Add missing HTML image alt tags (#6611)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com>
This commit is contained in:
parent
4096b261fc
commit
42bcf8c47f
39 changed files with 267 additions and 245 deletions
|
|
@ -165,7 +165,7 @@ The YOLOv5 architecture makes some important changes to the box prediction strat
|
|||

|
||||

|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508027-8bf63c28-8290-467b-8a3e-4ad09235001a.png#pic_center" width=40%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508027-8bf63c28-8290-467b-8a3e-4ad09235001a.png#pic_center" width=40% alt="YOLOv5 grid computation">
|
||||
|
||||
However, in YOLOv5, the formula for predicting the box coordinates has been updated to reduce grid sensitivity and prevent the model from predicting unbounded box dimensions.
|
||||
|
||||
|
|
@ -178,11 +178,11 @@ The revised formulas for calculating the predicted bounding box are as follows:
|
|||
|
||||
Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5). Therefore, offset can easily get 0 or 1.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508052-c24bc5e8-05c1-4154-ac97-2e1ec71f582e.png#pic_center" width=40%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508052-c24bc5e8-05c1-4154-ac97-2e1ec71f582e.png#pic_center" width=40% alt="YOLOv5 grid scaling">
|
||||
|
||||
Compare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. [refer this issue](https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779)
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508089-5ac0c7a3-6358-44b7-863e-a6e45babb842.png#pic_center" width=40%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508089-5ac0c7a3-6358-44b7-863e-a6e45babb842.png#pic_center" width=40% alt="YOLOv5 unbounded scaling">
|
||||
|
||||
### 4.4 Build Targets
|
||||
|
||||
|
|
@ -204,15 +204,15 @@ This process follows these steps:
|
|||
|
||||

|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508119-fbb2e483-7b8c-4975-8e1f-f510d367f8ff.png#pic_center" width=70%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508119-fbb2e483-7b8c-4975-8e1f-f510d367f8ff.png#pic_center" width=70% alt="YOLOv5 IoU computation">
|
||||
|
||||
- If the calculated ratio is within the threshold, match the ground truth box with the corresponding anchor.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508771-b6e7cab4-8de6-47f9-9abf-cdf14c275dfe.png#pic_center" width=70%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508771-b6e7cab4-8de6-47f9-9abf-cdf14c275dfe.png#pic_center" width=70% alt="YOLOv5 grid overlap">
|
||||
|
||||
- Assign the matched anchor to the appropriate cells, keeping in mind that due to the revised center point offset, a ground truth box can be assigned to more than one anchor. Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508139-9db4e8c2-cf96-47e0-bc80-35d11512f296.png#pic_center" width=70%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508139-9db4e8c2-cf96-47e0-bc80-35d11512f296.png#pic_center" width=70% alt="YOLOv5 anchor selection">
|
||||
|
||||
This way, the build targets process ensures that each ground truth object is properly assigned and matched during the training process, allowing YOLOv5 to learn the task of object detection more effectively.
|
||||
|
||||
|
|
|
|||
|
|
@ -22,15 +22,15 @@ keywords: ClearML, YOLOv5, Ultralytics, AI toolbox, training data, remote traini
|
|||
|
||||
🔭 Turn your newly trained <b>YOLOv5 model into an API</b> with just a few commands using ClearML Serving
|
||||
|
||||
<br />
|
||||
<br>
|
||||
And so much more. It's up to you how many of these tools you want to use, you can stick to the experiment manager, or chain them all together into an impressive pipeline!
|
||||
<br />
|
||||
<br />
|
||||
<br>
|
||||
<br>
|
||||
|
||||

|
||||
|
||||
<br />
|
||||
<br />
|
||||
<br>
|
||||
<br>
|
||||
|
||||
## 🦾 Setting Things Up
|
||||
|
||||
|
|
@ -52,7 +52,7 @@ Either sign up for free to the [ClearML Hosted Service](https://cutt.ly/yolov5-t
|
|||
|
||||
That's it! You're done 😎
|
||||
|
||||
<br />
|
||||
<br>
|
||||
|
||||
## 🚀 Training YOLOv5 With ClearML
|
||||
|
||||
|
|
@ -95,7 +95,7 @@ That's a lot right? 🤯 Now, we can visualize all of this information in the Cl
|
|||
|
||||
There even more we can do with all of this information, like hyperparameter optimization and remote execution, so keep reading if you want to see how that works!
|
||||
|
||||
<br />
|
||||
<br>
|
||||
|
||||
## 🔗 Dataset Version Management
|
||||
|
||||
|
|
@ -163,7 +163,7 @@ Now that you have a ClearML dataset, you can very simply use it to train custom
|
|||
python train.py --img 640 --batch 16 --epochs 3 --data clearml://<your_dataset_id> --weights yolov5s.pt --cache
|
||||
```
|
||||
|
||||
<br />
|
||||
<br>
|
||||
|
||||
## 👀 Hyperparameter Optimization
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ description: Learn how to set up and use Comet to enhance your YOLOv5 model trai
|
|||
keywords: YOLOv5, Comet, Machine Learning, Ultralytics, Real time metrics tracking, Hyperparameters, Model checkpoints, Model predictions, YOLOv5 training, Comet Credentials
|
||||
---
|
||||
|
||||
<img src="https://cdn.comet.ml/img/notebook_logo.png">
|
||||

|
||||
|
||||
# YOLOv5 with Comet
|
||||
|
||||
|
|
|
|||
|
|
@ -127,7 +127,7 @@ Results saved to runs/detect/exp2
|
|||
Done. (0.223s)
|
||||
```
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124489091-ea4f9a00-ddb0-11eb-8ef1-d6f335c97f6f.jpg" width="500">
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124489091-ea4f9a00-ddb0-11eb-8ef1-d6f335c97f6f.jpg" width="500" alt="YOLO inference result">
|
||||
|
||||
## Environments
|
||||
|
||||
|
|
|
|||
|
|
@ -134,10 +134,10 @@ Visualize: https://netron.app/
|
|||
```
|
||||
|
||||
The 3 exported models will be saved alongside the original PyTorch model:
|
||||
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/122827190-57a8f880-d2e4-11eb-860e-dbb7f9fc57fb.png"></p>
|
||||
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/122827190-57a8f880-d2e4-11eb-860e-dbb7f9fc57fb.png" alt="YOLO export locations"></p>
|
||||
|
||||
[Netron Viewer](https://github.com/lutzroeder/netron) is recommended for visualizing exported models:
|
||||
<p align="center"><img width="850" src="https://user-images.githubusercontent.com/26833433/191003260-f94011a7-5b2e-4fe3-93c1-e1a935e0a728.png"></p>
|
||||
<p align="center"><img width="850" src="https://user-images.githubusercontent.com/26833433/191003260-f94011a7-5b2e-4fe3-93c1-e1a935e0a728.png" alt="YOLO model visualization"></p>
|
||||
|
||||
## Exported Model Usage Examples
|
||||
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ This guide explains how to deploy YOLOv5 with Neural Magic's DeepSparse.
|
|||
DeepSparse is an inference runtime with exceptional performance on CPUs. For instance, compared to the ONNX Runtime baseline, DeepSparse offers a 5.8x speed-up for YOLOv5s, running on the same machine!
|
||||
|
||||
<p align="center">
|
||||
<img width="60%" src="https://github.com/neuralmagic/deepsparse/raw/main/examples/ultralytics-yolo/ultralytics-readmes/performance-chart-5.8x.png">
|
||||
<img width="60%" src="https://github.com/neuralmagic/deepsparse/raw/main/examples/ultralytics-yolo/ultralytics-readmes/performance-chart-5.8x.png" alt="YOLOv5 speed improvement">
|
||||
</p>
|
||||
|
||||
For the first time, your deep learning workloads can meet the performance demands of production without the complexity and costs of hardware accelerators. Put simply, DeepSparse gives you the performance of GPUs and the simplicity of software:
|
||||
|
|
@ -43,7 +43,7 @@ DeepSparse takes advantage of model sparsity to gain its performance speedup.
|
|||
Sparsification through pruning and quantization is a broadly studied technique, allowing order-of-magnitude reductions in the size and compute needed to execute a network, while maintaining high accuracy. DeepSparse is sparsity-aware, meaning it skips the zeroed out parameters, shrinking amount of compute in a forward pass. Since the sparse computation is now memory bound, DeepSparse executes the network depth-wise, breaking the problem into Tensor Columns, vertical stripes of computation that fit in cache.
|
||||
|
||||
<p align="center">
|
||||
<img width="60%" src="https://github.com/neuralmagic/deepsparse/raw/main/examples/ultralytics-yolo/ultralytics-readmes/tensor-columns.png">
|
||||
<img width="60%" src="https://github.com/neuralmagic/deepsparse/raw/main/examples/ultralytics-yolo/ultralytics-readmes/tensor-columns.png" alt="YOLO model pruning">
|
||||
</p>
|
||||
|
||||
Sparse networks with compressed computation, executed depth-wise in cache, allows DeepSparse to deliver GPU-class performance on CPUs!
|
||||
|
|
@ -162,7 +162,7 @@ deepsparse.object_detection.annotate --model_filepath zoo:cv/detection/yolov5-s/
|
|||
Running the above command will create an `annotation-results` folder and save the annotated image inside.
|
||||
|
||||
<p align = "center">
|
||||
<img src="https://github.com/neuralmagic/deepsparse/raw/d31f02596ebff2ec62761d0bc9ca14c4663e8858/src/deepsparse/yolo/sample_images/basilica-annotated.jpg" alt="annotated" width="60%"/>
|
||||
<img src="https://github.com/neuralmagic/deepsparse/raw/d31f02596ebff2ec62761d0bc9ca14c4663e8858/src/deepsparse/yolo/sample_images/basilica-annotated.jpg" alt="annotated" width="60%">
|
||||
</p>
|
||||
|
||||
## Benchmarking Performance
|
||||
|
|
|
|||
|
|
@ -76,7 +76,8 @@ results.pandas().xyxy[0] # im1 predictions (pandas)
|
|||
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
|
||||
```
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124915064-62a49e00-dff1-11eb-86b3-a85b97061afb.jpg" width="500"> <img src="https://user-images.githubusercontent.com/26833433/124915055-60424400-dff1-11eb-9055-24585b375a29.jpg" width="300">
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124915064-62a49e00-dff1-11eb-86b3-a85b97061afb.jpg" width="500" alt="YOLO inference results on zidane.jpg">
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124915055-60424400-dff1-11eb-9055-24585b375a29.jpg" width="300" alt="YOLO inference results on bus.jpg">
|
||||
|
||||
For all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).
|
||||
|
||||
|
|
|
|||
|
|
@ -49,4 +49,4 @@ We have released a custom training tutorial demonstrating all of the above capab
|
|||
|
||||
The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your model deployments by using a battle tested machine learning pipeline.
|
||||
|
||||
<p align=""><a href="https://roboflow.com/?ref=ultralytics"><img width="1000" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/615627e5824c9c6195abfda9_computer-vision-cycle.png"/></a></p>
|
||||
<p align=""><a href="https://roboflow.com/?ref=ultralytics"><img width="1000" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/615627e5824c9c6195abfda9_computer-vision-cycle.png" alt="Roboflow active learning"></a></p>
|
||||
|
|
|
|||
|
|
@ -216,7 +216,7 @@ uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.m
|
|||
deepstream-app -c deepstream_app_config.txt
|
||||
```
|
||||
|
||||
<div align=center><img width=1000 src="https://files.seeedstudio.com/wiki/YOLOV5/FP32-yolov5s.gif"/></div>
|
||||
<div align=center><img width=1000 src="https://files.seeedstudio.com/wiki/YOLOV5/FP32-yolov5s.gif" alt="YOLOv5 with deepstream FP32"></div>
|
||||
|
||||
The above result is running on **Jetson Xavier NX** with **FP32** and **YOLOv5s 640x640**. We can see that the **FPS** is around **30**.
|
||||
|
||||
|
|
@ -299,7 +299,7 @@ network-mode=1
|
|||
deepstream-app -c deepstream_app_config.txt
|
||||
```
|
||||
|
||||
<div align=center><img width=1000 src="https://files.seeedstudio.com/wiki/YOLOV5/INT8-yolov5s.gif"/></div>
|
||||
<div align=center><img width=1000 src="https://files.seeedstudio.com/wiki/YOLOV5/INT8-yolov5s.gif" alt="YOLOv5 with deepstream INT8"></div>
|
||||
|
||||
The above result is running on **Jetson Xavier NX** with **INT8** and **YOLOv5s 640x640**. We can see that the **FPS** is around **60**.
|
||||
|
||||
|
|
|
|||
|
|
@ -121,7 +121,7 @@ Results saved to runs/detect/exp
|
|||
Done. (0.156s)
|
||||
```
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124491703-dbb6b200-ddb3-11eb-8b57-ed0d58d0d8b4.jpg" width="500">
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124491703-dbb6b200-ddb3-11eb-8b57-ed0d58d0d8b4.jpg" width="500" alt="YOLOv5 test time augmentations">
|
||||
|
||||
### PyTorch Hub TTA
|
||||
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ pip install -r requirements.txt # install
|
|||
## Train On Custom Data
|
||||
|
||||
<a href="https://bit.ly/ultralytics_hub" target="_blank">
|
||||
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/integrations-loop.png"></a>
|
||||
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/integrations-loop.png" alt="Ultralytics active learning"></a>
|
||||
<br>
|
||||
<br>
|
||||
|
||||
|
|
@ -46,7 +46,7 @@ If this is not possible, you can start from [a public dataset](https://universe.
|
|||
|
||||
Once you have collected images, you will need to annotate the objects of interest to create a ground truth for your model to learn from.
|
||||
|
||||
<p align="center"><a href="https://app.roboflow.com/?model=yolov5&ref=ultralytics" title="Create a Free Roboflow Account"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a275ad4b4ac20cd2e21a_roboflow-annotate.gif" /></a></p>
|
||||
<p align="center"><a href="https://app.roboflow.com/?model=yolov5&ref=ultralytics" title="Create a Free Roboflow Account"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a275ad4b4ac20cd2e21a_roboflow-annotate.gif" alt="YOLOv5 accuracies"></a></p>
|
||||
|
||||
[Roboflow Annotate](https://roboflow.com/annotate?ref=ultralytics) is a simple web-based tool for managing and labeling your images with your team and exporting them in [YOLOv5's annotation format](https://roboflow.com/formats/yolov5-pytorch-txt?ref=ultralytics).
|
||||
|
||||
|
|
@ -59,18 +59,18 @@ and upload your dataset to a `Public` workspace, label any unannotated images, t
|
|||
|
||||
Note: YOLOv5 does online augmentation during training, so we do not recommend applying any augmentation steps in Roboflow for training with YOLOv5. But we recommend applying the following preprocessing steps:
|
||||
|
||||
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a273477fccf42a0fd3d6_roboflow-preprocessing.png" title="Recommended Preprocessing Steps" /></p>
|
||||
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a273477fccf42a0fd3d6_roboflow-preprocessing.png" alt="Recommended Preprocessing Steps"></p>
|
||||
|
||||
* **Auto-Orient** - to strip EXIF orientation from your images.
|
||||
* **Resize (Stretch)** - to the square input size of your model (640x640 is the YOLOv5 default).
|
||||
|
||||
Generating a version will give you a point in time snapshot of your dataset so you can always go back and compare your future model training runs against it, even if you add more images or change its configuration later.
|
||||
|
||||
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a2733fd1da943619934e_roboflow-export.png" title="Export in YOLOv5 Format" /></p>
|
||||
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a2733fd1da943619934e_roboflow-export.png" alt="Export in YOLOv5 Format"></p>
|
||||
|
||||
Export in `YOLOv5 Pytorch` format, then copy the snippet into your training script or notebook to download your dataset.
|
||||
|
||||
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a273a92e4f5cb72594df_roboflow-snippet.png" title="Roboflow dataset download snippet" /></p>
|
||||
<p align="center"><img width="450" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/6152a273a92e4f5cb72594df_roboflow-snippet.png" alt="Roboflow dataset download snippet"></p>
|
||||
|
||||
Now continue with `2. Select a Model`.
|
||||
</details>
|
||||
|
|
@ -106,14 +106,14 @@ After using an annotation tool to label your images, export your labels to **YOL
|
|||
|
||||
- One row per object
|
||||
- Each row is `class x_center y_center width height` format.
|
||||
- Box coordinates must be in **normalized xywh** format (from 0 - 1). If your boxes are in pixels, divide `x_center` and `width` by image width, and `y_center` and `height` by image height.
|
||||
- Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, divide `x_center` and `width` by image width, and `y_center` and `height` by image height.
|
||||
- Class numbers are zero-indexed (start from 0).
|
||||
|
||||
<p align="center"><img width="750" src="https://user-images.githubusercontent.com/26833433/91506361-c7965000-e886-11ea-8291-c72b98c25eec.jpg"></p>
|
||||
<p align="center"><img width="750" src="https://user-images.githubusercontent.com/26833433/91506361-c7965000-e886-11ea-8291-c72b98c25eec.jpg" alt="Roboflow annotations"></p>
|
||||
|
||||
The label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):
|
||||
|
||||
<p align="center"><img width="428" src="https://user-images.githubusercontent.com/26833433/112467037-d2568c00-8d66-11eb-8796-55402ac0d62f.png"></p>
|
||||
<p align="center"><img width="428" src="https://user-images.githubusercontent.com/26833433/112467037-d2568c00-8d66-11eb-8796-55402ac0d62f.png" alt="Roboflow dataset preprocessing"></p>
|
||||
|
||||
### 1.3 Organize Directories
|
||||
|
||||
|
|
@ -124,14 +124,14 @@ Organize your train and val images and labels according to the example below. YO
|
|||
../datasets/coco128/labels/im0.txt # label
|
||||
```
|
||||
|
||||
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/134436012-65111ad1-9541-4853-81a6-f19a3468b75f.png"></p>
|
||||
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/134436012-65111ad1-9541-4853-81a6-f19a3468b75f.png" alt="YOLOv5 dataset structure"></p>
|
||||
</details>
|
||||
|
||||
### 2. Select a Model
|
||||
|
||||
Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the second-smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
|
||||
|
||||
<p align="center"><img width="800" alt="YOLOv5 Models" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/model_comparison.png"></p>
|
||||
<p align="center"><img width="800" alt="YOLOv5 models" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/model_comparison.png"></p>
|
||||
|
||||
### 3. Train
|
||||
|
||||
|
|
@ -168,7 +168,7 @@ python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt #
|
|||
To learn more about all the supported Comet features for this integration, check out the [Comet Tutorial](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration). If you'd like to learn more about Comet, head over to our [documentation](https://bit.ly/yolov5-colab-comet-docs). Get started by trying out the Comet Colab Notebook:
|
||||
[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
|
||||
|
||||
<img width="1920" alt="yolo-ui" src="https://user-images.githubusercontent.com/26833433/202851203-164e94e1-2238-46dd-91f8-de020e9d6b41.png">
|
||||
<img width="1920" alt="YOLO UI" src="https://user-images.githubusercontent.com/26833433/202851203-164e94e1-2238-46dd-91f8-de020e9d6b41.png">
|
||||
|
||||
#### ClearML Logging and Automation 🌟 NEW
|
||||
|
||||
|
|
@ -182,7 +182,7 @@ You'll get all the great expected features from an experiment manager: live upda
|
|||
You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!
|
||||
|
||||
<a href="https://cutt.ly/yolov5-notebook-clearml">
|
||||
<img alt="ClearML Experiment Management UI" src="https://github.com/thepycoder/clearml_screenshots/raw/main/scalars.jpg" width="1280"/></a>
|
||||
<img alt="ClearML Experiment Management UI" src="https://github.com/thepycoder/clearml_screenshots/raw/main/scalars.jpg" width="1280"></a>
|
||||
|
||||
#### Local Logging
|
||||
|
||||
|
|
@ -190,7 +190,7 @@ Training results are automatically logged with [Tensorboard](https://www.tensorf
|
|||
|
||||
This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
|
||||
|
||||
<img alt="Local logging results" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/image-local_logging.jpg" width="1280"/>
|
||||
<img alt="Local logging results" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/image-local_logging.jpg" width="1280">
|
||||
|
||||
Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
|
||||
|
||||
|
|
|
|||
|
|
@ -124,19 +124,19 @@ train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --i
|
|||
|
||||
The results show that freezing speeds up training, but reduces final accuracy slightly.
|
||||
|
||||
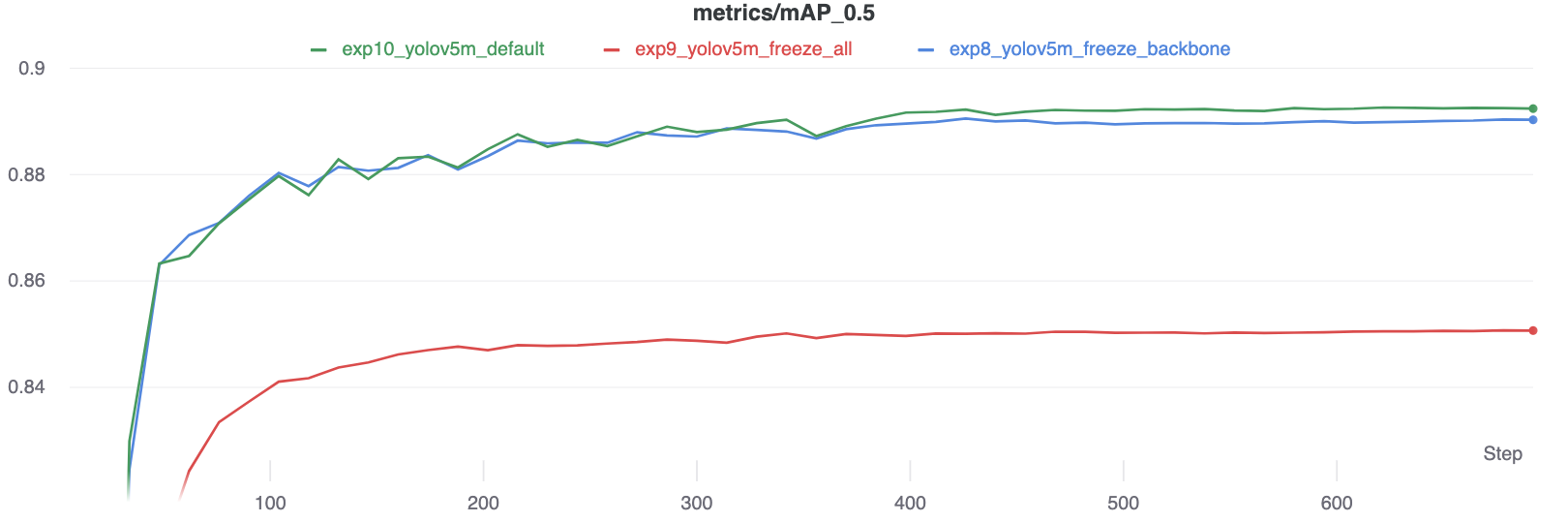
|
||||

|
||||
|
||||
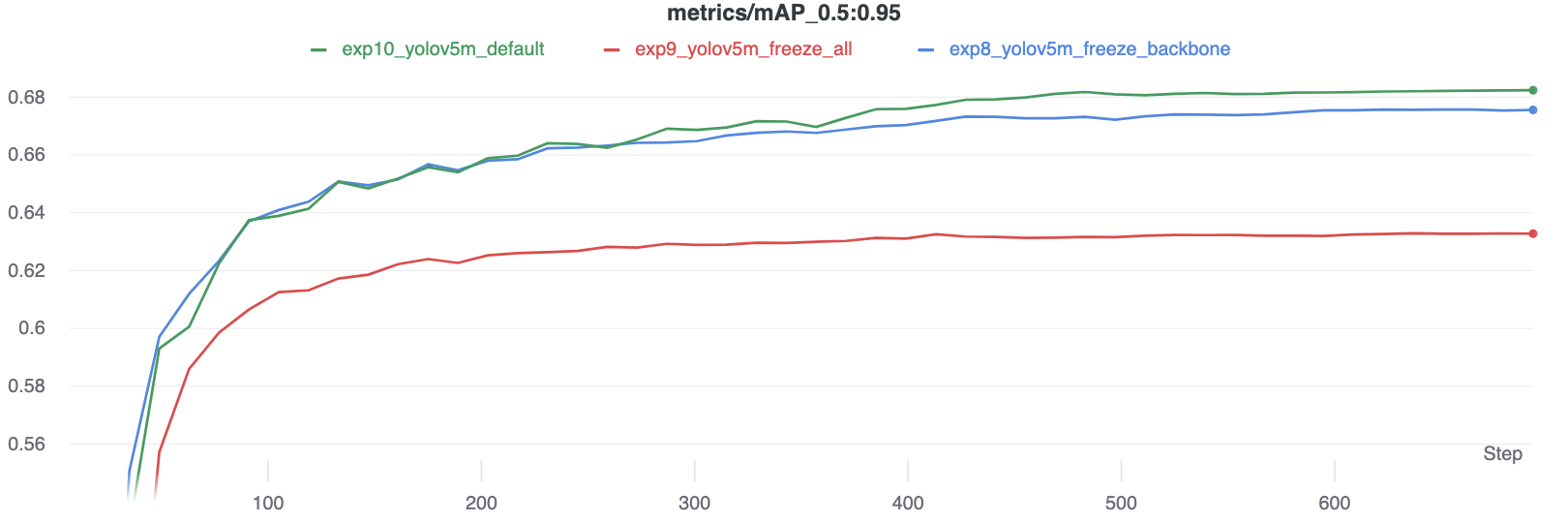
|
||||

|
||||
|
||||
<img width="922" alt="Screenshot 2020-11-06 at 18 08 13" src="https://user-images.githubusercontent.com/26833433/98394485-22081580-205b-11eb-9e37-1f9869fe91d8.png">
|
||||
<img width="922" alt="Table results" src="https://user-images.githubusercontent.com/26833433/98394485-22081580-205b-11eb-9e37-1f9869fe91d8.png">
|
||||
|
||||
### GPU Utilization Comparison
|
||||
|
||||
Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.
|
||||
|
||||
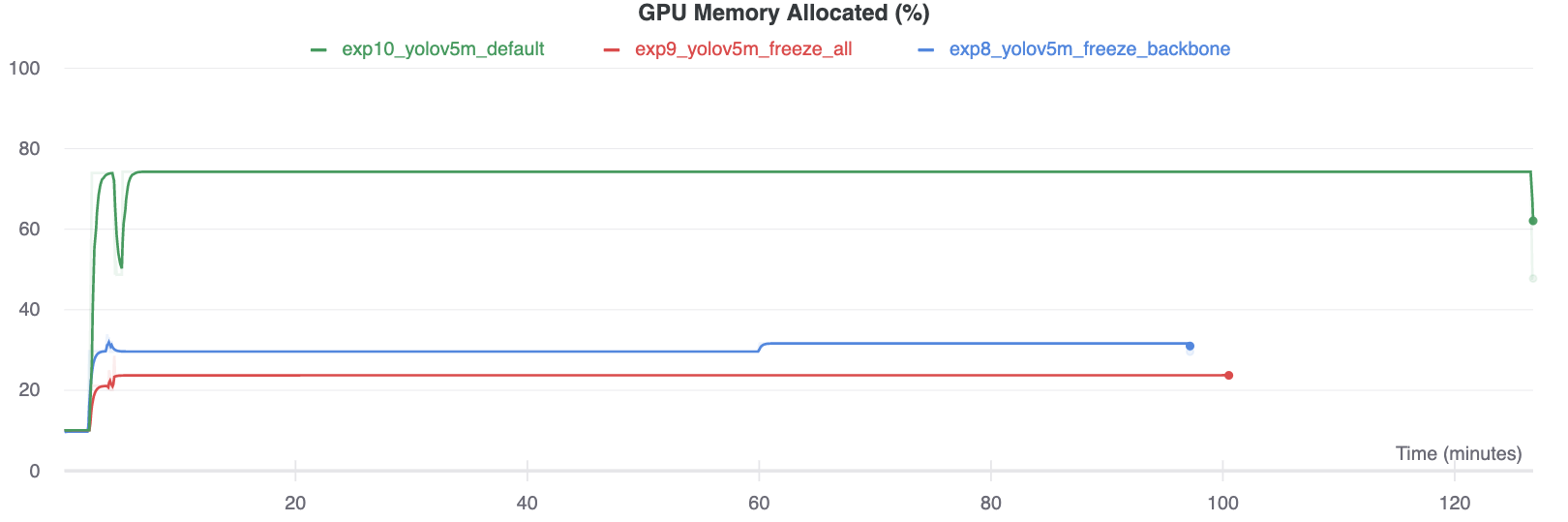
|
||||

|
||||
|
||||
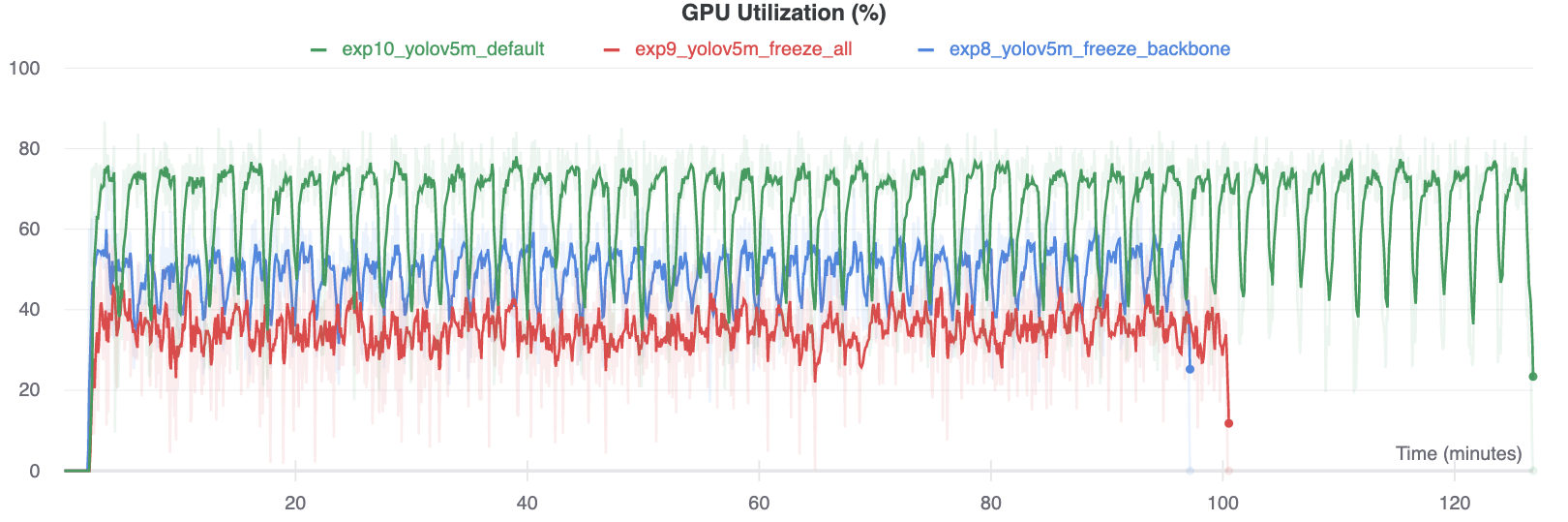
|
||||

|
||||
|
||||
## Environments
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue