diff --git a/docs/en/datasets/detect/lvis.md b/docs/en/datasets/detect/lvis.md
index 2ddf49d9..21c51df3 100644
--- a/docs/en/datasets/detect/lvis.md
+++ b/docs/en/datasets/detect/lvis.md
@@ -8,6 +8,17 @@ keywords: Ultralytics, LVIS dataset, object detection, YOLO, YOLO model training
The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale, fine-grained vocabulary-level annotation dataset developed and released by Facebook AI Research (FAIR). It is primarily used as a research benchmark for object detection and instance segmentation with a large vocabulary of categories, aiming to drive further advancements in computer vision field.
+
+
+
+
+ Watch: YOLO World training workflow with LVIS dataset
+
+
diff --git a/docs/en/models/yolo-world.md b/docs/en/models/yolo-world.md
index 93e78cee..4477471b 100644
--- a/docs/en/models/yolo-world.md
+++ b/docs/en/models/yolo-world.md
@@ -10,6 +10,17 @@ The YOLO-World Model introduces an advanced, real-time [Ultralytics](https://ult
+
+
+
+
+ Watch: YOLO World training workflow on custom dataset
+
+
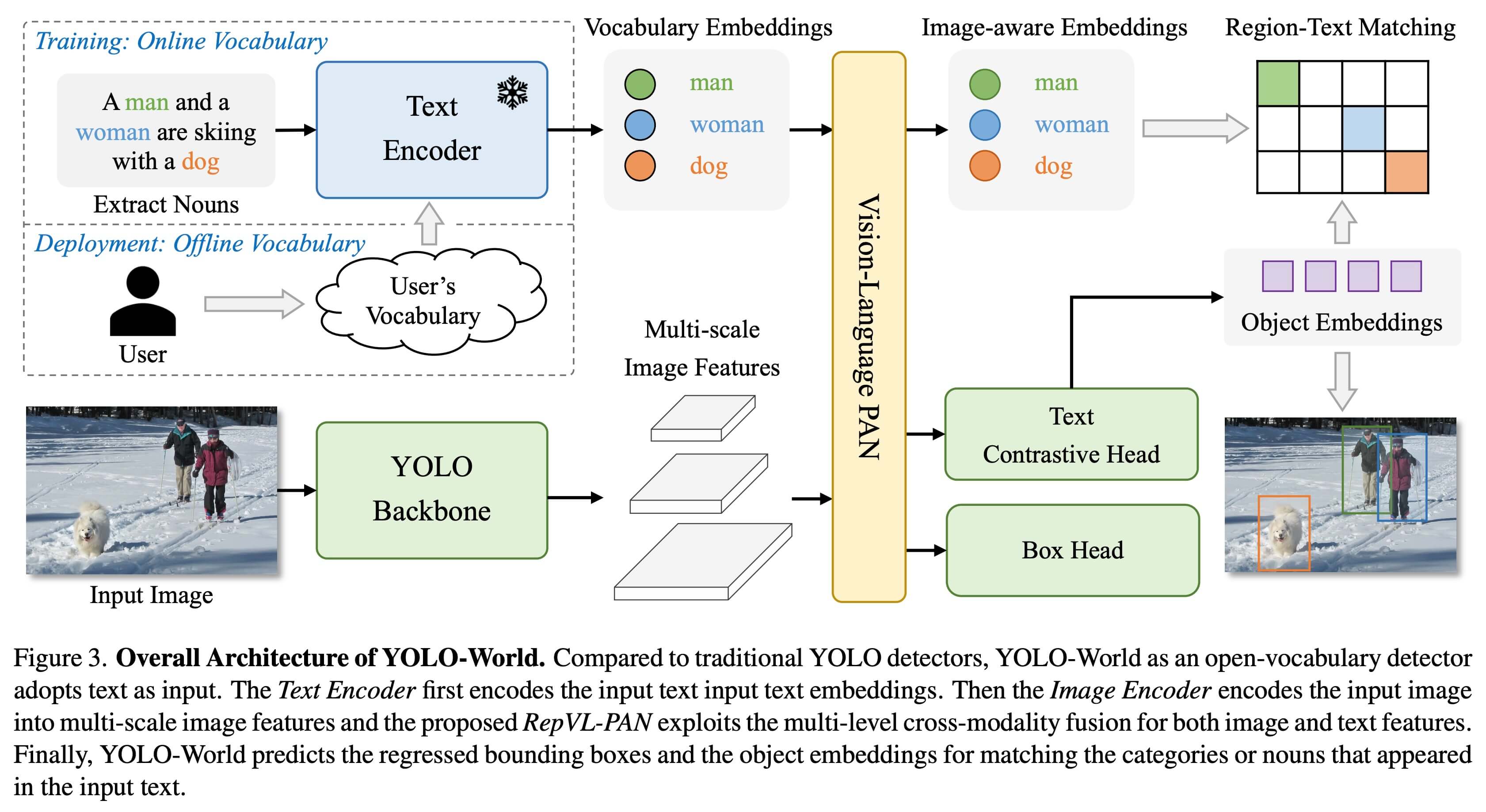
## Overview
YOLO-World tackles the challenges faced by traditional Open-Vocabulary detection models, which often rely on cumbersome Transformer models requiring extensive computational resources. These models' dependence on pre-defined object categories also restricts their utility in dynamic scenarios. YOLO-World revitalizes the YOLOv8 framework with open-vocabulary detection capabilities, employing vision-language modeling and pre-training on expansive datasets to excel at identifying a broad array of objects in zero-shot scenarios with unmatched efficiency.