Update TFLite Docs images (#8605)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com>
This commit is contained in:
parent
1146bb0582
commit
36408c974c
33 changed files with 112 additions and 107 deletions
|
|
@ -38,7 +38,7 @@ First, ensure you have the following prerequisites in place:
|
|||
|
||||
- AWS CDK: If not already installed, install the AWS Cloud Development Kit (CDK), which will be used for scripting the deployment. Follow [the AWS CDK instructions](https://docs.aws.amazon.com/cdk/v2/guide/getting_started.html#getting_started_install) for installation.
|
||||
|
||||
- Adequate Service Quota: Confirm that you have sufficient quotas for two separate resources in Amazon SageMaker: one for ml.m5.4xlarge for endpoint usage and another for ml.m5.4xlarge for notebook instance usage. Each of these requires a minimum of one quota value. If your current quotas are below this requirement, it's important to request an increase for each. You can request a quota increase by following the detailed instructions in the [AWS Service Quotas documentation](https://docs.aws.amazon.com/servicequotas/latest/userguide/request-quota-increase.html#quota-console-increase).
|
||||
- Adequate Service Quota: Confirm that you have sufficient quotas for two separate resources in Amazon SageMaker: one for `ml.m5.4xlarge` for endpoint usage and another for `ml.m5.4xlarge` for notebook instance usage. Each of these requires a minimum of one quota value. If your current quotas are below this requirement, it's important to request an increase for each. You can request a quota increase by following the detailed instructions in the [AWS Service Quotas documentation](https://docs.aws.amazon.com/servicequotas/latest/userguide/request-quota-increase.html#quota-console-increase).
|
||||
|
||||
### Step 2: Clone the YOLOv8 SageMaker Repository
|
||||
|
||||
|
|
@ -115,17 +115,21 @@ After creating the AWS CloudFormation Stack, the next step is to deploy YOLOv8.
|
|||
- Access and Modify inference.py: After opening the SageMaker notebook instance in Jupyter, locate the inference.py file. Edit the output_fn function in inference.py as shown below and save your changes to the script, ensuring that there are no syntax errors.
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def output_fn(prediction_output, content_type):
|
||||
print("Executing output_fn from inference.py ...")
|
||||
infer = {}
|
||||
for result in prediction_output:
|
||||
if 'boxes' in result._keys and result.boxes is not None:
|
||||
if result.boxes is not None:
|
||||
infer['boxes'] = result.boxes.numpy().data.tolist()
|
||||
if 'masks' in result._keys and result.masks is not None:
|
||||
if result.masks is not None:
|
||||
infer['masks'] = result.masks.numpy().data.tolist()
|
||||
if 'keypoints' in result._keys and result.keypoints is not None:
|
||||
if result.keypoints is not None:
|
||||
infer['keypoints'] = result.keypoints.numpy().data.tolist()
|
||||
if 'probs' in result._keys and result.probs is not None:
|
||||
if result.obb is not None:
|
||||
infer['obb'] = result.obb.numpy().data.tolist()
|
||||
if result.probs is not None:
|
||||
infer['probs'] = result.probs.numpy().data.tolist()
|
||||
return json.dumps(infer)
|
||||
```
|
||||
|
|
|
|||
|
|
@ -18,9 +18,10 @@ The CoreML export format allows you to optimize your [Ultralytics YOLOv8](https:
|
|||
|
||||
[CoreML](https://developer.apple.com/documentation/coreml) is Apple's foundational machine learning framework that builds upon Accelerate, BNNS, and Metal Performance Shaders. It provides a machine-learning model format that seamlessly integrates into iOS applications and supports tasks such as image analysis, natural language processing, audio-to-text conversion, and sound analysis.
|
||||
|
||||
Applications can take advantage of Core ML without the need to have a network connection or API calls because the Core ML framework works using on-device computing. This means model inferencing can be performed locally on the user's device.
|
||||
Applications can take advantage of Core ML without the need to have a network connection or API calls because the Core ML framework works using on-device computing. This means model inference can be performed locally on the user's device.
|
||||
|
||||
## Key Features of CoreML Models
|
||||
|
||||
Apple's CoreML framework offers robust features for on-device machine learning. Here are the key features that make CoreML a powerful tool for developers:
|
||||
|
||||
- **Comprehensive Model Support**: Converts and runs models from popular frameworks like TensorFlow, PyTorch, scikit-learn, XGBoost, and LibSVM.
|
||||
|
|
|
|||
|
|
@ -53,7 +53,7 @@ Welcome to the Ultralytics Integrations page! This page provides an overview of
|
|||
- [CoreML](coreml.md): CoreML, developed by [Apple](https://www.apple.com/), is a framework designed for efficiently integrating machine learning models into applications across iOS, macOS, watchOS, and tvOS, using Apple's hardware for effective and secure model deployment.
|
||||
|
||||
- [TFLite](tflite.md): Developed by [Google](https://www.google.com), TFLite is a lightweight framework for deploying machine learning models on mobile and edge devices, ensuring fast, efficient inference with minimal memory footprint.
|
||||
|
||||
|
||||
- [NCNN](ncnn.md): Developed by [Tencent](http://www.tencent.com/), NCNN is an efficient neural network inference framework tailored for mobile devices. It enables direct deployment of AI models into apps, optimizing performance across various mobile platforms.
|
||||
|
||||
### Export Formats
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ keywords: Ultralytics, YOLOv8, NCNN Export, Export YOLOv8, Model Deployment
|
|||
|
||||
# How to Export to NCNN from YOLOv8 for Smooth Deployment
|
||||
|
||||
Deploying computer vision models on devices with limited computational power, such as mobile or embedded systems, can be tricky. You need to make sure you use a format optimized for optimal performance. This makes sure that even devices with limited processing power can handle advanced computer vision tasks well.
|
||||
Deploying computer vision models on devices with limited computational power, such as mobile or embedded systems, can be tricky. You need to make sure you use a format optimized for optimal performance. This makes sure that even devices with limited processing power can handle advanced computer vision tasks well.
|
||||
|
||||
The export to NCNN format feature allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for lightweight device-based applications. In this guide, we'll walk you through how to convert your models to the NCNN format, making it easier for your models to perform well on various mobile and embedded devices.
|
||||
|
||||
|
|
@ -18,19 +18,19 @@ The export to NCNN format feature allows you to optimize your [Ultralytics YOLOv
|
|||
|
||||
The [NCNN](https://github.com/Tencent/ncnn) framework, developed by Tencent, is a high-performance neural network inference computing framework optimized specifically for mobile platforms, including mobile phones, embedded devices, and IoT devices. NCNN is compatible with a wide range of platforms, including Linux, Android, iOS, and macOS.
|
||||
|
||||
NCNN is known for its fast processing speed on mobile CPUs and enables rapid deployment of deep learning models to mobile platforms. This makes it easier to build smart apps, putting the power of AI right at your fingertips.
|
||||
NCNN is known for its fast processing speed on mobile CPUs and enables rapid deployment of deep learning models to mobile platforms. This makes it easier to build smart apps, putting the power of AI right at your fingertips.
|
||||
|
||||
## Key Features of NCNN Models
|
||||
|
||||
NCNN models offer a wide range of key features that enable on-device machine learning by helping developers run their models on mobile, embedded, and edge devices:
|
||||
|
||||
- **Efficient and High-Performance**: NCNN models are made to be efficient and lightweight, optimized for running on mobile and embedded devices like Raspberry Pi with limited resources. They can also achieve high performance with high accuracy on various computer vision-based tasks.
|
||||
- **Efficient and High-Performance**: NCNN models are made to be efficient and lightweight, optimized for running on mobile and embedded devices like Raspberry Pi with limited resources. They can also achieve high performance with high accuracy on various computer vision-based tasks.
|
||||
|
||||
- **Quantization**: NCNN models often support quantization which is a technique that reduces the precision of the model's weights and activations. This leads to further improvements in performance and reduces memory footprint.
|
||||
- **Quantization**: NCNN models often support quantization which is a technique that reduces the precision of the model's weights and activations. This leads to further improvements in performance and reduces memory footprint.
|
||||
|
||||
- **Compatibility**: NCNN models are compatible with popular deep learning frameworks like [TensorFlow](https://www.tensorflow.org/), [Caffe](https://caffe.berkeleyvision.org/), and [ONNX](https://onnx.ai/). This compatibility allows developers to use existing models and workflows easily.
|
||||
- **Compatibility**: NCNN models are compatible with popular deep learning frameworks like [TensorFlow](https://www.tensorflow.org/), [Caffe](https://caffe.berkeleyvision.org/), and [ONNX](https://onnx.ai/). This compatibility allows developers to use existing models and workflows easily.
|
||||
|
||||
- **Easy to Use**: NCNN models are designed for easy integration into various applications, thanks to their compatibility with popular deep learning frameworks. Additionally, NCNN offers user-friendly tools for converting models between different formats, ensuring smooth interoperability across the development landscape.
|
||||
- **Easy to Use**: NCNN models are designed for easy integration into various applications, thanks to their compatibility with popular deep learning frameworks. Additionally, NCNN offers user-friendly tools for converting models between different formats, ensuring smooth interoperability across the development landscape.
|
||||
|
||||
## Deployment Options with NCNN
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ For detailed instructions and best practices related to the installation process
|
|||
|
||||
### Usage
|
||||
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models]((../models/index.md)) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
|
||||
|
||||
!!! Example "Usage"
|
||||
|
||||
|
|
@ -103,13 +103,13 @@ For more details about supported export options, visit the [Ultralytics document
|
|||
|
||||
After successfully exporting your Ultralytics YOLOv8 models to NCNN format, you can now deploy them. The primary and recommended first step for running a NCNN model is to utilize the YOLO("./model_ncnn_model") method, as outlined in the previous usage code snippet. However, for in-depth instructions on deploying your NCNN models in various other settings, take a look at the following resources:
|
||||
|
||||
- **[Android](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-android)**: This blog explains how to use NCNN models for performing tasks like object detection through Android applications.
|
||||
- **[Android](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-android)**: This blog explains how to use NCNN models for performing tasks like object detection through Android applications.
|
||||
|
||||
- **[macOS](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-macos)**: Understand how to use NCNN models for performing tasks through macOS.
|
||||
- **[macOS](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-macos)**: Understand how to use NCNN models for performing tasks through macOS.
|
||||
|
||||
- **[Linux](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-linux)**: Explore this page to learn how to deploy NCNN models on limited resource devices like Raspberry Pi and other similar devices.
|
||||
- **[Linux](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-linux)**: Explore this page to learn how to deploy NCNN models on limited resource devices like Raspberry Pi and other similar devices.
|
||||
|
||||
- **[Windows x64 using VS2017](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-windows-x64-using-visual-studio-community-2017)**: Explore this blog to learn how to deploy NCNN models on windows x64 using Visual Studio Community 2017.
|
||||
- **[Windows x64 using VS2017](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-windows-x64-using-visual-studio-community-2017)**: Explore this blog to learn how to deploy NCNN models on windows x64 using Visual Studio Community 2017.
|
||||
|
||||
## Summary
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ keywords: YOLOv8, DeepSparse Engine, Ultralytics, CPU Inference, Neural Network
|
|||
|
||||
# Optimizing YOLOv8 Inferences with Neural Magic’s DeepSparse Engine
|
||||
|
||||
When deploying object detection models like [Ultralytics’ YOLOv8](https://ultralytics.com) on various hardware, you can bump into unique issues like optimization. This is where YOLOv8’s integration with Neural Magic’s DeepSparse Engine steps in. It transforms the way YOLOv8 models are executed and enables GPU-level performance directly on CPUs.
|
||||
When deploying object detection models like [Ultralytics YOLOv8](https://ultralytics.com) on various hardware, you can bump into unique issues like optimization. This is where YOLOv8’s integration with Neural Magic’s DeepSparse Engine steps in. It transforms the way YOLOv8 models are executed and enables GPU-level performance directly on CPUs.
|
||||
|
||||
This guide shows you how to deploy YOLOv8 using Neural Magic's DeepSparse, how to run inferences, and also how to benchmark performance to ensure it is optimized.
|
||||
|
||||
|
|
|
|||
|
|
@ -102,7 +102,7 @@ The Time Series feature in the TensorBoard offers a dynamic and detailed perspec
|
|||
|
||||
#### Importance of Time Series in YOLOv8 Training
|
||||
|
||||
The Time Series section is essential for a thorough analysis of the YOLOv8 model's training progress. It lets you track the metrics in real time so you can promptly identify and solve issues. It also offers a detailed view of each metric's progression, which is crucial for fine-tuning the model and enhancing its performance.
|
||||
The Time Series section is essential for a thorough analysis of the YOLOv8 model's training progress. It lets you track the metrics in real time to promptly identify and solve issues. It also offers a detailed view of each metric's progression, which is crucial for fine-tuning the model and enhancing its performance.
|
||||
|
||||
### Scalars
|
||||
|
||||
|
|
@ -146,7 +146,7 @@ Graphs are particularly useful for debugging the model, especially in complex ar
|
|||
|
||||
## Summary
|
||||
|
||||
This guide aims to help you use TensorBoard with YOLOv8 for visualization and analysis of machine learning model training. It focuses on explaining how key TensorBoard features can provides insights into training metrics and model performance during YOLOv8 training sessions.
|
||||
This guide aims to help you use TensorBoard with YOLOv8 for visualization and analysis of machine learning model training. It focuses on explaining how key TensorBoard features can provide insights into training metrics and model performance during YOLOv8 training sessions.
|
||||
|
||||
For a more detailed exploration of these features and effective utilization strategies, you can refer to TensorFlow’s official [TensorBoard documentation](https://www.tensorflow.org/tensorboard/get_started) and their [GitHub repository](https://github.com/tensorflow/tensorboard).
|
||||
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ By using the TensorRT export format, you can enhance your [Ultralytics YOLOv8](h
|
|||
<img width="100%" src="https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-601/tensorrt-developer-guide/graphics/whatistrt2.png" alt="TensorRT Overview">
|
||||
</p>
|
||||
|
||||
[TensorRT](https://developer.nvidia.com/tensorrt#:~:text=NVIDIA%20TensorRT%2DLLM%20is%20an,knowledge%20of%20C%2B%2B%20or%20CUDA.), developed by NVIDIA, is an advanced software development kit (SDK) designed for high-speed deep learning inference. It’s well-suited for real-time applications like object detection.
|
||||
[TensorRT](https://developer.nvidia.com/tensorrt), developed by NVIDIA, is an advanced software development kit (SDK) designed for high-speed deep learning inference. It’s well-suited for real-time applications like object detection.
|
||||
|
||||
This toolkit optimizes deep learning models for NVIDIA GPUs and results in faster and more efficient operations. TensorRT models undergo TensorRT optimization, which includes techniques like layer fusion, precision calibration (INT8 and FP16), dynamic tensor memory management, and kernel auto-tuning. Converting deep learning models into the TensorRT format allows developers to realize the potential of NVIDIA GPUs fully.
|
||||
|
||||
|
|
@ -40,7 +40,7 @@ TensorRT models offer a range of key features that contribute to their efficienc
|
|||
|
||||
## Deployment Options in TensorRT
|
||||
|
||||
Before we look at the code for exporting YOLOv8 models to the TensorRT format, let’s understand where TensorRT models are normally used.
|
||||
Before we look at the code for exporting YOLOv8 models to the TensorRT format, let’s understand where TensorRT models are normally used.
|
||||
|
||||
TensorRT offers several deployment options, and each option balances ease of integration, performance optimization, and flexibility differently:
|
||||
|
||||
|
|
@ -52,7 +52,7 @@ TensorRT offers several deployment options, and each option balances ease of int
|
|||
|
||||
- **Standalone TensorRT Runtime API**: Offers granular control, ideal for performance-critical applications. It's more complex but allows for custom implementation of unsupported operators.
|
||||
|
||||
- **NVIDIA Triton Inference Server**: An option that supports models from various frameworks. Particularly suited for cloud or edge inferencing, it provides features like concurrent model execution and model analysis.
|
||||
- **NVIDIA Triton Inference Server**: An option that supports models from various frameworks. Particularly suited for cloud or edge inference, it provides features like concurrent model execution and model analysis.
|
||||
|
||||
## Exporting YOLOv8 Models to TensorRT
|
||||
|
||||
|
|
|
|||
|
|
@ -6,17 +6,17 @@ keywords: Ultralytics, YOLOv8, TFLite Export, Export YOLOv8, Model Deployment
|
|||
|
||||
# A Guide on YOLOv8 Model Export to TFLite for Deployment
|
||||
|
||||
<p align="center">
|
||||
<img width="75%" src="https://github.com/ultralytics/ultralytics/assets/26833433/6ecf34b9-9187-4d6f-815c-72394290a4d3" alt="TFLite Logo">
|
||||
</p>
|
||||
|
||||
Deploying computer vision models on edge devices or embedded devices requires a format that can ensure seamless performance.
|
||||
|
||||
The TensorFlow Lite or TFLite export format allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for tasks like object detection and image classification in edge device-based applications. In this guide, we'll walk through the steps for converting your models to the TFLite format, making it easier for your models to perform well on various edge devices.
|
||||
|
||||
## Why should you export to TFLite?
|
||||
|
||||
<p align="center">
|
||||
<img width="100%" src="https://2.bp.blogspot.com/-mNcMMMsyQCc/XpT0ReRUTBI/AAAAAAAAC-g/-yQX6bCqbxEuSAlDNSUPQkytsn6Ml8qrQCLcBGAsYHQ/s1600/Screen%2BShot%2B2020-04-13%2Bat%2B4.22.27%2BPM.png" alt="TFLite Logo">
|
||||
</p>
|
||||
|
||||
Introduced by Google in May 2017 as part of their TensorFlow framework, [TensorFlow Lite](https://www.tensorflow.org/lite/guide), or TFLite for short, is an open-source deep learning framework designed for on-device inference, also known as edge computing. It gives developers the necessary tools to execute their trained models on mobile, embedded, and IoT devices, as well as traditional computers.
|
||||
Introduced by Google in May 2017 as part of their TensorFlow framework, [TensorFlow Lite](https://www.tensorflow.org/lite/guide), or TFLite for short, is an open-source deep learning framework designed for on-device inference, also known as edge computing. It gives developers the necessary tools to execute their trained models on mobile, embedded, and IoT devices, as well as traditional computers.
|
||||
|
||||
TensorFlow Lite is compatible with a wide range of platforms, including embedded Linux, Android, iOS, and MCU. Exporting your model to TFLite makes your applications faster, more reliable, and capable of running offline.
|
||||
|
||||
|
|
@ -38,15 +38,15 @@ Before we look at the code for exporting YOLOv8 models to the TFLite format, let
|
|||
|
||||
TFLite offers various on-device deployment options for machine learning models, including:
|
||||
|
||||
- **Deploying with Android and iOS**: Both Android and iOS applications with TFLite can analyze edge-based camera feeds and sensors to detect and identify objects. TFLite also offers native iOS libraries written in [Swift](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/swift) and [Objective-C](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/objc). The architecture diagram below shows the process of deploying a trained model onto Android and iOS platforms using TensorFlow Lite.
|
||||
- **Deploying with Android and iOS**: Both Android and iOS applications with TFLite can analyze edge-based camera feeds and sensors to detect and identify objects. TFLite also offers native iOS libraries written in [Swift](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/swift) and [Objective-C](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/objc). The architecture diagram below shows the process of deploying a trained model onto Android and iOS platforms using TensorFlow Lite.
|
||||
|
||||
<p align="center">
|
||||
<img width="100%" src="https://1.bp.blogspot.com/-6fS9FD8KD7g/XhJ1l8y2S4I/AAAAAAAACKw/MW9MQZ8gtiYmUe0naRdN0n2FwkT1l4trACLcBGAsYHQ/s1600/architecture.png" alt="Architecture">
|
||||
<img width="75%" src="https://1.bp.blogspot.com/-6fS9FD8KD7g/XhJ1l8y2S4I/AAAAAAAACKw/MW9MQZ8gtiYmUe0naRdN0n2FwkT1l4trACLcBGAsYHQ/s1600/architecture.png" alt="Architecture">
|
||||
</p>
|
||||
|
||||
- **Implementing with Embedded Linux**: If running inferences on a [Raspberry Pi](https://www.raspberrypi.org/) using the [Ultralytics Guide](../guides/raspberry-pi.md) does not meet the speed requirements for your use case, you can use an exported TFLite model to accelerate inference times. Additionally, it's possible to further improve performance by utilizing a [Coral Edge TPU device]((https://coral.withgoogle.com/)).
|
||||
- **Implementing with Embedded Linux**: If running inferences on a [Raspberry Pi](https://www.raspberrypi.org/) using the [Ultralytics Guide](../guides/raspberry-pi.md) does not meet the speed requirements for your use case, you can use an exported TFLite model to accelerate inference times. Additionally, it's possible to further improve performance by utilizing a [Coral Edge TPU device](https://coral.withgoogle.com/).
|
||||
|
||||
- **Deploying with Microcontrollers**: TFLite models can also be deployed on microcontrollers and other devices with only a few kilobytes of memory. The core runtime just fits in 16 KB on an Arm Cortex M3 and can run many basic models. It doesn't require operating system support, any standard C or C++ libraries, or dynamic memory allocation.
|
||||
- **Deploying with Microcontrollers**: TFLite models can also be deployed on microcontrollers and other devices with only a few kilobytes of memory. The core runtime just fits in 16 KB on an Arm Cortex M3 and can run many basic models. It doesn't require operating system support, any standard C or C++ libraries, or dynamic memory allocation.
|
||||
|
||||
## Export to TFLite: Converting Your YOLOv8 Model
|
||||
|
||||
|
|
@ -69,7 +69,7 @@ For detailed instructions and best practices related to the installation process
|
|||
|
||||
### Usage
|
||||
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models]((../models/index.md)) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
|
||||
|
||||
!!! Example "Usage"
|
||||
|
||||
|
|
@ -107,11 +107,11 @@ For more details about the export process, visit the [Ultralytics documentation
|
|||
|
||||
After successfully exporting your Ultralytics YOLOv8 models to TFLite format, you can now deploy them. The primary and recommended first step for running a TFLite model is to utilize the YOLO("model.tflite") method, as outlined in the previous usage code snippet. However, for in-depth instructions on deploying your TFLite models in various other settings, take a look at the following resources:
|
||||
|
||||
- **[Android](https://www.tensorflow.org/lite/android/quickstart)**: A quick start guide for integrating TensorFlow Lite into Android applications, providing easy-to-follow steps for setting up and running machine learning models.
|
||||
- **[Android](https://www.tensorflow.org/lite/android/quickstart)**: A quick start guide for integrating TensorFlow Lite into Android applications, providing easy-to-follow steps for setting up and running machine learning models.
|
||||
|
||||
- **[iOS](https://www.tensorflow.org/lite/guide/ios)**: Check out this detailed guide for developers on integrating and deploying TensorFlow Lite models in iOS applications, offering step-by-step instructions and resources.
|
||||
- **[iOS](https://www.tensorflow.org/lite/guide/ios)**: Check out this detailed guide for developers on integrating and deploying TensorFlow Lite models in iOS applications, offering step-by-step instructions and resources.
|
||||
|
||||
- **[End-To-End Examples](https://www.tensorflow.org/lite/examples)**: This page provides an overview of various TensorFlow Lite examples, showcasing practical applications and tutorials designed to help developers implement TensorFlow Lite in their machine learning projects on mobile and edge devices.
|
||||
- **[End-To-End Examples](https://www.tensorflow.org/lite/examples)**: This page provides an overview of various TensorFlow Lite examples, showcasing practical applications and tutorials designed to help developers implement TensorFlow Lite in their machine learning projects on mobile and edge devices.
|
||||
|
||||
## Summary
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: Ultralytics, YOLOv8, Export to Torchscript, Model Optimization, Deploy
|
|||
|
||||
Deploying computer vision models across different environments, including embedded systems, web browsers, or platforms with limited Python support, requires a flexible and portable solution. TorchScript focuses on portability and the ability to run models in environments where the entire Python framework is unavailable. This makes it ideal for scenarios where you need to deploy your computer vision capabilities across various devices or platforms.
|
||||
|
||||
Export to Torchscript to serialize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for cross-platform compatibility and streamlined deployment. In this guide, we'll show you how to export your YOLOv8 models to the TorchScript format, making it easier for you to use them across a wider range of applications.
|
||||
Export to Torchscript to serialize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for cross-platform compatibility and streamlined deployment. In this guide, we'll show you how to export your YOLOv8 models to the TorchScript format, making it easier for you to use them across a wider range of applications.
|
||||
|
||||
## Why should you export to TorchScript?
|
||||
|
||||
|
|
@ -16,7 +16,7 @@ Export to Torchscript to serialize your [Ultralytics YOLOv8](https://github.com/
|
|||
|
||||
Developed by the creators of PyTorch, TorchScript is a powerful tool for optimizing and deploying PyTorch models across a variety of platforms. Exporting YOLOv8 models to [TorchScript](https://pytorch.org/docs/stable/jit.html) is crucial for moving from research to real-world applications. TorchScript, part of the PyTorch framework, helps make this transition smoother by allowing PyTorch models to be used in environments that don't support Python.
|
||||
|
||||
The process involves two techniques: tracing and scripting. Tracing records operations during model execution, while scripting allows for the definition of models using a subset of Python. These techniques ensures that models like YOLOv8 can still work their magic even outside their usual Python environment.
|
||||
The process involves two techniques: tracing and scripting. Tracing records operations during model execution, while scripting allows for the definition of models using a subset of Python. These techniques ensure that models like YOLOv8 can still work their magic even outside their usual Python environment.
|
||||
|
||||

|
||||
|
||||
|
|
@ -24,7 +24,7 @@ TorchScript models can also be optimized through techniques such as operator fus
|
|||
|
||||
## Key Features of TorchScript Models
|
||||
|
||||
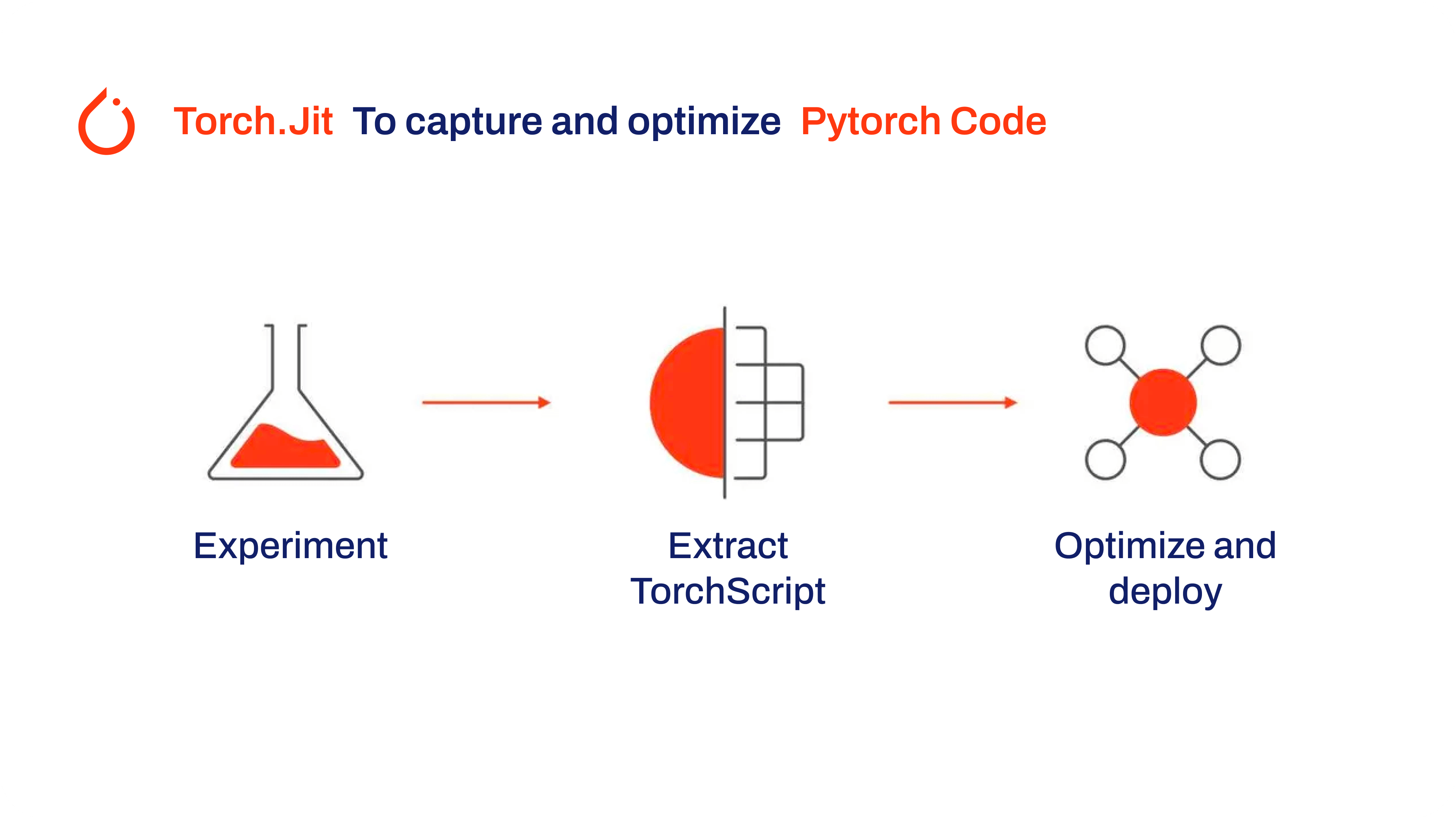
TorchScript, a key part of the PyTorch ecosystem, provides powerful features for optimizing and deploying deep learning models.
|
||||
TorchScript, a key part of the PyTorch ecosystem, provides powerful features for optimizing and deploying deep learning models.
|
||||
|
||||
|
||||
|
||||
|
|
@ -32,11 +32,11 @@ Here are the key features that make TorchScript a valuable tool for developers:
|
|||
|
||||
- **Static Graph Execution**: TorchScript uses a static graph representation of the model’s computation, which is different from PyTorch’s dynamic graph execution. In static graph execution, the computational graph is defined and compiled once before the actual execution, resulting in improved performance during inference.
|
||||
|
||||
- **Model Serialization**: TorchScript allows you to serialize PyTorch models into a platform-independent format. Serialized models can be loaded without requiring the original Python code, enabling deployment in different runtime environments.
|
||||
- **Model Serialization**: TorchScript allows you to serialize PyTorch models into a platform-independent format. Serialized models can be loaded without requiring the original Python code, enabling deployment in different runtime environments.
|
||||
|
||||
- **JIT Compilation**: TorchScript uses Just-In-Time (JIT) compilation to convert PyTorch models into an optimized intermediate representation. JIT compiles the model’s computational graph, enabling efficient execution on target devices.
|
||||
- **JIT Compilation**: TorchScript uses Just-In-Time (JIT) compilation to convert PyTorch models into an optimized intermediate representation. JIT compiles the model’s computational graph, enabling efficient execution on target devices.
|
||||
|
||||
- **Cross-Language Integration**: With TorchScript, you can export PyTorch models to other languages such as C++, Java, and JavaScript. This makes it easier to integrate PyTorch models into existing software systems written in different languages.
|
||||
- **Cross-Language Integration**: With TorchScript, you can export PyTorch models to other languages such as C++, Java, and JavaScript. This makes it easier to integrate PyTorch models into existing software systems written in different languages.
|
||||
|
||||
- **Gradual Conversion**: TorchScript provides a gradual conversion approach, allowing you to incrementally convert parts of your PyTorch model into TorchScript. This flexibility is particularly useful when dealing with complex models or when you want to optimize specific portions of the code.
|
||||
|
||||
|
|
@ -73,7 +73,7 @@ For detailed instructions and best practices related to the installation process
|
|||
|
||||
### Usage
|
||||
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models]((../models/index.md)) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md).
|
||||
|
||||
!!! Example "Usage"
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue