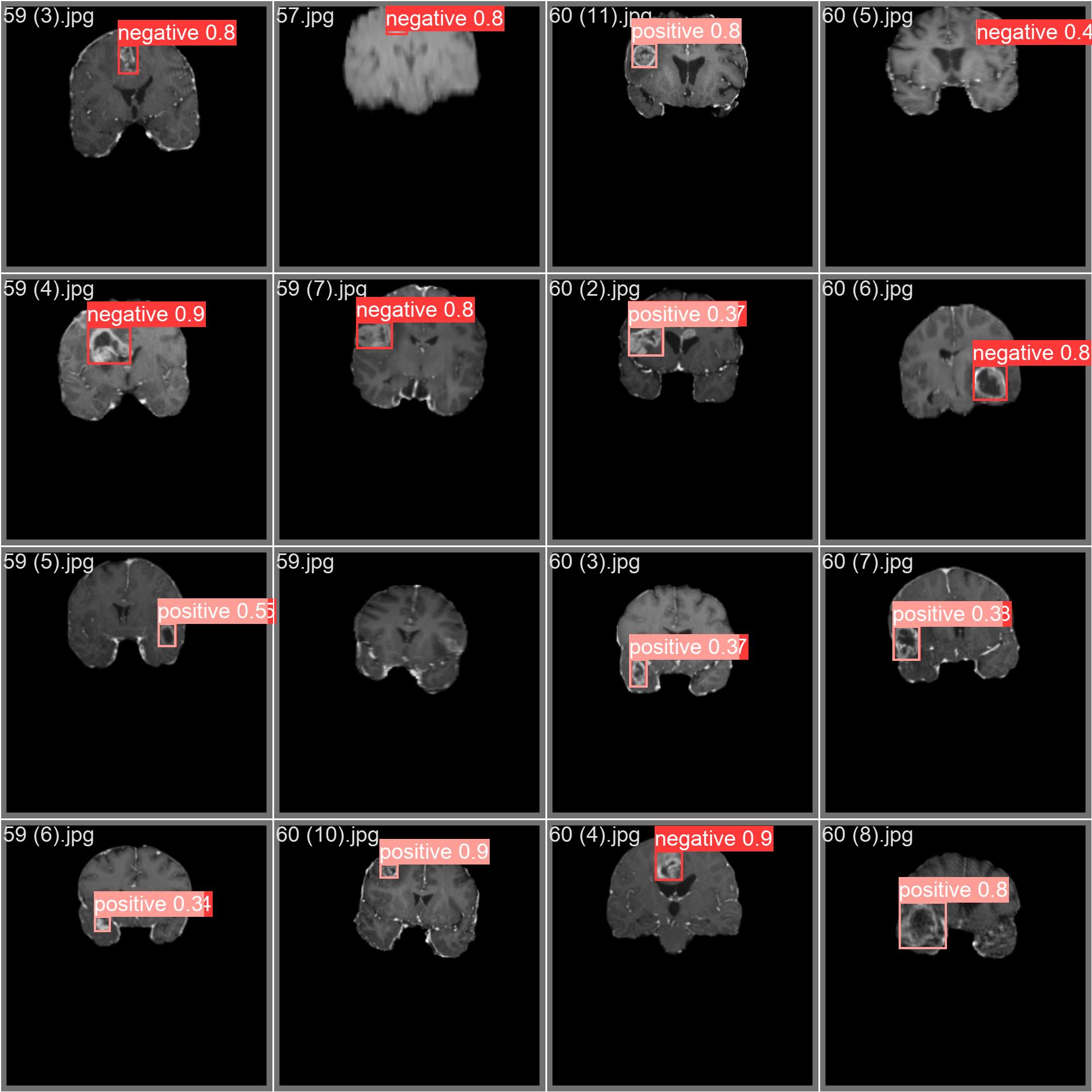
The brain tumor dataset encompasses a wide array of images featuring diverse object categories and intricate scenes. Presented below are examples of images from the dataset, accompanied by their respective annotations
|
||||
|
||||
|
||||

|
||||
|
||||
- **Mosaiced Image**: Displayed here is a training batch comprising mosaiced dataset images. Mosaicing, a training technique, consolidates multiple images into one, enhancing batch diversity. This approach aids in improving the model's capacity to generalize across various object sizes, aspect ratios, and contexts.
|
||||
|
||||
|
|
|
|||
|
|
@ -87,7 +87,7 @@ To train a YOLOv8n model on the COCO dataset for 100 epochs with an image size o
|
|||
|
||||
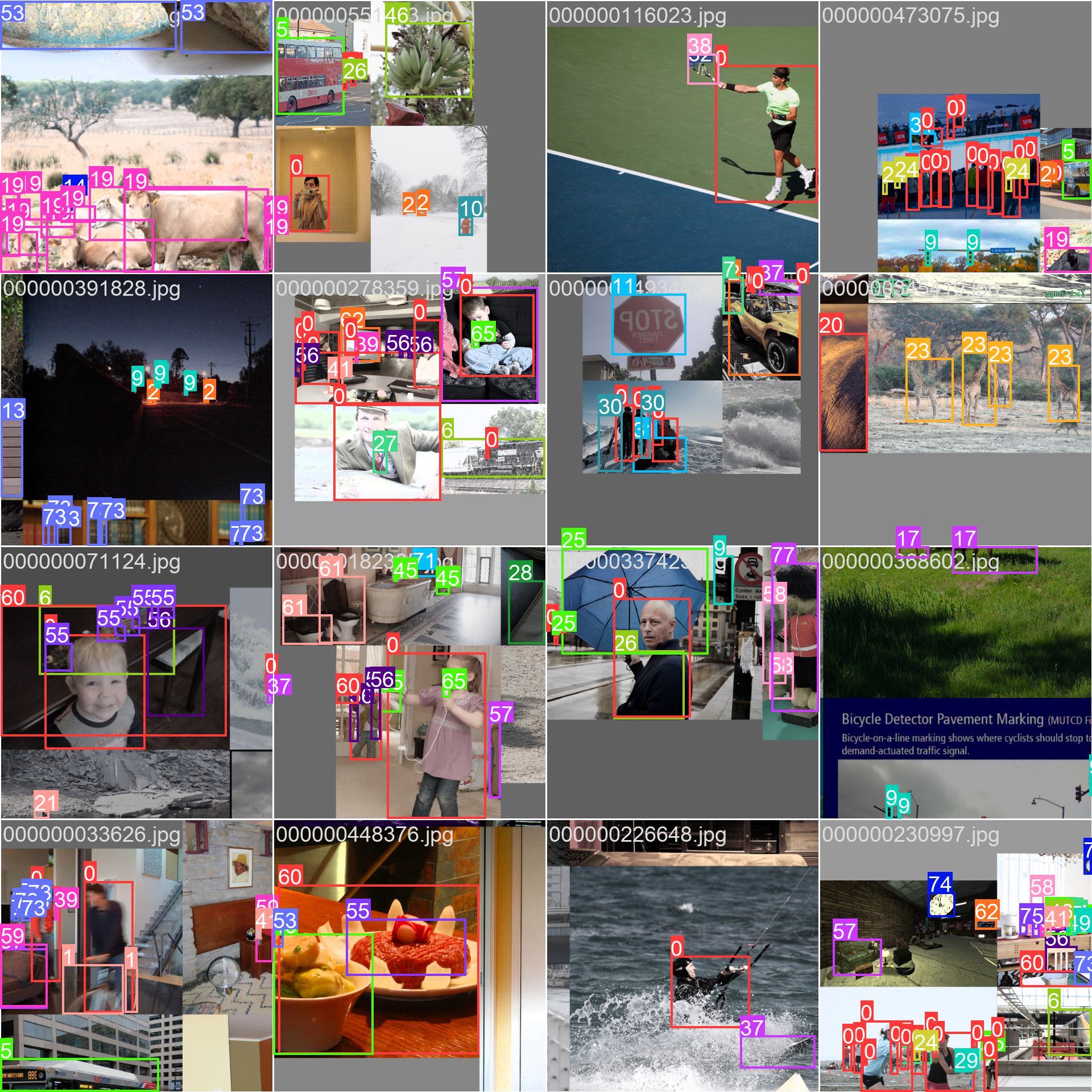
The COCO dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
||||
|
||||
|
||||

|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
|
|
|
|||
|
|
@ -62,7 +62,7 @@ To train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size
|
|||
|
||||
Here are some examples of images from the COCO8 dataset, along with their corresponding annotations:
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/236818348-e6260a3d-0454-436b-83a9-de366ba07235.jpg" alt="Dataset sample image" width="800">
|
||||
<img src="https://github.com/ultralytics/docs/releases/download/0/mosaiced-training-batch-1.avif" alt="Dataset sample image" width="800">
|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
|
|
|
|||
|
|
@ -65,7 +65,7 @@ To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an
|
|||
|
||||
The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
|
||||
|
||||
|
|
|
|||
|
|
@ -34,15 +34,15 @@ names:
|
|||
|
||||
Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
|
||||
|
||||
<p align="center"><img width="750" src="https://user-images.githubusercontent.com/26833433/91506361-c7965000-e886-11ea-8291-c72b98c25eec.jpg" alt="Example labelled image"></p>
|
||||
<p align="center"><img width="750" src="https://github.com/ultralytics/docs/releases/download/0/two-persons-tie.avif" alt="Example labelled image"></p>
|
||||
|
||||
The label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):
|
||||
|
||||
<p align="center"><img width="428" src="https://user-images.githubusercontent.com/26833433/112467037-d2568c00-8d66-11eb-8796-55402ac0d62f.png" alt="Example label file"></p>
|
||||
<p align="center"><img width="428" src="https://github.com/ultralytics/docs/releases/download/0/two-persons-tie-1.avif" alt="Example label file"></p>
|
||||
|
||||
When using the Ultralytics YOLO format, organize your training and validation images and labels as shown in the [COCO8 dataset](coco8.md) example below.
|
||||
|
||||
<p align="center"><img width="800" src="https://github.com/IvorZhu331/ultralytics/assets/26833433/a55ec82d-2bb5-40f9-ac5c-f935e7eb9f07" alt="Example dataset directory structure"></p>
|
||||
<p align="center"><img width="800" src="https://github.com/ultralytics/docs/releases/download/0/two-persons-tie-2.avif" alt="Example dataset directory structure"></p>
|
||||
|
||||
## Usage
|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale, fine-grained
|
|||
</p>
|
||||
|
||||
<p align="center">
|
||||
<img width="640" src="https://github.com/ultralytics/ultralytics/assets/26833433/40230a80-e7bc-4310-a860-4cc0ef4bb02a" alt="LVIS Dataset example images">
|
||||
<img width="640" src="https://github.com/ultralytics/docs/releases/download/0/lvis-dataset-example-images.avif" alt="LVIS Dataset example images">
|
||||
</p>
|
||||
|
||||
## Key Features
|
||||
|
|
@ -83,7 +83,7 @@ To train a YOLOv8n model on the LVIS dataset for 100 epochs with an image size o
|
|||
|
||||
The LVIS dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
|
|
@ -154,6 +154,6 @@ Ultralytics YOLO models, including the latest YOLOv8, are optimized for real-tim
|
|||
|
||||
Yes, the LVIS dataset includes a variety of images with diverse object categories and complex scenes. Here is an example of a sample image along with its annotations:
|
||||
|
||||

|
||||

|
||||
|
||||
This mosaiced image demonstrates a training batch composed of multiple dataset images combined into one. Mosaicing increases the variety of objects and scenes within each training batch, enhancing the model's ability to generalize across different contexts. For more details on the LVIS dataset, explore the [LVIS dataset documentation](#key-features).
|
||||
|
|
|
|||
|
|
@ -65,7 +65,7 @@ To train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image
|
|||
|
||||
The Objects365 dataset contains a diverse set of high-resolution images with objects from 365 categories, providing rich context for object detection tasks. Here are some examples of the images in the dataset:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Objects365**: This image demonstrates an example of object detection, where objects are annotated with bounding boxes. The dataset provides a wide range of images to facilitate the development of models for this task.
|
||||
|
||||
|
|
|
|||
|
|
@ -29,7 +29,7 @@ keywords: Open Images V7, Google dataset, computer vision, YOLOv8 models, object
|
|||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8l-oiv7.pt) | 640 | 34.9 | 596.9 | 2.43 | 44.1 | 167.4 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8x-oiv7.pt) | 640 | 36.3 | 860.6 | 3.56 | 68.7 | 260.6 |
|
||||
|
||||

|
||||

|
||||
|
||||
## Key Features
|
||||
|
||||
|
|
@ -105,7 +105,7 @@ To train a YOLOv8n model on the Open Images V7 dataset for 100 epochs with an im
|
|||
|
||||
Illustrations of the dataset help provide insights into its richness:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Open Images V7**: This image exemplifies the depth and detail of annotations available, including bounding boxes, relationships, and segmentation masks.
|
||||
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ keywords: Roboflow 100, Ultralytics, object detection, dataset, benchmarking, ma
|
|||
Roboflow 100, developed by [Roboflow](https://roboflow.com/?ref=ultralytics) and sponsored by Intel, is a groundbreaking [object detection](../../tasks/detect.md) benchmark. It includes 100 diverse datasets sampled from over 90,000 public datasets. This benchmark is designed to test the adaptability of models to various domains, including healthcare, aerial imagery, and video games.
|
||||
|
||||
<p align="center">
|
||||
<img width="640" src="https://user-images.githubusercontent.com/15908060/202452898-9ca6b8f7-4805-4e8e-949a-6e080d7b94d2.jpg" alt="Roboflow 100 Overview">
|
||||
<img width="640" src="https://github.com/ultralytics/docs/releases/download/0/roboflow-100-overview.avif" alt="Roboflow 100 Overview">
|
||||
</p>
|
||||
|
||||
## Key Features
|
||||
|
|
@ -104,7 +104,7 @@ You can access it directly from the Roboflow 100 GitHub repository. In addition,
|
|||
Roboflow 100 consists of datasets with diverse images and videos captured from various angles and domains. Here's a look at examples of annotated images in the RF100 benchmark.
|
||||
|
||||
<p align="center">
|
||||
<img width="640" src="https://blog.roboflow.com/content/images/2022/11/image-2.png" alt="Sample Data and Annotations">
|
||||
<img width="640" src="https://github.com/ultralytics/docs/releases/download/0/sample-data-annotations.avif" alt="Sample Data and Annotations">
|
||||
</p>
|
||||
|
||||
The diversity in the Roboflow 100 benchmark that can be seen above is a significant advancement from traditional benchmarks which often focus on optimizing a single metric within a limited domain.
|
||||
|
|
|
|||
|
|
@ -79,7 +79,7 @@ To train a YOLOv8n model on the signature detection dataset for 100 epochs with
|
|||
|
||||
The signature detection dataset comprises a wide variety of images showcasing different document types and annotated signatures. Below are examples of images from the dataset, each accompanied by its corresponding annotations.
|
||||
|
||||

|
||||

|
||||
|
||||
- **Mosaiced Image**: Here, we present a training batch consisting of mosaiced dataset images. Mosaicing, a training technique, combines multiple images into one, enriching batch diversity. This method helps enhance the model's ability to generalize across different signature sizes, aspect ratios, and contexts.
|
||||
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ The [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection
|
|||
<strong>Watch:</strong> How to Train YOLOv10 on SKU-110k Dataset using Ultralytics | Retail Dataset
|
||||
</p>
|
||||
|
||||

|
||||

|
||||
|
||||
## Key Features
|
||||
|
||||
|
|
@ -78,7 +78,7 @@ To train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image si
|
|||
|
||||
The SKU-110k dataset contains a diverse set of retail shelf images with densely packed objects, providing rich context for object detection tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Densely packed retail shelf image**: This image demonstrates an example of densely packed objects in a retail shelf setting. Objects are annotated with bounding boxes and SKU category labels.
|
||||
|
||||
|
|
|
|||
|
|
@ -74,7 +74,7 @@ To train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image si
|
|||
|
||||
The VisDrone dataset contains a diverse set of images and videos captured by drone-mounted cameras. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Task 1**: Object detection in images - This image demonstrates an example of object detection in images, where objects are annotated with bounding boxes. The dataset provides a wide variety of images taken from different locations, environments, and densities to facilitate the development of models for this task.
|
||||
|
||||
|
|
|
|||
|
|
@ -66,7 +66,7 @@ To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of
|
|||
|
||||
The VOC dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
|
|
|
|||
|
|
@ -69,7 +69,7 @@ To train a model on the xView dataset for 100 epochs with an image size of 640,
|
|||
|
||||
The xView dataset contains high-resolution satellite images with a diverse set of objects annotated using bounding boxes. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||

|
||||
|
||||
- **Overhead Imagery**: This image demonstrates an example of object detection in overhead imagery, where objects are annotated with bounding boxes. The dataset provides high-resolution satellite images to facilitate the development of models for this task.
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue