Add https://youtu.be/cfTKj96TjSE to docs (#11190)
This commit is contained in:
parent
9e0c13610f
commit
835100163e
2 changed files with 22 additions and 0 deletions
|
|
@ -8,6 +8,17 @@ keywords: Ultralytics, LVIS dataset, object detection, YOLO, YOLO model training
|
|||
|
||||
The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale, fine-grained vocabulary-level annotation dataset developed and released by Facebook AI Research (FAIR). It is primarily used as a research benchmark for object detection and instance segmentation with a large vocabulary of categories, aiming to drive further advancements in computer vision field.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/cfTKj96TjSE"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> YOLO World training workflow with LVIS dataset
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<img width="640" src="https://github.com/ultralytics/ultralytics/assets/26833433/40230a80-e7bc-4310-a860-4cc0ef4bb02a" alt="LVIS Dataset example images">
|
||||
</p>
|
||||
|
|
|
|||
|
|
@ -10,6 +10,17 @@ The YOLO-World Model introduces an advanced, real-time [Ultralytics](https://ult
|
|||
|
||||
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/cfTKj96TjSE"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> YOLO World training workflow on custom dataset
|
||||
</p>
|
||||
|
||||
## Overview
|
||||
|
||||
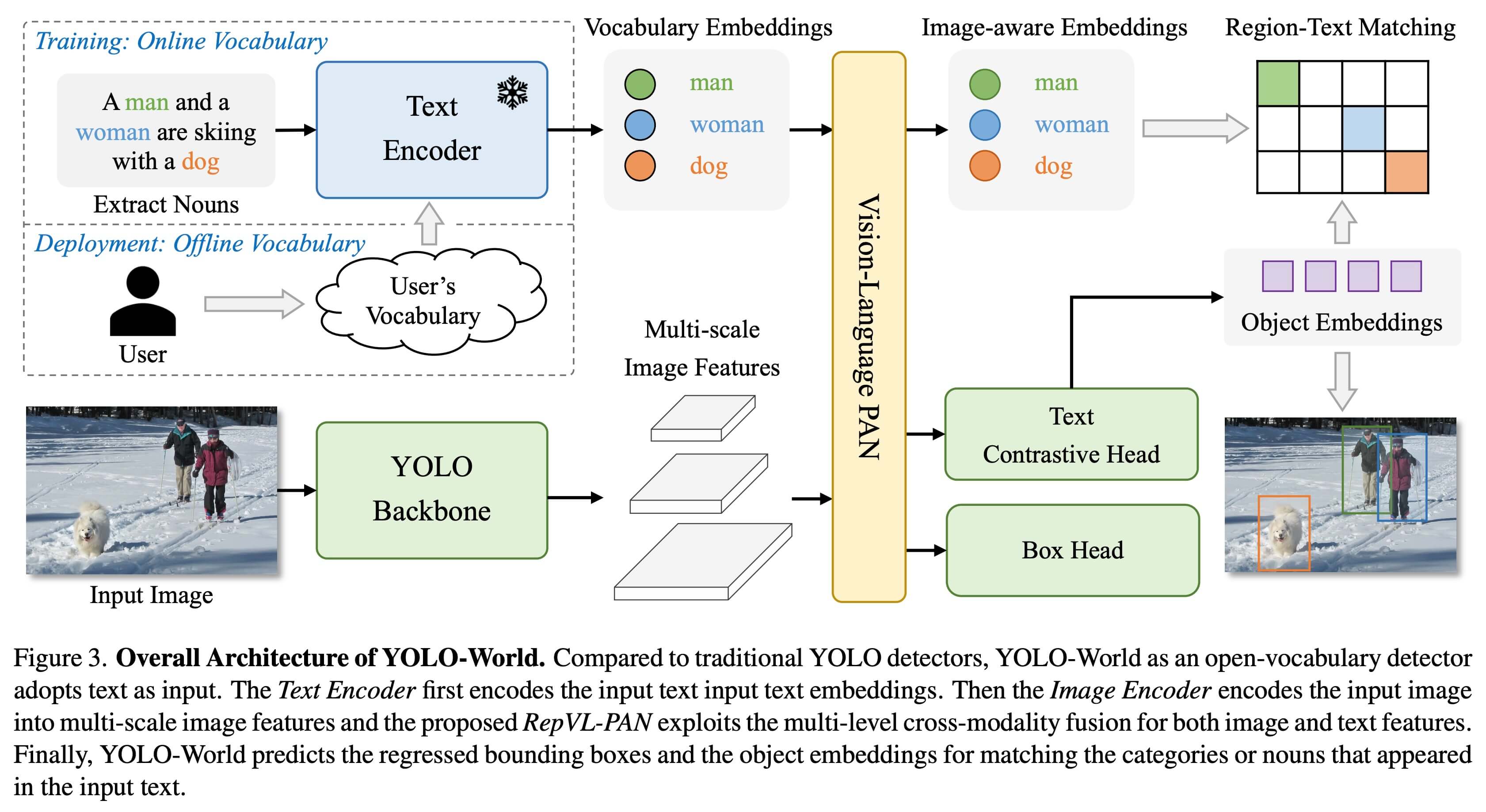
YOLO-World tackles the challenges faced by traditional Open-Vocabulary detection models, which often rely on cumbersome Transformer models requiring extensive computational resources. These models' dependence on pre-defined object categories also restricts their utility in dynamic scenarios. YOLO-World revitalizes the YOLOv8 framework with open-vocabulary detection capabilities, employing vision-language modeling and pre-training on expansive datasets to excel at identifying a broad array of objects in zero-shot scenarios with unmatched efficiency.
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue