diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 615ef41f..2fbfd3f5 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -1,96 +1,132 @@
-# Contributing to YOLOv8 🚀
+---
+comments: true
+description: Learn how to contribute to Ultralytics YOLO projects – guidelines for pull requests, reporting bugs, code conduct and CLA signing.
+keywords: Ultralytics, YOLO, open-source, contribute, pull request, bug report, coding guidelines, CLA, code of conduct, GitHub
+---
-We love your input! We want to make contributing to YOLOv8 as easy and transparent as possible, whether it's:
+# Contributing to Ultralytics Open-Source YOLO Repositories
-- Reporting a bug
-- Discussing the current state of the code
-- Submitting a fix
-- Proposing a new feature
-- Becoming a maintainer
+First of all, thank you for your interest in contributing to Ultralytics open-source YOLO repositories! Your contributions will help improve the project and benefit the community. This document provides guidelines and best practices to get you started.
-YOLOv8 works so well due to our combined community effort, and for every small improvement you contribute you will be helping push the frontiers of what's possible in AI 😃!
+## Table of Contents
-## Submitting a Pull Request (PR) 🛠️
+1. [Code of Conduct](#code-of-conduct)
+2. [Contributing via Pull Requests](#contributing-via-pull-requests)
+ - [CLA Signing](#cla-signing)
+ - [Google-Style Docstrings](#google-style-docstrings)
+ - [GitHub Actions CI Tests](#github-actions-ci-tests)
+3. [Reporting Bugs](#reporting-bugs)
+4. [License](#license)
+5. [Conclusion](#conclusion)
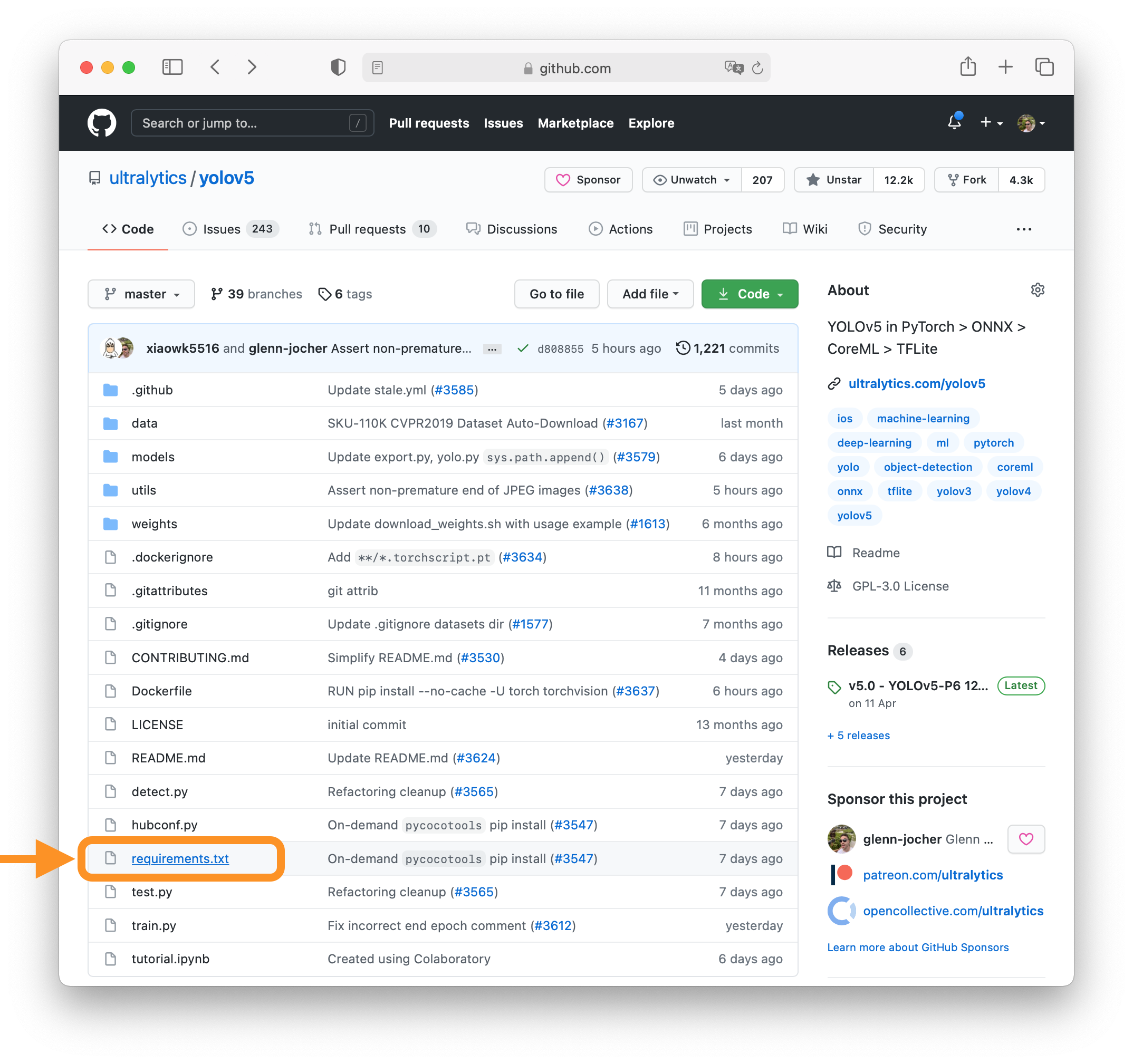
-Submitting a PR is easy! This example shows how to submit a PR for updating `requirements.txt` in 4 steps:
+## Code of Conduct
-### 1. Select File to Update
+All contributors are expected to adhere to the [Code of Conduct](https://docs.ultralytics.com/help/code_of_conduct/) to ensure a welcoming and inclusive environment for everyone.
-Select `requirements.txt` to update by clicking on it in GitHub.
+## Contributing via Pull Requests
-
+We welcome contributions in the form of pull requests. To make the review process smoother, please follow these guidelines:
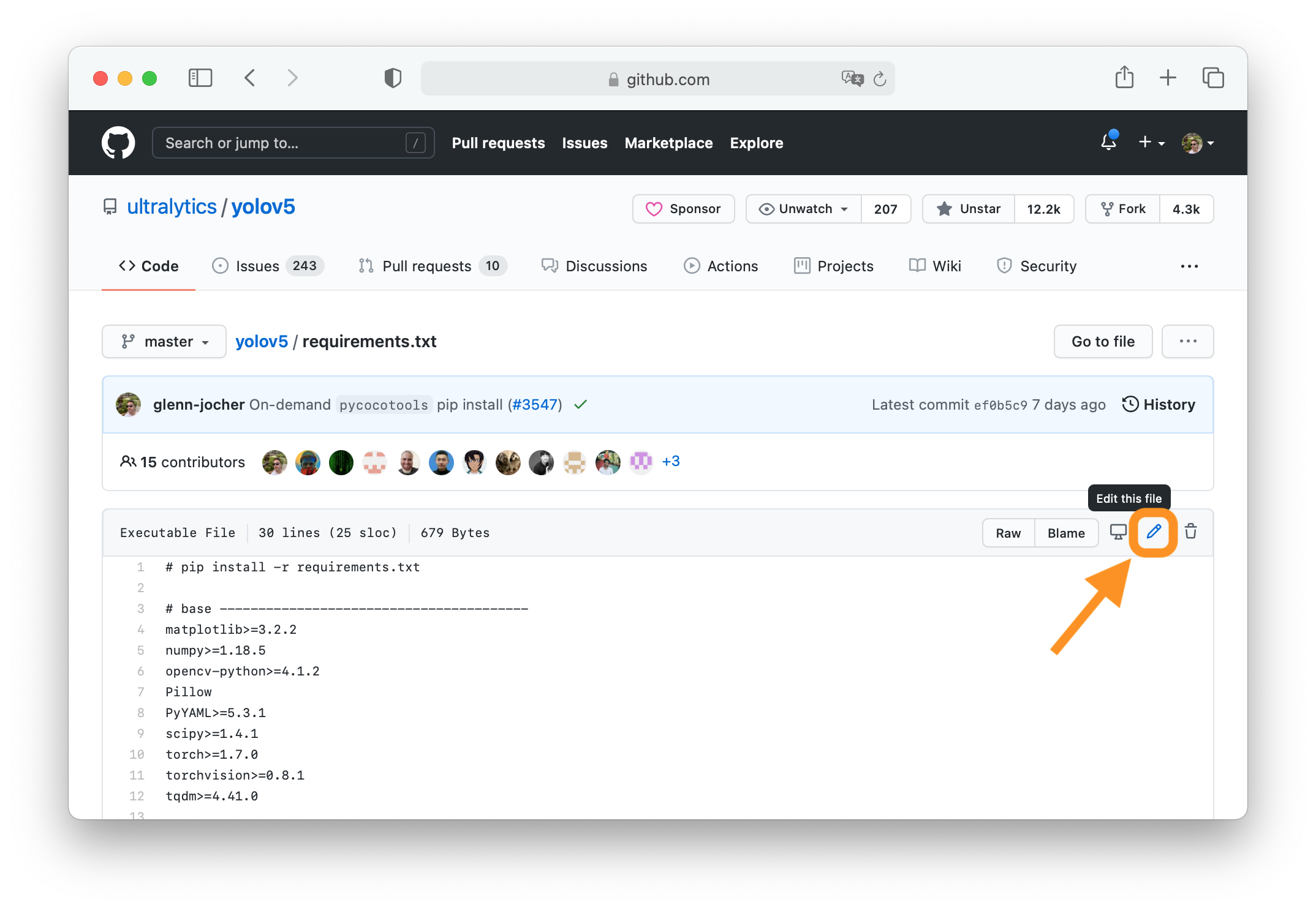
-### 2. Click 'Edit this file'
+1. **[Fork the repository](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/fork-a-repo)**: Fork the Ultralytics YOLO repository to your own GitHub account.
-Button is in top-right corner.
+2. **[Create a branch](https://docs.github.com/en/desktop/making-changes-in-a-branch/managing-branches-in-github-desktop)**: Create a new branch in your forked repository with a descriptive name for your changes.
-
+3. **Make your changes**: Make the changes you want to contribute. Ensure that your changes follow the coding style of the project and do not introduce new errors or warnings.
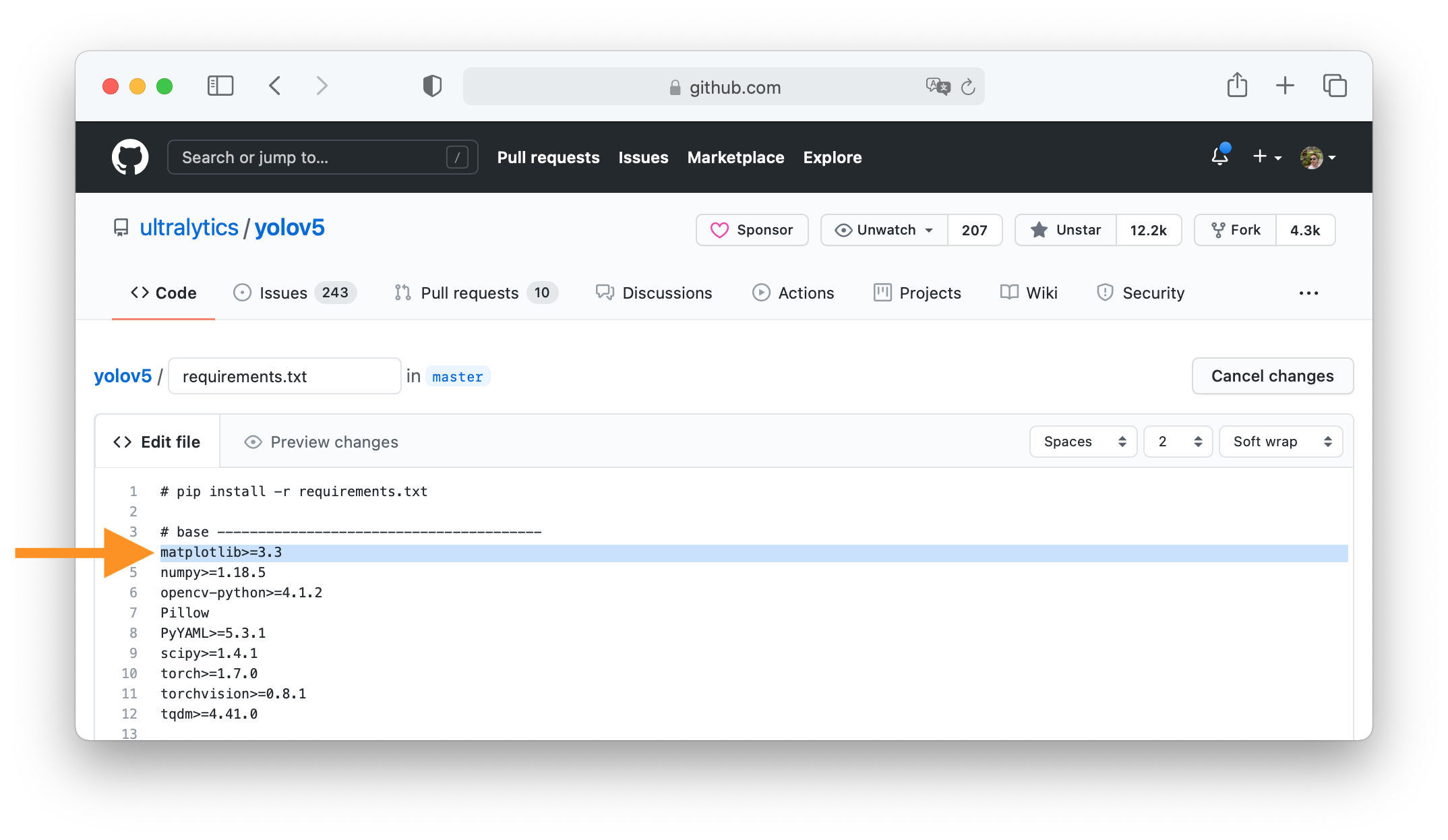
-### 3. Make Changes
+4. **[Test your changes](https://github.com/ultralytics/ultralytics/tree/main/tests)**: Test your changes locally to ensure that they work as expected and do not introduce new issues.
-Change `matplotlib` version from `3.2.2` to `3.3`.
+5. **[Commit your changes](https://docs.github.com/en/desktop/making-changes-in-a-branch/committing-and-reviewing-changes-to-your-project-in-github-desktop)**: Commit your changes with a descriptive commit message. Make sure to include any relevant issue numbers in your commit message.
-
+6. **[Create a pull request](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request)**: Create a pull request from your forked repository to the main Ultralytics YOLO repository. In the pull request description, provide a clear explanation of your changes and how they improve the project.
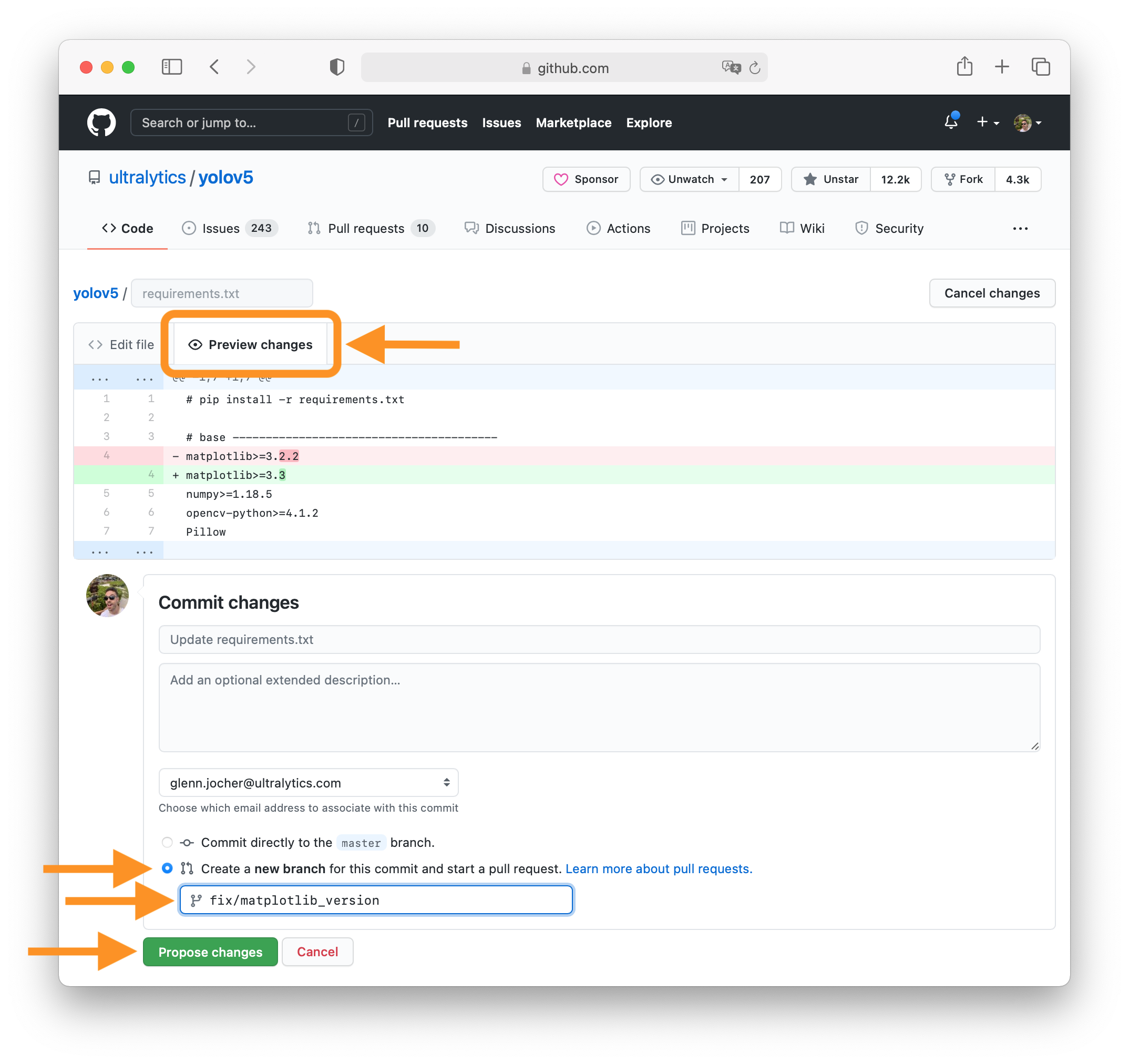
-### 4. Preview Changes and Submit PR
+### CLA Signing
-Click on the **Preview changes** tab to verify your updates. At the bottom of the screen select 'Create a **new branch** for this commit', assign your branch a descriptive name such as `fix/matplotlib_version` and click the green **Propose changes** button. All done, your PR is now submitted to YOLOv8 for review and approval 😃!
+Before we can accept your pull request, you need to sign a [Contributor License Agreement (CLA)](https://docs.ultralytics.com/help/CLA/). This is a legal document stating that you agree to the terms of contributing to the Ultralytics YOLO repositories. The CLA ensures that your contributions are properly licensed and that the project can continue to be distributed under the AGPL-3.0 license.
-
+To sign the CLA, follow the instructions provided by the CLA bot after you submit your PR and add a comment in your PR saying:
-### PR recommendations
-
-To allow your work to be integrated as seamlessly as possible, we advise you to:
-
-- ✅ Verify your PR is **up-to-date** with `ultralytics/ultralytics` `main` branch. If your PR is behind you can update your code by clicking the 'Update branch' button or by running `git pull` and `git merge main` locally.
-
-
-
-- ✅ Verify all YOLOv8 Continuous Integration (CI) **checks are passing**.
-
-
-
-- ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
-
-### Docstrings
-
-Not all functions or classes require docstrings but when they do, we follow [google-style docstrings format](https://google.github.io/styleguide/pyguide.html#38-comments-and-docstrings). Here is an example:
-
-```python
-"""
- What the function does. Performs NMS on given detection predictions.
-
- Args:
- arg1: The description of the 1st argument
- arg2: The description of the 2nd argument
-
- Returns:
- What the function returns. Empty if nothing is returned.
-
- Raises:
- Exception Class: When and why this exception can be raised by the function.
-"""
+```
+I have read the CLA Document and I sign the CLA
```
-## Submitting a Bug Report 🐛
+### Google-Style Docstrings
-If you spot a problem with YOLOv8 please submit a Bug Report!
+When adding new functions or classes, please include a [Google-style docstring](https://google.github.io/styleguide/pyguide.html) to provide clear and concise documentation for other developers. This will help ensure that your contributions are easy to understand and maintain.
-For us to start investigating a possible problem we need to be able to reproduce it ourselves first. We've created a few short guidelines below to help users provide what we need in order to get started.
+#### Google-style
-When asking a question, people will be better able to provide help if you provide **code** that they can easily understand and use to **reproduce** the problem. This is referred to by community members as creating a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/). Your code that reproduces the problem should be:
+This example shows a Google-style docstring. Note that both input and output `types` must always be enclosed by parentheses, i.e. `(bool)`.
-- ✅ **Minimal** – Use as little code as possible that still produces the same problem
-- ✅ **Complete** – Provide **all** parts someone else needs to reproduce your problem in the question itself
-- ✅ **Reproducible** – Test the code you're about to provide to make sure it reproduces the problem
+```python
+def example_function(arg1, arg2=4):
+ """
+ Example function that demonstrates Google-style docstrings.
-In addition to the above requirements, for [Ultralytics](https://ultralytics.com/) to provide assistance your code should be:
+ Args:
+ arg1 (int): The first argument.
+ arg2 (int): The second argument. Default value is 4.
-- ✅ **Current** – Verify that your code is up-to-date with current GitHub [main](https://github.com/ultralytics/ultralytics/tree/main) branch, and if necessary `git pull` or `git clone` a new copy to ensure your problem has not already been resolved by previous commits.
-- ✅ **Unmodified** – Your problem must be reproducible without any modifications to the codebase in this repository. [Ultralytics](https://ultralytics.com/) does not provide support for custom code ⚠️.
+ Returns:
+ (bool): True if successful, False otherwise.
-If you believe your problem meets all of the above criteria, please close this issue and raise a new one using the 🐛 **Bug Report** [template](https://github.com/ultralytics/ultralytics/issues/new/choose) and providing a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) to help us better understand and diagnose your problem.
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+```
+
+#### Google-style with type hints
+
+This example shows both a Google-style docstring and argument and return type hints, though both are not required, one can be used without the other.
+
+```python
+def example_function(arg1: int, arg2: int = 4) -> bool:
+ """
+ Example function that demonstrates Google-style docstrings.
+
+ Args:
+ arg1: The first argument.
+ arg2: The second argument. Default value is 4.
+
+ Returns:
+ True if successful, False otherwise.
+
+ Examples:
+ >>> result = example_function(1, 2) # returns False
+ """
+ if arg1 == arg2:
+ return True
+ return False
+```
+
+#### Single-line
+
+Smaller or simpler functions can utilize a single-line docstring. Note the docstring must use 3 double-quotes, and be a complete sentence starting with a capital letter and ending with a period.
+
+```python
+def example_small_function(arg1: int, arg2: int = 4) -> bool:
+ """Example function that demonstrates a single-line docstring."""
+ return arg1 == arg2
+```
+
+### GitHub Actions CI Tests
+
+Before your pull request can be merged, all GitHub Actions [Continuous Integration](https://docs.ultralytics.com/help/CI/) (CI) tests must pass. These tests include linting, unit tests, and other checks to ensure that your changes meet the quality standards of the project. Make sure to review the output of the GitHub Actions and fix any issues
+
+## Reporting Bugs
+
+We appreciate bug reports as they play a crucial role in maintaining the project's quality. When reporting bugs it is important to provide a [Minimum Reproducible Example](https://docs.ultralytics.com/help/minimum_reproducible_example/): a clear, concise code example that replicates the issue. This helps in quick identification and resolution of the bug.
## License
-By contributing, you agree that your contributions will be licensed under the [AGPL-3.0 license](https://choosealicense.com/licenses/agpl-3.0/)
+Ultralytics embraces the [GNU Affero General Public License v3.0 (AGPL-3.0)](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) for its repositories, promoting openness, transparency, and collaborative enhancement in software development. This strong copyleft license ensures that all users and developers retain the freedom to use, modify, and share the software. It fosters community collaboration, ensuring that any improvements remain accessible to all.
+
+Users and developers are encouraged to familiarize themselves with the terms of AGPL-3.0 to contribute effectively and ethically to the Ultralytics open-source community.
+
+## Conclusion
+
+Thank you for your interest in contributing to [Ultralytics open-source](https://github.com/ultralytics) YOLO projects. Your participation is crucial in shaping the future of our software and fostering a community of innovation and collaboration. Whether you're improving code, reporting bugs, or suggesting features, your contributions make a significant impact.
+
+We're eager to see your ideas in action and appreciate your commitment to advancing object detection technology. Let's continue to grow and innovate together in this exciting open-source journey. Happy coding! 🚀🌟
diff --git a/docs/en/datasets/classify/caltech101.md b/docs/en/datasets/classify/caltech101.md
index 635e9c5a..5415fb2e 100644
--- a/docs/en/datasets/classify/caltech101.md
+++ b/docs/en/datasets/classify/caltech101.md
@@ -36,10 +36,10 @@ To train a YOLO model on the Caltech-101 dataset for 100 epochs, you can use the
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='caltech101', epochs=100, imgsz=416)
+ results = model.train(data="caltech101", epochs=100, imgsz=416)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/caltech256.md b/docs/en/datasets/classify/caltech256.md
index 26a0414e..b84bfabc 100644
--- a/docs/en/datasets/classify/caltech256.md
+++ b/docs/en/datasets/classify/caltech256.md
@@ -36,10 +36,10 @@ To train a YOLO model on the Caltech-256 dataset for 100 epochs, you can use the
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='caltech256', epochs=100, imgsz=416)
+ results = model.train(data="caltech256", epochs=100, imgsz=416)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/cifar10.md b/docs/en/datasets/classify/cifar10.md
index fbca09a8..7d5f304a 100644
--- a/docs/en/datasets/classify/cifar10.md
+++ b/docs/en/datasets/classify/cifar10.md
@@ -39,10 +39,10 @@ To train a YOLO model on the CIFAR-10 dataset for 100 epochs with an image size
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='cifar10', epochs=100, imgsz=32)
+ results = model.train(data="cifar10", epochs=100, imgsz=32)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/cifar100.md b/docs/en/datasets/classify/cifar100.md
index 7c539f41..87dfcead 100644
--- a/docs/en/datasets/classify/cifar100.md
+++ b/docs/en/datasets/classify/cifar100.md
@@ -39,10 +39,10 @@ To train a YOLO model on the CIFAR-100 dataset for 100 epochs with an image size
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='cifar100', epochs=100, imgsz=32)
+ results = model.train(data="cifar100", epochs=100, imgsz=32)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/fashion-mnist.md b/docs/en/datasets/classify/fashion-mnist.md
index cbdec542..6627be20 100644
--- a/docs/en/datasets/classify/fashion-mnist.md
+++ b/docs/en/datasets/classify/fashion-mnist.md
@@ -53,10 +53,10 @@ To train a CNN model on the Fashion-MNIST dataset for 100 epochs with an image s
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='fashion-mnist', epochs=100, imgsz=28)
+ results = model.train(data="fashion-mnist", epochs=100, imgsz=28)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/imagenet.md b/docs/en/datasets/classify/imagenet.md
index 2d977c2f..eba7f9fc 100644
--- a/docs/en/datasets/classify/imagenet.md
+++ b/docs/en/datasets/classify/imagenet.md
@@ -49,10 +49,10 @@ To train a deep learning model on the ImageNet dataset for 100 epochs with an im
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='imagenet', epochs=100, imgsz=224)
+ results = model.train(data="imagenet", epochs=100, imgsz=224)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/imagenet10.md b/docs/en/datasets/classify/imagenet10.md
index 9999e0b7..d94f776d 100644
--- a/docs/en/datasets/classify/imagenet10.md
+++ b/docs/en/datasets/classify/imagenet10.md
@@ -35,10 +35,10 @@ To test a deep learning model on the ImageNet10 dataset with an image size of 22
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='imagenet10', epochs=5, imgsz=224)
+ results = model.train(data="imagenet10", epochs=5, imgsz=224)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/imagenette.md b/docs/en/datasets/classify/imagenette.md
index df34c509..8f81b185 100644
--- a/docs/en/datasets/classify/imagenette.md
+++ b/docs/en/datasets/classify/imagenette.md
@@ -37,10 +37,10 @@ To train a model on the ImageNette dataset for 100 epochs with a standard image
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='imagenette', epochs=100, imgsz=224)
+ results = model.train(data="imagenette", epochs=100, imgsz=224)
```
=== "CLI"
@@ -72,10 +72,10 @@ To use these datasets, simply replace 'imagenette' with 'imagenette160' or 'imag
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model with ImageNette160
- results = model.train(data='imagenette160', epochs=100, imgsz=160)
+ results = model.train(data="imagenette160", epochs=100, imgsz=160)
```
=== "CLI"
@@ -93,10 +93,10 @@ To use these datasets, simply replace 'imagenette' with 'imagenette160' or 'imag
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model with ImageNette320
- results = model.train(data='imagenette320', epochs=100, imgsz=320)
+ results = model.train(data="imagenette320", epochs=100, imgsz=320)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/imagewoof.md b/docs/en/datasets/classify/imagewoof.md
index f3613d43..f1b9836a 100644
--- a/docs/en/datasets/classify/imagewoof.md
+++ b/docs/en/datasets/classify/imagewoof.md
@@ -34,10 +34,10 @@ To train a CNN model on the ImageWoof dataset for 100 epochs with an image size
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='imagewoof', epochs=100, imgsz=224)
+ results = model.train(data="imagewoof", epochs=100, imgsz=224)
```
=== "CLI"
@@ -63,13 +63,13 @@ To use these variants in your training, simply replace 'imagewoof' in the datase
from ultralytics import YOLO
# Load a model
-model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# For medium-sized dataset
-model.train(data='imagewoof320', epochs=100, imgsz=224)
+model.train(data="imagewoof320", epochs=100, imgsz=224)
# For small-sized dataset
-model.train(data='imagewoof160', epochs=100, imgsz=224)
+model.train(data="imagewoof160", epochs=100, imgsz=224)
```
It's important to note that using smaller images will likely yield lower performance in terms of classification accuracy. However, it's an excellent way to iterate quickly in the early stages of model development and prototyping.
diff --git a/docs/en/datasets/classify/index.md b/docs/en/datasets/classify/index.md
index 44a412c4..e45752e5 100644
--- a/docs/en/datasets/classify/index.md
+++ b/docs/en/datasets/classify/index.md
@@ -86,10 +86,10 @@ This structured approach ensures that the model can effectively learn from well-
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='path/to/dataset', epochs=100, imgsz=640)
+ results = model.train(data="path/to/dataset", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/classify/mnist.md b/docs/en/datasets/classify/mnist.md
index 355ab5b2..6632f2e5 100644
--- a/docs/en/datasets/classify/mnist.md
+++ b/docs/en/datasets/classify/mnist.md
@@ -42,10 +42,10 @@ To train a CNN model on the MNIST dataset for 100 epochs with an image size of 3
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='mnist', epochs=100, imgsz=32)
+ results = model.train(data="mnist", epochs=100, imgsz=32)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/african-wildlife.md b/docs/en/datasets/detect/african-wildlife.md
index 586df884..97a19f05 100644
--- a/docs/en/datasets/detect/african-wildlife.md
+++ b/docs/en/datasets/detect/african-wildlife.md
@@ -42,10 +42,10 @@ To train a YOLOv8n model on the African wildlife dataset for 100 epochs with an
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='african-wildlife.yaml', epochs=100, imgsz=640)
+ results = model.train(data="african-wildlife.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -63,7 +63,7 @@ To train a YOLOv8n model on the African wildlife dataset for 100 epochs with an
from ultralytics import YOLO
# Load a model
- model = YOLO('path/to/best.pt') # load a brain-tumor fine-tuned model
+ model = YOLO("path/to/best.pt") # load a brain-tumor fine-tuned model
# Inference using the model
results = model.predict("https://ultralytics.com/assets/african-wildlife-sample.jpg")
diff --git a/docs/en/datasets/detect/argoverse.md b/docs/en/datasets/detect/argoverse.md
index cf9e4894..d2b8c79e 100644
--- a/docs/en/datasets/detect/argoverse.md
+++ b/docs/en/datasets/detect/argoverse.md
@@ -53,10 +53,10 @@ To train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image s
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='Argoverse.yaml', epochs=100, imgsz=640)
+ results = model.train(data="Argoverse.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/brain-tumor.md b/docs/en/datasets/detect/brain-tumor.md
index 695e1ec2..527807fe 100644
--- a/docs/en/datasets/detect/brain-tumor.md
+++ b/docs/en/datasets/detect/brain-tumor.md
@@ -52,10 +52,10 @@ To train a YOLOv8n model on the brain tumor dataset for 100 epochs with an image
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='brain-tumor.yaml', epochs=100, imgsz=640)
+ results = model.train(data="brain-tumor.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -73,7 +73,7 @@ To train a YOLOv8n model on the brain tumor dataset for 100 epochs with an image
from ultralytics import YOLO
# Load a model
- model = YOLO('path/to/best.pt') # load a brain-tumor fine-tuned model
+ model = YOLO("path/to/best.pt") # load a brain-tumor fine-tuned model
# Inference using the model
results = model.predict("https://ultralytics.com/assets/brain-tumor-sample.jpg")
diff --git a/docs/en/datasets/detect/coco.md b/docs/en/datasets/detect/coco.md
index 36b4cc66..e12de638 100644
--- a/docs/en/datasets/detect/coco.md
+++ b/docs/en/datasets/detect/coco.md
@@ -70,10 +70,10 @@ To train a YOLOv8n model on the COCO dataset for 100 epochs with an image size o
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/coco8.md b/docs/en/datasets/detect/coco8.md
index dd4070ee..f48275dc 100644
--- a/docs/en/datasets/detect/coco8.md
+++ b/docs/en/datasets/detect/coco8.md
@@ -45,10 +45,10 @@ To train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/globalwheat2020.md b/docs/en/datasets/detect/globalwheat2020.md
index 7936ef2c..4b9362bf 100644
--- a/docs/en/datasets/detect/globalwheat2020.md
+++ b/docs/en/datasets/detect/globalwheat2020.md
@@ -48,10 +48,10 @@ To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='GlobalWheat2020.yaml', epochs=100, imgsz=640)
+ results = model.train(data="GlobalWheat2020.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/index.md b/docs/en/datasets/detect/index.md
index 2e027906..508120ab 100644
--- a/docs/en/datasets/detect/index.md
+++ b/docs/en/datasets/detect/index.md
@@ -56,10 +56,10 @@ Here's how you can use these formats to train your model:
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -103,7 +103,7 @@ You can easily convert labels from the popular COCO dataset format to the YOLO f
```python
from ultralytics.data.converter import convert_coco
- convert_coco(labels_dir='path/to/coco/annotations/')
+ convert_coco(labels_dir="path/to/coco/annotations/")
```
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
diff --git a/docs/en/datasets/detect/lvis.md b/docs/en/datasets/detect/lvis.md
index 21c51df3..eb156f78 100644
--- a/docs/en/datasets/detect/lvis.md
+++ b/docs/en/datasets/detect/lvis.md
@@ -66,10 +66,10 @@ To train a YOLOv8n model on the LVIS dataset for 100 epochs with an image size o
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='lvis.yaml', epochs=100, imgsz=640)
+ results = model.train(data="lvis.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/objects365.md b/docs/en/datasets/detect/objects365.md
index fbc9fe66..0a9a3abb 100644
--- a/docs/en/datasets/detect/objects365.md
+++ b/docs/en/datasets/detect/objects365.md
@@ -48,10 +48,10 @@ To train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='Objects365.yaml', epochs=100, imgsz=640)
+ results = model.train(data="Objects365.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/open-images-v7.md b/docs/en/datasets/detect/open-images-v7.md
index 460f6aed..6b73d61f 100644
--- a/docs/en/datasets/detect/open-images-v7.md
+++ b/docs/en/datasets/detect/open-images-v7.md
@@ -88,10 +88,10 @@ To train a YOLOv8n model on the Open Images V7 dataset for 100 epochs with an im
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Train the model on the Open Images V7 dataset
- results = model.train(data='open-images-v7.yaml', epochs=100, imgsz=640)
+ results = model.train(data="open-images-v7.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/roboflow-100.md b/docs/en/datasets/detect/roboflow-100.md
index 3ca3e4f1..9d17fbc0 100644
--- a/docs/en/datasets/detect/roboflow-100.md
+++ b/docs/en/datasets/detect/roboflow-100.md
@@ -46,39 +46,40 @@ Dataset benchmarking evaluates machine learning model performance on specific da
=== "Python"
```python
- from pathlib import Path
- import shutil
import os
+ import shutil
+ from pathlib import Path
+
from ultralytics.utils.benchmarks import RF100Benchmark
-
+
# Initialize RF100Benchmark and set API key
benchmark = RF100Benchmark()
benchmark.set_key(api_key="YOUR_ROBOFLOW_API_KEY")
-
+
# Parse dataset and define file paths
names, cfg_yamls = benchmark.parse_dataset()
val_log_file = Path("ultralytics-benchmarks") / "validation.txt"
eval_log_file = Path("ultralytics-benchmarks") / "evaluation.txt"
-
+
# Run benchmarks on each dataset in RF100
for ind, path in enumerate(cfg_yamls):
path = Path(path)
if path.exists():
# Fix YAML file and run training
benchmark.fix_yaml(str(path))
- os.system(f'yolo detect train data={path} model=yolov8s.pt epochs=1 batch=16')
-
+ os.system(f"yolo detect train data={path} model=yolov8s.pt epochs=1 batch=16")
+
# Run validation and evaluate
- os.system(f'yolo detect val data={path} model=runs/detect/train/weights/best.pt > {val_log_file} 2>&1')
+ os.system(f"yolo detect val data={path} model=runs/detect/train/weights/best.pt > {val_log_file} 2>&1")
benchmark.evaluate(str(path), str(val_log_file), str(eval_log_file), ind)
-
+
# Remove the 'runs' directory
runs_dir = Path.cwd() / "runs"
shutil.rmtree(runs_dir)
else:
print("YAML file path does not exist")
continue
-
+
print("RF100 Benchmarking completed!")
```
diff --git a/docs/en/datasets/detect/sku-110k.md b/docs/en/datasets/detect/sku-110k.md
index f8ca58d8..a74e5fb5 100644
--- a/docs/en/datasets/detect/sku-110k.md
+++ b/docs/en/datasets/detect/sku-110k.md
@@ -50,10 +50,10 @@ To train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image si
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='SKU-110K.yaml', epochs=100, imgsz=640)
+ results = model.train(data="SKU-110K.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/visdrone.md b/docs/en/datasets/detect/visdrone.md
index 24d8db21..8344d018 100644
--- a/docs/en/datasets/detect/visdrone.md
+++ b/docs/en/datasets/detect/visdrone.md
@@ -46,10 +46,10 @@ To train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image si
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='VisDrone.yaml', epochs=100, imgsz=640)
+ results = model.train(data="VisDrone.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/voc.md b/docs/en/datasets/detect/voc.md
index eb298f9a..aaded124 100644
--- a/docs/en/datasets/detect/voc.md
+++ b/docs/en/datasets/detect/voc.md
@@ -49,10 +49,10 @@ To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='VOC.yaml', epochs=100, imgsz=640)
+ results = model.train(data="VOC.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/detect/xview.md b/docs/en/datasets/detect/xview.md
index f2d35280..7c62db62 100644
--- a/docs/en/datasets/detect/xview.md
+++ b/docs/en/datasets/detect/xview.md
@@ -52,10 +52,10 @@ To train a model on the xView dataset for 100 epochs with an image size of 640,
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='xView.yaml', epochs=100, imgsz=640)
+ results = model.train(data="xView.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/explorer/api.md b/docs/en/datasets/explorer/api.md
index 0aa60034..bc5c601c 100644
--- a/docs/en/datasets/explorer/api.md
+++ b/docs/en/datasets/explorer/api.md
@@ -36,13 +36,13 @@ pip install ultralytics[explorer]
from ultralytics import Explorer
# Create an Explorer object
-explorer = Explorer(data='coco128.yaml', model='yolov8n.pt')
+explorer = Explorer(data="coco128.yaml", model="yolov8n.pt")
# Create embeddings for your dataset
explorer.create_embeddings_table()
# Search for similar images to a given image/images
-dataframe = explorer.get_similar(img='path/to/image.jpg')
+dataframe = explorer.get_similar(img="path/to/image.jpg")
# Or search for similar images to a given index/indices
dataframe = explorer.get_similar(idx=0)
@@ -75,18 +75,17 @@ You get a pandas dataframe with the `limit` number of most similar data points t
from ultralytics import Explorer
# create an Explorer object
- exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
- similar = exp.get_similar(img='https://ultralytics.com/images/bus.jpg', limit=10)
+ similar = exp.get_similar(img="https://ultralytics.com/images/bus.jpg", limit=10)
print(similar.head())
# Search using multiple indices
similar = exp.get_similar(
- img=['https://ultralytics.com/images/bus.jpg',
- 'https://ultralytics.com/images/bus.jpg'],
- limit=10
- )
+ img=["https://ultralytics.com/images/bus.jpg", "https://ultralytics.com/images/bus.jpg"],
+ limit=10,
+ )
print(similar.head())
```
@@ -96,14 +95,14 @@ You get a pandas dataframe with the `limit` number of most similar data points t
from ultralytics import Explorer
# create an Explorer object
- exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
similar = exp.get_similar(idx=1, limit=10)
print(similar.head())
# Search using multiple indices
- similar = exp.get_similar(idx=[1,10], limit=10)
+ similar = exp.get_similar(idx=[1, 10], limit=10)
print(similar.head())
```
@@ -119,10 +118,10 @@ You can also plot the similar images using the `plot_similar` method. This metho
from ultralytics import Explorer
# create an Explorer object
- exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
- plt = exp.plot_similar(img='https://ultralytics.com/images/bus.jpg', limit=10)
+ plt = exp.plot_similar(img="https://ultralytics.com/images/bus.jpg", limit=10)
plt.show()
```
@@ -132,7 +131,7 @@ You can also plot the similar images using the `plot_similar` method. This metho
from ultralytics import Explorer
# create an Explorer object
- exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
plt = exp.plot_similar(idx=1, limit=10)
@@ -150,9 +149,8 @@ Note: This works using LLMs under the hood so the results are probabilistic and
from ultralytics import Explorer
from ultralytics.data.explorer import plot_query_result
-
# create an Explorer object
- exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
df = exp.ask_ai("show me 100 images with exactly one person and 2 dogs. There can be other objects too")
@@ -173,7 +171,7 @@ You can run SQL queries on your dataset using the `sql_query` method. This metho
from ultralytics import Explorer
# create an Explorer object
- exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
df = exp.sql_query("WHERE labels LIKE '%person%' AND labels LIKE '%dog%'")
@@ -190,7 +188,7 @@ You can also plot the results of a SQL query using the `plot_sql_query` method.
from ultralytics import Explorer
# create an Explorer object
- exp = Explorer(data='coco128.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco128.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
# plot the SQL Query
@@ -293,7 +291,7 @@ You can use similarity index to build custom conditions to filter out the datase
import numpy as np
sim_count = np.array(sim_idx["count"])
-sim_idx['im_file'][sim_count > 30]
+sim_idx["im_file"][sim_count > 30]
```
### Visualize Embedding Space
@@ -301,10 +299,10 @@ sim_idx['im_file'][sim_count > 30]
You can also visualize the embedding space using the plotting tool of your choice. For example here is a simple example using matplotlib:
```python
-import numpy as np
-from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
+import numpy as np
from mpl_toolkits.mplot3d import Axes3D
+from sklearn.decomposition import PCA
# Reduce dimensions using PCA to 3 components for visualization in 3D
pca = PCA(n_components=3)
@@ -312,14 +310,14 @@ reduced_data = pca.fit_transform(embeddings)
# Create a 3D scatter plot using Matplotlib Axes3D
fig = plt.figure(figsize=(8, 6))
-ax = fig.add_subplot(111, projection='3d')
+ax = fig.add_subplot(111, projection="3d")
# Scatter plot
ax.scatter(reduced_data[:, 0], reduced_data[:, 1], reduced_data[:, 2], alpha=0.5)
-ax.set_title('3D Scatter Plot of Reduced 256-Dimensional Data (PCA)')
-ax.set_xlabel('Component 1')
-ax.set_ylabel('Component 2')
-ax.set_zlabel('Component 3')
+ax.set_title("3D Scatter Plot of Reduced 256-Dimensional Data (PCA)")
+ax.set_xlabel("Component 1")
+ax.set_ylabel("Component 2")
+ax.set_zlabel("Component 3")
plt.show()
```
diff --git a/docs/en/datasets/index.md b/docs/en/datasets/index.md
index db27ba82..f39eaded 100644
--- a/docs/en/datasets/index.md
+++ b/docs/en/datasets/index.md
@@ -135,14 +135,15 @@ Contributing a new dataset involves several steps to ensure that it aligns well
```python
from pathlib import Path
+
from ultralytics.data.utils import compress_one_image
from ultralytics.utils.downloads import zip_directory
# Define dataset directory
- path = Path('path/to/dataset')
+ path = Path("path/to/dataset")
# Optimize images in dataset (optional)
- for f in path.rglob('*.jpg'):
+ for f in path.rglob("*.jpg"):
compress_one_image(f)
# Zip dataset into 'path/to/dataset.zip'
diff --git a/docs/en/datasets/obb/dota-v2.md b/docs/en/datasets/obb/dota-v2.md
index 51502d78..abb4c0a3 100644
--- a/docs/en/datasets/obb/dota-v2.md
+++ b/docs/en/datasets/obb/dota-v2.md
@@ -75,21 +75,21 @@ To train DOTA dataset, we split original DOTA images with high-resolution into i
=== "Python"
```python
- from ultralytics.data.split_dota import split_trainval, split_test
+ from ultralytics.data.split_dota import split_test, split_trainval
# split train and val set, with labels.
split_trainval(
- data_root='path/to/DOTAv1.0/',
- save_dir='path/to/DOTAv1.0-split/',
- rates=[0.5, 1.0, 1.5], # multiscale
- gap=500
+ data_root="path/to/DOTAv1.0/",
+ save_dir="path/to/DOTAv1.0-split/",
+ rates=[0.5, 1.0, 1.5], # multiscale
+ gap=500,
)
# split test set, without labels.
split_test(
- data_root='path/to/DOTAv1.0/',
- save_dir='path/to/DOTAv1.0-split/',
- rates=[0.5, 1.0, 1.5], # multiscale
- gap=500
+ data_root="path/to/DOTAv1.0/",
+ save_dir="path/to/DOTAv1.0-split/",
+ rates=[0.5, 1.0, 1.5], # multiscale
+ gap=500,
)
```
@@ -109,10 +109,10 @@ To train a model on the DOTA v1 dataset, you can utilize the following code snip
from ultralytics import YOLO
# Create a new YOLOv8n-OBB model from scratch
- model = YOLO('yolov8n-obb.yaml')
+ model = YOLO("yolov8n-obb.yaml")
# Train the model on the DOTAv2 dataset
- results = model.train(data='DOTAv1.yaml', epochs=100, imgsz=640)
+ results = model.train(data="DOTAv1.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/obb/dota8.md b/docs/en/datasets/obb/dota8.md
index c246d6d2..73bb3e12 100644
--- a/docs/en/datasets/obb/dota8.md
+++ b/docs/en/datasets/obb/dota8.md
@@ -34,10 +34,10 @@ To train a YOLOv8n-obb model on the DOTA8 dataset for 100 epochs with an image s
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-obb.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-obb.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='dota8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="dota8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/obb/index.md b/docs/en/datasets/obb/index.md
index 835a3a9d..30b44244 100644
--- a/docs/en/datasets/obb/index.md
+++ b/docs/en/datasets/obb/index.md
@@ -40,10 +40,10 @@ To train a model using these OBB formats:
from ultralytics import YOLO
# Create a new YOLOv8n-OBB model from scratch
- model = YOLO('yolov8n-obb.yaml')
+ model = YOLO("yolov8n-obb.yaml")
# Train the model on the DOTAv2 dataset
- results = model.train(data='DOTAv1.yaml', epochs=100, imgsz=640)
+ results = model.train(data="DOTAv1.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -78,7 +78,7 @@ Transitioning labels from the DOTA dataset format to the YOLO OBB format can be
```python
from ultralytics.data.converter import convert_dota_to_yolo_obb
- convert_dota_to_yolo_obb('path/to/DOTA')
+ convert_dota_to_yolo_obb("path/to/DOTA")
```
This conversion mechanism is instrumental for datasets in the DOTA format, ensuring alignment with the Ultralytics YOLO OBB format.
diff --git a/docs/en/datasets/pose/coco.md b/docs/en/datasets/pose/coco.md
index d03b45dc..a45dfeef 100644
--- a/docs/en/datasets/pose/coco.md
+++ b/docs/en/datasets/pose/coco.md
@@ -61,10 +61,10 @@ To train a YOLOv8n-pose model on the COCO-Pose dataset for 100 epochs with an im
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco-pose.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco-pose.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/pose/coco8-pose.md b/docs/en/datasets/pose/coco8-pose.md
index 4a249716..2201721f 100644
--- a/docs/en/datasets/pose/coco8-pose.md
+++ b/docs/en/datasets/pose/coco8-pose.md
@@ -34,10 +34,10 @@ To train a YOLOv8n-pose model on the COCO8-Pose dataset for 100 epochs with an i
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/pose/index.md b/docs/en/datasets/pose/index.md
index 3b4ad540..89718e71 100644
--- a/docs/en/datasets/pose/index.md
+++ b/docs/en/datasets/pose/index.md
@@ -72,10 +72,10 @@ The `train` and `val` fields specify the paths to the directories containing the
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -132,7 +132,7 @@ Ultralytics provides a convenient conversion tool to convert labels from the pop
```python
from ultralytics.data.converter import convert_coco
- convert_coco(labels_dir='path/to/coco/annotations/', use_keypoints=True)
+ convert_coco(labels_dir="path/to/coco/annotations/", use_keypoints=True)
```
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format. The `use_keypoints` parameter specifies whether to include keypoints (for pose estimation) in the converted labels.
diff --git a/docs/en/datasets/pose/tiger-pose.md b/docs/en/datasets/pose/tiger-pose.md
index b4c33dd9..6fbeb607 100644
--- a/docs/en/datasets/pose/tiger-pose.md
+++ b/docs/en/datasets/pose/tiger-pose.md
@@ -47,10 +47,10 @@ To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 epochs with an i
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='tiger-pose.yaml', epochs=100, imgsz=640)
+ results = model.train(data="tiger-pose.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/segment/carparts-seg.md b/docs/en/datasets/segment/carparts-seg.md
index e5ffda58..ad261363 100644
--- a/docs/en/datasets/segment/carparts-seg.md
+++ b/docs/en/datasets/segment/carparts-seg.md
@@ -55,10 +55,10 @@ To train Ultralytics YOLOv8n model on the Carparts Segmentation dataset for 100
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='carparts-seg.yaml', epochs=100, imgsz=640)
+ results = model.train(data="carparts-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/segment/coco.md b/docs/en/datasets/segment/coco.md
index 599dfc2d..c478516d 100644
--- a/docs/en/datasets/segment/coco.md
+++ b/docs/en/datasets/segment/coco.md
@@ -59,10 +59,10 @@ To train a YOLOv8n-seg model on the COCO-Seg dataset for 100 epochs with an imag
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco-seg.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/segment/coco8-seg.md b/docs/en/datasets/segment/coco8-seg.md
index cc04a553..ff367aed 100644
--- a/docs/en/datasets/segment/coco8-seg.md
+++ b/docs/en/datasets/segment/coco8-seg.md
@@ -34,10 +34,10 @@ To train a YOLOv8n-seg model on the COCO8-Seg dataset for 100 epochs with an ima
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco8-seg.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/segment/crack-seg.md b/docs/en/datasets/segment/crack-seg.md
index 23fa9781..86898b22 100644
--- a/docs/en/datasets/segment/crack-seg.md
+++ b/docs/en/datasets/segment/crack-seg.md
@@ -44,10 +44,10 @@ To train Ultralytics YOLOv8n model on the Crack Segmentation dataset for 100 epo
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='crack-seg.yaml', epochs=100, imgsz=640)
+ results = model.train(data="crack-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/segment/index.md b/docs/en/datasets/segment/index.md
index 5cde021f..55b8d414 100644
--- a/docs/en/datasets/segment/index.md
+++ b/docs/en/datasets/segment/index.md
@@ -74,10 +74,10 @@ The `train` and `val` fields specify the paths to the directories containing the
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='coco8-seg.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -117,7 +117,7 @@ You can easily convert labels from the popular COCO dataset format to the YOLO f
```python
from ultralytics.data.converter import convert_coco
- convert_coco(labels_dir='path/to/coco/annotations/', use_segments=True)
+ convert_coco(labels_dir="path/to/coco/annotations/", use_segments=True)
```
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
@@ -139,7 +139,7 @@ To auto-annotate your dataset using the Ultralytics framework, you can use the `
```python
from ultralytics.data.annotator import auto_annotate
- auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model='sam_b.pt')
+ auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam_b.pt")
```
Certainly, here is the table updated with code snippets:
diff --git a/docs/en/datasets/segment/package-seg.md b/docs/en/datasets/segment/package-seg.md
index 037d3372..1265dabc 100644
--- a/docs/en/datasets/segment/package-seg.md
+++ b/docs/en/datasets/segment/package-seg.md
@@ -44,10 +44,10 @@ To train Ultralytics YOLOv8n model on the Package Segmentation dataset for 100 e
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
# Train the model
- results = model.train(data='package-seg.yaml', epochs=100, imgsz=640)
+ results = model.train(data="package-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
diff --git a/docs/en/datasets/track/index.md b/docs/en/datasets/track/index.md
index b5838397..68706e0a 100644
--- a/docs/en/datasets/track/index.md
+++ b/docs/en/datasets/track/index.md
@@ -19,7 +19,7 @@ Multi-Object Detector doesn't need standalone training and directly supports pre
```python
from ultralytics import YOLO
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
```
=== "CLI"
diff --git a/docs/en/guides/conda-quickstart.md b/docs/en/guides/conda-quickstart.md
index 51632207..a37780b3 100644
--- a/docs/en/guides/conda-quickstart.md
+++ b/docs/en/guides/conda-quickstart.md
@@ -70,8 +70,8 @@ With Ultralytics installed, you can now start using its robust features for obje
```python
from ultralytics import YOLO
-model = YOLO('yolov8n.pt') # initialize model
-results = model('path/to/image.jpg') # perform inference
+model = YOLO("yolov8n.pt") # initialize model
+results = model("path/to/image.jpg") # perform inference
results[0].show() # display results for the first image
```
diff --git a/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md b/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
index f1046637..1ed72b3e 100644
--- a/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
+++ b/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
@@ -82,10 +82,10 @@ To use the Edge TPU, you need to convert your model into a compatible format. It
from ultralytics import YOLO
# Load a model
- model = YOLO('path/to/model.pt') # Load an official model or custom model
+ model = YOLO("path/to/model.pt") # Load an official model or custom model
# Export the model
- model.export(format='edgetpu')
+ model.export(format="edgetpu")
```
=== "CLI"
@@ -108,7 +108,7 @@ After exporting your model, you can run inference with it using the following co
from ultralytics import YOLO
# Load a model
- model = YOLO('path/to/edgetpu_model.tflite') # Load an official model or custom model
+ model = YOLO("path/to/edgetpu_model.tflite") # Load an official model or custom model
# Run Prediction
model.predict("path/to/source.png")
diff --git a/docs/en/guides/distance-calculation.md b/docs/en/guides/distance-calculation.md
index 607ee6d4..8a5269f7 100644
--- a/docs/en/guides/distance-calculation.md
+++ b/docs/en/guides/distance-calculation.md
@@ -42,8 +42,8 @@ Measuring the gap between two objects is known as distance calculation within a
=== "Video Stream"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
model = YOLO("yolov8n.pt")
names = model.model.names
@@ -53,7 +53,7 @@ Measuring the gap between two objects is known as distance calculation within a
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Video writer
- video_writer = cv2.VideoWriter("distance_calculation.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ video_writer = cv2.VideoWriter("distance_calculation.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# Init distance-calculation obj
dist_obj = solutions.DistanceCalculation(names=names, view_img=True)
@@ -71,7 +71,6 @@ Measuring the gap between two objects is known as distance calculation within a
cap.release()
video_writer.release()
cv2.destroyAllWindows()
-
```
???+ tip "Note"
diff --git a/docs/en/guides/heatmaps.md b/docs/en/guides/heatmaps.md
index b2537185..4b3d77ac 100644
--- a/docs/en/guides/heatmaps.md
+++ b/docs/en/guides/heatmaps.md
@@ -44,8 +44,8 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
=== "Heatmap"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
@@ -53,13 +53,15 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Video writer
- video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# Init heatmap
- heatmap_obj = solutions.Heatmap(colormap=cv2.COLORMAP_PARULA,
- view_img=True,
- shape="circle",
- classes_names=model.names)
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ classes_names=model.names,
+ )
while cap.isOpened():
success, im0 = cap.read()
@@ -74,14 +76,13 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
cap.release()
video_writer.release()
cv2.destroyAllWindows()
-
```
=== "Line Counting"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
@@ -89,16 +90,18 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Video writer
- video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
line_points = [(20, 400), (1080, 404)] # line for object counting
# Init heatmap
- heatmap_obj = solutions.Heatmap(colormap=cv2.COLORMAP_PARULA,
- view_img=True,
- shape="circle",
- count_reg_pts=line_points,
- classes_names=model.names)
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ count_reg_pts=line_points,
+ classes_names=model.names,
+ )
while cap.isOpened():
success, im0 = cap.read()
@@ -117,30 +120,29 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
=== "Polygon Counting"
```python
- from ultralytics import YOLO, solutions
import cv2
-
+ from ultralytics import YOLO, solutions
+
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
-
+
# Video writer
- video_writer = cv2.VideoWriter("heatmap_output.avi",
- cv2.VideoWriter_fourcc(*'mp4v'),
- fps,
- (w, h))
-
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
# Define polygon points
region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360), (20, 400)]
-
+
# Init heatmap
- heatmap_obj = solutions.Heatmap(colormap=cv2.COLORMAP_PARULA,
- view_img=True,
- shape="circle",
- count_reg_pts=region_points,
- classes_names=model.names)
-
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ count_reg_pts=region_points,
+ classes_names=model.names,
+ )
+
while cap.isOpened():
success, im0 = cap.read()
if not success:
@@ -150,7 +152,7 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
tracks = model.track(im0, persist=True, show=False)
im0 = heatmap_obj.generate_heatmap(im0, tracks)
video_writer.write(im0)
-
+
cap.release()
video_writer.release()
cv2.destroyAllWindows()
@@ -159,8 +161,8 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
=== "Region Counting"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
@@ -168,24 +170,26 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Video writer
- video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# Define region points
region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
# Init heatmap
- heatmap_obj = solutions.Heatmap(colormap=cv2.COLORMAP_PARULA,
- view_img=True,
- shape="circle",
- count_reg_pts=region_points,
- classes_names=model.names)
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ count_reg_pts=region_points,
+ classes_names=model.names,
+ )
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
-
+
tracks = model.track(im0, persist=True, show=False)
im0 = heatmap_obj.generate_heatmap(im0, tracks)
video_writer.write(im0)
@@ -198,19 +202,21 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
=== "Im0"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
- model = YOLO("yolov8s.pt") # YOLOv8 custom/pretrained model
+ model = YOLO("yolov8s.pt") # YOLOv8 custom/pretrained model
im0 = cv2.imread("path/to/image.png") # path to image file
h, w = im0.shape[:2] # image height and width
-
+
# Heatmap Init
- heatmap_obj = solutions.Heatmap(colormap=cv2.COLORMAP_PARULA,
- view_img=True,
- shape="circle",
- classes_names=model.names)
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ classes_names=model.names,
+ )
results = model.track(im0, persist=True)
im0 = heatmap_obj.generate_heatmap(im0, tracks=results)
@@ -220,8 +226,8 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
=== "Specific Classes"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
@@ -229,23 +235,24 @@ A heatmap generated with [Ultralytics YOLOv8](https://github.com/ultralytics/ult
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Video writer
- video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ video_writer = cv2.VideoWriter("heatmap_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
classes_for_heatmap = [0, 2] # classes for heatmap
# Init heatmap
- heatmap_obj = solutions.Heatmap(colormap=cv2.COLORMAP_PARULA,
- view_img=True,
- shape="circle",
- classes_names=model.names)
+ heatmap_obj = solutions.Heatmap(
+ colormap=cv2.COLORMAP_PARULA,
+ view_img=True,
+ shape="circle",
+ classes_names=model.names,
+ )
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
- tracks = model.track(im0, persist=True, show=False,
- classes=classes_for_heatmap)
+ tracks = model.track(im0, persist=True, show=False, classes=classes_for_heatmap)
im0 = heatmap_obj.generate_heatmap(im0, tracks)
video_writer.write(im0)
diff --git a/docs/en/guides/hyperparameter-tuning.md b/docs/en/guides/hyperparameter-tuning.md
index 4888c340..67763edb 100644
--- a/docs/en/guides/hyperparameter-tuning.md
+++ b/docs/en/guides/hyperparameter-tuning.md
@@ -77,10 +77,10 @@ Here's how to use the `model.tune()` method to utilize the `Tuner` class for hyp
from ultralytics import YOLO
# Initialize the YOLO model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Tune hyperparameters on COCO8 for 30 epochs
- model.tune(data='coco8.yaml', epochs=30, iterations=300, optimizer='AdamW', plots=False, save=False, val=False)
+ model.tune(data="coco8.yaml", epochs=30, iterations=300, optimizer="AdamW", plots=False, save=False, val=False)
```
## Results
diff --git a/docs/en/guides/instance-segmentation-and-tracking.md b/docs/en/guides/instance-segmentation-and-tracking.md
index 558ab57d..90aaf4ba 100644
--- a/docs/en/guides/instance-segmentation-and-tracking.md
+++ b/docs/en/guides/instance-segmentation-and-tracking.md
@@ -48,7 +48,7 @@ There are two types of instance segmentation tracking available in the Ultralyti
cap = cv2.VideoCapture("path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
- out = cv2.VideoWriter('instance-segmentation.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
+ out = cv2.VideoWriter("instance-segmentation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
while True:
ret, im0 = cap.read()
@@ -63,38 +63,35 @@ There are two types of instance segmentation tracking available in the Ultralyti
clss = results[0].boxes.cls.cpu().tolist()
masks = results[0].masks.xy
for mask, cls in zip(masks, clss):
- annotator.seg_bbox(mask=mask,
- mask_color=colors(int(cls), True),
- det_label=names[int(cls)])
+ annotator.seg_bbox(mask=mask, mask_color=colors(int(cls), True), det_label=names[int(cls)])
out.write(im0)
cv2.imshow("instance-segmentation", im0)
- if cv2.waitKey(1) & 0xFF == ord('q'):
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
out.release()
cap.release()
cv2.destroyAllWindows()
-
```
=== "Instance Segmentation with Object Tracking"
```python
+ from collections import defaultdict
+
import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
- from collections import defaultdict
-
track_history = defaultdict(lambda: [])
- model = YOLO("yolov8n-seg.pt") # segmentation model
+ model = YOLO("yolov8n-seg.pt") # segmentation model
cap = cv2.VideoCapture("path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
- out = cv2.VideoWriter('instance-segmentation-object-tracking.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
+ out = cv2.VideoWriter("instance-segmentation-object-tracking.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
while True:
ret, im0 = cap.read()
@@ -111,14 +108,12 @@ There are two types of instance segmentation tracking available in the Ultralyti
track_ids = results[0].boxes.id.int().cpu().tolist()
for mask, track_id in zip(masks, track_ids):
- annotator.seg_bbox(mask=mask,
- mask_color=colors(track_id, True),
- track_label=str(track_id))
+ annotator.seg_bbox(mask=mask, mask_color=colors(track_id, True), track_label=str(track_id))
out.write(im0)
cv2.imshow("instance-segmentation-object-tracking", im0)
- if cv2.waitKey(1) & 0xFF == ord('q'):
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
out.release()
diff --git a/docs/en/guides/isolating-segmentation-objects.md b/docs/en/guides/isolating-segmentation-objects.md
index 3ef965b7..3efa962d 100644
--- a/docs/en/guides/isolating-segmentation-objects.md
+++ b/docs/en/guides/isolating-segmentation-objects.md
@@ -36,7 +36,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt')
+ model = YOLO("yolov8n-seg.pt")
# Run inference
results = model.predict()
@@ -159,7 +159,6 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
# Isolate object with binary mask
isolated = cv2.bitwise_and(mask3ch, img)
-
```
??? question "How does this work?"
@@ -209,7 +208,6 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
```py
# Isolate object with transparent background (when saved as PNG)
isolated = np.dstack([img, b_mask])
-
```
??? question "How does this work?"
@@ -266,7 +264,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
```py
# Save isolated object to file
- _ = cv2.imwrite(f'{img_name}_{label}-{ci}.png', iso_crop)
+ _ = cv2.imwrite(f"{img_name}_{label}-{ci}.png", iso_crop)
```
- In this example, the `img_name` is the base-name of the source image file, `label` is the detected class-name, and `ci` is the index of the object detection (in case of multiple instances with the same class name).
diff --git a/docs/en/guides/kfold-cross-validation.md b/docs/en/guides/kfold-cross-validation.md
index 9eb53a10..a7c864f6 100644
--- a/docs/en/guides/kfold-cross-validation.md
+++ b/docs/en/guides/kfold-cross-validation.md
@@ -62,36 +62,36 @@ Without further ado, let's dive in!
```python
import datetime
import shutil
- from pathlib import Path
from collections import Counter
+ from pathlib import Path
- import yaml
import numpy as np
import pandas as pd
- from ultralytics import YOLO
+ import yaml
from sklearn.model_selection import KFold
+ from ultralytics import YOLO
```
2. Proceed to retrieve all label files for your dataset.
```python
- dataset_path = Path('./Fruit-detection') # replace with 'path/to/dataset' for your custom data
- labels = sorted(dataset_path.rglob("*labels/*.txt")) # all data in 'labels'
+ dataset_path = Path("./Fruit-detection") # replace with 'path/to/dataset' for your custom data
+ labels = sorted(dataset_path.rglob("*labels/*.txt")) # all data in 'labels'
```
3. Now, read the contents of the dataset YAML file and extract the indices of the class labels.
```python
- yaml_file = 'path/to/data.yaml' # your data YAML with data directories and names dictionary
- with open(yaml_file, 'r', encoding="utf8") as y:
- classes = yaml.safe_load(y)['names']
+ yaml_file = "path/to/data.yaml" # your data YAML with data directories and names dictionary
+ with open(yaml_file, "r", encoding="utf8") as y:
+ classes = yaml.safe_load(y)["names"]
cls_idx = sorted(classes.keys())
```
4. Initialize an empty `pandas` DataFrame.
```python
- indx = [l.stem for l in labels] # uses base filename as ID (no extension)
+ indx = [l.stem for l in labels] # uses base filename as ID (no extension)
labels_df = pd.DataFrame([], columns=cls_idx, index=indx)
```
@@ -101,16 +101,16 @@ Without further ado, let's dive in!
for label in labels:
lbl_counter = Counter()
- with open(label,'r') as lf:
+ with open(label, "r") as lf:
lines = lf.readlines()
for l in lines:
# classes for YOLO label uses integer at first position of each line
- lbl_counter[int(l.split(' ')[0])] += 1
+ lbl_counter[int(l.split(" ")[0])] += 1
labels_df.loc[label.stem] = lbl_counter
- labels_df = labels_df.fillna(0.0) # replace `nan` values with `0.0`
+ labels_df = labels_df.fillna(0.0) # replace `nan` values with `0.0`
```
6. The following is a sample view of the populated DataFrame:
@@ -142,7 +142,7 @@ The rows index the label files, each corresponding to an image in your dataset,
```python
ksplit = 5
- kf = KFold(n_splits=ksplit, shuffle=True, random_state=20) # setting random_state for repeatable results
+ kf = KFold(n_splits=ksplit, shuffle=True, random_state=20) # setting random_state for repeatable results
kfolds = list(kf.split(labels_df))
```
@@ -150,12 +150,12 @@ The rows index the label files, each corresponding to an image in your dataset,
2. The dataset has now been split into `k` folds, each having a list of `train` and `val` indices. We will construct a DataFrame to display these results more clearly.
```python
- folds = [f'split_{n}' for n in range(1, ksplit + 1)]
+ folds = [f"split_{n}" for n in range(1, ksplit + 1)]
folds_df = pd.DataFrame(index=indx, columns=folds)
for idx, (train, val) in enumerate(kfolds, start=1):
- folds_df[f'split_{idx}'].loc[labels_df.iloc[train].index] = 'train'
- folds_df[f'split_{idx}'].loc[labels_df.iloc[val].index] = 'val'
+ folds_df[f"split_{idx}"].loc[labels_df.iloc[train].index] = "train"
+ folds_df[f"split_{idx}"].loc[labels_df.iloc[val].index] = "val"
```
3. Now we will calculate the distribution of class labels for each fold as a ratio of the classes present in `val` to those present in `train`.
@@ -168,8 +168,8 @@ The rows index the label files, each corresponding to an image in your dataset,
val_totals = labels_df.iloc[val_indices].sum()
# To avoid division by zero, we add a small value (1E-7) to the denominator
- ratio = val_totals / (train_totals + 1E-7)
- fold_lbl_distrb.loc[f'split_{n}'] = ratio
+ ratio = val_totals / (train_totals + 1e-7)
+ fold_lbl_distrb.loc[f"split_{n}"] = ratio
```
The ideal scenario is for all class ratios to be reasonably similar for each split and across classes. This, however, will be subject to the specifics of your dataset.
@@ -177,17 +177,17 @@ The rows index the label files, each corresponding to an image in your dataset,
4. Next, we create the directories and dataset YAML files for each split.
```python
- supported_extensions = ['.jpg', '.jpeg', '.png']
+ supported_extensions = [".jpg", ".jpeg", ".png"]
# Initialize an empty list to store image file paths
images = []
# Loop through supported extensions and gather image files
for ext in supported_extensions:
- images.extend(sorted((dataset_path / 'images').rglob(f"*{ext}")))
+ images.extend(sorted((dataset_path / "images").rglob(f"*{ext}")))
# Create the necessary directories and dataset YAML files (unchanged)
- save_path = Path(dataset_path / f'{datetime.date.today().isoformat()}_{ksplit}-Fold_Cross-val')
+ save_path = Path(dataset_path / f"{datetime.date.today().isoformat()}_{ksplit}-Fold_Cross-val")
save_path.mkdir(parents=True, exist_ok=True)
ds_yamls = []
@@ -195,22 +195,25 @@ The rows index the label files, each corresponding to an image in your dataset,
# Create directories
split_dir = save_path / split
split_dir.mkdir(parents=True, exist_ok=True)
- (split_dir / 'train' / 'images').mkdir(parents=True, exist_ok=True)
- (split_dir / 'train' / 'labels').mkdir(parents=True, exist_ok=True)
- (split_dir / 'val' / 'images').mkdir(parents=True, exist_ok=True)
- (split_dir / 'val' / 'labels').mkdir(parents=True, exist_ok=True)
+ (split_dir / "train" / "images").mkdir(parents=True, exist_ok=True)
+ (split_dir / "train" / "labels").mkdir(parents=True, exist_ok=True)
+ (split_dir / "val" / "images").mkdir(parents=True, exist_ok=True)
+ (split_dir / "val" / "labels").mkdir(parents=True, exist_ok=True)
# Create dataset YAML files
- dataset_yaml = split_dir / f'{split}_dataset.yaml'
+ dataset_yaml = split_dir / f"{split}_dataset.yaml"
ds_yamls.append(dataset_yaml)
- with open(dataset_yaml, 'w') as ds_y:
- yaml.safe_dump({
- 'path': split_dir.as_posix(),
- 'train': 'train',
- 'val': 'val',
- 'names': classes
- }, ds_y)
+ with open(dataset_yaml, "w") as ds_y:
+ yaml.safe_dump(
+ {
+ "path": split_dir.as_posix(),
+ "train": "train",
+ "val": "val",
+ "names": classes,
+ },
+ ds_y,
+ )
```
5. Lastly, copy images and labels into the respective directory ('train' or 'val') for each split.
@@ -221,8 +224,8 @@ The rows index the label files, each corresponding to an image in your dataset,
for image, label in zip(images, labels):
for split, k_split in folds_df.loc[image.stem].items():
# Destination directory
- img_to_path = save_path / split / k_split / 'images'
- lbl_to_path = save_path / split / k_split / 'labels'
+ img_to_path = save_path / split / k_split / "images"
+ lbl_to_path = save_path / split / k_split / "labels"
# Copy image and label files to new directory (SamefileError if file already exists)
shutil.copy(image, img_to_path / image.name)
@@ -243,8 +246,8 @@ fold_lbl_distrb.to_csv(save_path / "kfold_label_distribution.csv")
1. First, load the YOLO model.
```python
- weights_path = 'path/to/weights.pt'
- model = YOLO(weights_path, task='detect')
+ weights_path = "path/to/weights.pt"
+ model = YOLO(weights_path, task="detect")
```
2. Next, iterate over the dataset YAML files to run training. The results will be saved to a directory specified by the `project` and `name` arguments. By default, this directory is 'exp/runs#' where # is an integer index.
@@ -254,12 +257,12 @@ fold_lbl_distrb.to_csv(save_path / "kfold_label_distribution.csv")
# Define your additional arguments here
batch = 16
- project = 'kfold_demo'
+ project = "kfold_demo"
epochs = 100
for k in range(ksplit):
dataset_yaml = ds_yamls[k]
- model.train(data=dataset_yaml,epochs=epochs, batch=batch, project=project) # include any train arguments
+ model.train(data=dataset_yaml, epochs=epochs, batch=batch, project=project) # include any train arguments
results[k] = model.metrics # save output metrics for further analysis
```
diff --git a/docs/en/guides/nvidia-jetson.md b/docs/en/guides/nvidia-jetson.md
index bfc0ce8e..7803fae6 100644
--- a/docs/en/guides/nvidia-jetson.md
+++ b/docs/en/guides/nvidia-jetson.md
@@ -158,16 +158,16 @@ The YOLOv8n model in PyTorch format is converted to TensorRT to run inference wi
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model
- model.export(format='engine') # creates 'yolov8n.engine'
+ model.export(format="engine") # creates 'yolov8n.engine'
# Load the exported TensorRT model
- trt_model = YOLO('yolov8n.engine')
+ trt_model = YOLO("yolov8n.engine")
# Run inference
- results = trt_model('https://ultralytics.com/images/bus.jpg')
+ results = trt_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
@@ -290,10 +290,10 @@ To reproduce the above Ultralytics benchmarks on all export [formats](../modes/e
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
- results = model.benchmarks(data='coco8.yaml', imgsz=640)
+ results = model.benchmarks(data="coco8.yaml", imgsz=640)
```
=== "CLI"
diff --git a/docs/en/guides/object-blurring.md b/docs/en/guides/object-blurring.md
index 0b6faa3e..2b3d5be5 100644
--- a/docs/en/guides/object-blurring.md
+++ b/docs/en/guides/object-blurring.md
@@ -21,9 +21,9 @@ Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
=== "Object Blurring"
```python
+ import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
- import cv2
model = YOLO("yolov8n.pt")
names = model.names
@@ -36,9 +36,7 @@ Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
blur_ratio = 50
# Video writer
- video_writer = cv2.VideoWriter("object_blurring_output.avi",
- cv2.VideoWriter_fourcc(*'mp4v'),
- fps, (w, h))
+ video_writer = cv2.VideoWriter("object_blurring_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
while cap.isOpened():
success, im0 = cap.read()
@@ -55,14 +53,14 @@ Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
for box, cls in zip(boxes, clss):
annotator.box_label(box, color=colors(int(cls), True), label=names[int(cls)])
- obj = im0[int(box[1]):int(box[3]), int(box[0]):int(box[2])]
+ obj = im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])]
blur_obj = cv2.blur(obj, (blur_ratio, blur_ratio))
- im0[int(box[1]):int(box[3]), int(box[0]):int(box[2])] = blur_obj
+ im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])] = blur_obj
cv2.imshow("ultralytics", im0)
video_writer.write(im0)
- if cv2.waitKey(1) & 0xFF == ord('q'):
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
diff --git a/docs/en/guides/object-counting.md b/docs/en/guides/object-counting.md
index a52a0358..e625544b 100644
--- a/docs/en/guides/object-counting.md
+++ b/docs/en/guides/object-counting.md
@@ -53,18 +53,18 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
```python
import cv2
from ultralytics import YOLO, solutions
-
+
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
-
+
# Define region points
region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
-
+
# Video writer
video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
-
+
# Init Object Counter
counter = solutions.ObjectCounter(
view_img=True,
@@ -73,17 +73,17 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
draw_tracks=True,
line_thickness=2,
)
-
+
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
tracks = model.track(im0, persist=True, show=False)
-
+
im0 = counter.start_counting(im0, tracks)
video_writer.write(im0)
-
+
cap.release()
video_writer.release()
cv2.destroyAllWindows()
@@ -94,18 +94,18 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
```python
import cv2
from ultralytics import YOLO, solutions
-
+
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
-
+
# Define region points as a polygon with 5 points
region_points = [(20, 400), (1080, 404), (1080, 360), (20, 360), (20, 400)]
-
+
# Video writer
video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
-
+
# Init Object Counter
counter = solutions.ObjectCounter(
view_img=True,
@@ -114,17 +114,17 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
draw_tracks=True,
line_thickness=2,
)
-
+
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
tracks = model.track(im0, persist=True, show=False)
-
+
im0 = counter.start_counting(im0, tracks)
video_writer.write(im0)
-
+
cap.release()
video_writer.release()
cv2.destroyAllWindows()
@@ -135,18 +135,18 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
```python
import cv2
from ultralytics import YOLO, solutions
-
+
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
-
+
# Define line points
line_points = [(20, 400), (1080, 400)]
-
+
# Video writer
video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
-
+
# Init Object Counter
counter = solutions.ObjectCounter(
view_img=True,
@@ -155,17 +155,17 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
draw_tracks=True,
line_thickness=2,
)
-
+
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
tracks = model.track(im0, persist=True, show=False)
-
+
im0 = counter.start_counting(im0, tracks)
video_writer.write(im0)
-
+
cap.release()
video_writer.release()
cv2.destroyAllWindows()
@@ -176,18 +176,18 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
```python
import cv2
from ultralytics import YOLO, solutions
-
+
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
-
+
line_points = [(20, 400), (1080, 400)] # line or region points
classes_to_count = [0, 2] # person and car classes for count
-
+
# Video writer
video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
-
+
# Init Object Counter
counter = solutions.ObjectCounter(
view_img=True,
@@ -196,17 +196,17 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
draw_tracks=True,
line_thickness=2,
)
-
+
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
tracks = model.track(im0, persist=True, show=False, classes=classes_to_count)
-
+
im0 = counter.start_counting(im0, tracks)
video_writer.write(im0)
-
+
cap.release()
video_writer.release()
cv2.destroyAllWindows()
diff --git a/docs/en/guides/object-cropping.md b/docs/en/guides/object-cropping.md
index e08ddda2..3f2823b7 100644
--- a/docs/en/guides/object-cropping.md
+++ b/docs/en/guides/object-cropping.md
@@ -28,10 +28,11 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
=== "Object Cropping"
```python
+ import os
+
+ import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
- import cv2
- import os
model = YOLO("yolov8n.pt")
names = model.names
@@ -45,9 +46,7 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
os.mkdir(crop_dir_name)
# Video writer
- video_writer = cv2.VideoWriter("object_cropping_output.avi",
- cv2.VideoWriter_fourcc(*'mp4v'),
- fps, (w, h))
+ video_writer = cv2.VideoWriter("object_cropping_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
idx = 0
while cap.isOpened():
@@ -66,14 +65,14 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
idx += 1
annotator.box_label(box, color=colors(int(cls), True), label=names[int(cls)])
- crop_obj = im0[int(box[1]):int(box[3]), int(box[0]):int(box[2])]
+ crop_obj = im0[int(box[1]) : int(box[3]), int(box[0]) : int(box[2])]
- cv2.imwrite(os.path.join(crop_dir_name, str(idx)+".png"), crop_obj)
+ cv2.imwrite(os.path.join(crop_dir_name, str(idx) + ".png"), crop_obj)
cv2.imshow("ultralytics", im0)
video_writer.write(im0)
- if cv2.waitKey(1) & 0xFF == ord('q'):
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
diff --git a/docs/en/guides/parking-management.md b/docs/en/guides/parking-management.md
index 421398cc..c661c2b9 100644
--- a/docs/en/guides/parking-management.md
+++ b/docs/en/guides/parking-management.md
@@ -62,36 +62,34 @@ root.mainloop()
# Path to json file, that created with above point selection app
polygon_json_path = "bounding_boxes.json"
-
+
# Video capture
cap = cv2.VideoCapture("Path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
- w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH,
- cv2.CAP_PROP_FRAME_HEIGHT,
- cv2.CAP_PROP_FPS))
-
+ w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
+
# Video writer
- video_writer = cv2.VideoWriter("parking management.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
-
+ video_writer = cv2.VideoWriter("parking management.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
# Initialize parking management object
management = solutions.ParkingManagement(model_path="yolov8n.pt")
-
+
while cap.isOpened():
ret, im0 = cap.read()
if not ret:
break
-
+
json_data = management.parking_regions_extraction(polygon_json_path)
results = management.model.track(im0, persist=True, show=False)
-
+
if results[0].boxes.id is not None:
boxes = results[0].boxes.xyxy.cpu().tolist()
clss = results[0].boxes.cls.cpu().tolist()
management.process_data(json_data, im0, boxes, clss)
-
+
management.display_frames(im0)
video_writer.write(im0)
-
+
cap.release()
video_writer.release()
cv2.destroyAllWindows()
diff --git a/docs/en/guides/queue-management.md b/docs/en/guides/queue-management.md
index b4b450e2..fcff5b26 100644
--- a/docs/en/guides/queue-management.md
+++ b/docs/en/guides/queue-management.md
@@ -29,39 +29,40 @@ Queue management using [Ultralytics YOLOv8](https://github.com/ultralytics/ultra
```python
import cv2
from ultralytics import YOLO, solutions
-
+
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
-
+
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
-
- video_writer = cv2.VideoWriter("queue_management.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
-
+
+ video_writer = cv2.VideoWriter("queue_management.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
queue_region = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
-
- queue = solutions.QueueManager(classes_names=model.names,
- reg_pts=queue_region,
- line_thickness=3,
- fontsize=1.0,
- region_color=(255, 144, 31))
-
+
+ queue = solutions.QueueManager(
+ classes_names=model.names,
+ reg_pts=queue_region,
+ line_thickness=3,
+ fontsize=1.0,
+ region_color=(255, 144, 31),
+ )
+
while cap.isOpened():
success, im0 = cap.read()
-
+
if success:
- tracks = model.track(im0, show=False, persist=True,
- verbose=False)
+ tracks = model.track(im0, show=False, persist=True, verbose=False)
out = queue.process_queue(im0, tracks)
-
+
video_writer.write(im0)
- if cv2.waitKey(1) & 0xFF == ord('q'):
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
continue
-
+
print("Video frame is empty or video processing has been successfully completed.")
break
-
+
cap.release()
cv2.destroyAllWindows()
```
@@ -71,39 +72,40 @@ Queue management using [Ultralytics YOLOv8](https://github.com/ultralytics/ultra
```python
import cv2
from ultralytics import YOLO, solutions
-
+
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
-
+
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
-
- video_writer = cv2.VideoWriter("queue_management.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
-
+
+ video_writer = cv2.VideoWriter("queue_management.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
+
queue_region = [(20, 400), (1080, 404), (1080, 360), (20, 360)]
-
- queue = solutions.QueueManager(classes_names=model.names,
- reg_pts=queue_region,
- line_thickness=3,
- fontsize=1.0,
- region_color=(255, 144, 31))
-
+
+ queue = solutions.QueueManager(
+ classes_names=model.names,
+ reg_pts=queue_region,
+ line_thickness=3,
+ fontsize=1.0,
+ region_color=(255, 144, 31),
+ )
+
while cap.isOpened():
success, im0 = cap.read()
-
+
if success:
- tracks = model.track(im0, show=False, persist=True,
- verbose=False, classes=0) # Only person class
+ tracks = model.track(im0, show=False, persist=True, verbose=False, classes=0) # Only person class
out = queue.process_queue(im0, tracks)
-
+
video_writer.write(im0)
- if cv2.waitKey(1) & 0xFF == ord('q'):
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
continue
-
+
print("Video frame is empty or video processing has been successfully completed.")
break
-
+
cap.release()
cv2.destroyAllWindows()
```
diff --git a/docs/en/guides/raspberry-pi.md b/docs/en/guides/raspberry-pi.md
index f06666b2..97cfe51d 100644
--- a/docs/en/guides/raspberry-pi.md
+++ b/docs/en/guides/raspberry-pi.md
@@ -108,16 +108,16 @@ The YOLOv8n model in PyTorch format is converted to NCNN to run inference with t
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to NCNN format
- model.export(format='ncnn') # creates 'yolov8n_ncnn_model'
+ model.export(format="ncnn") # creates 'yolov8n_ncnn_model'
# Load the exported NCNN model
- ncnn_model = YOLO('yolov8n_ncnn_model')
+ ncnn_model = YOLO("yolov8n_ncnn_model")
# Run inference
- results = ncnn_model('https://ultralytics.com/images/bus.jpg')
+ results = ncnn_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
@@ -231,10 +231,10 @@ To reproduce the above Ultralytics benchmarks on all [export formats](../modes/e
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
- results = model.benchmarks(data='coco8.yaml', imgsz=640)
+ results = model.benchmarks(data="coco8.yaml", imgsz=640)
```
=== "CLI"
@@ -293,10 +293,10 @@ With the TCP stream initiated, you can perform YOLOv8 inference.
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Run inference
- results = model('tcp://127.0.0.1:8888')
+ results = model("tcp://127.0.0.1:8888")
```
=== "CLI"
diff --git a/docs/en/guides/sahi-tiled-inference.md b/docs/en/guides/sahi-tiled-inference.md
index 97287030..23008c3e 100644
--- a/docs/en/guides/sahi-tiled-inference.md
+++ b/docs/en/guides/sahi-tiled-inference.md
@@ -60,21 +60,28 @@ pip install -U ultralytics sahi
Here's how to import the necessary modules and download a YOLOv8 model and some test images:
```python
-from sahi.utils.yolov8 import download_yolov8s_model
+from pathlib import Path
+
+from IPython.display import Image
from sahi import AutoDetectionModel
+from sahi.predict import get_prediction, get_sliced_prediction, predict
from sahi.utils.cv import read_image
from sahi.utils.file import download_from_url
-from sahi.predict import get_prediction, get_sliced_prediction, predict
-from pathlib import Path
-from IPython.display import Image
+from sahi.utils.yolov8 import download_yolov8s_model
# Download YOLOv8 model
yolov8_model_path = "models/yolov8s.pt"
download_yolov8s_model(yolov8_model_path)
# Download test images
-download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg', 'demo_data/small-vehicles1.jpeg')
-download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/terrain2.png', 'demo_data/terrain2.png')
+download_from_url(
+ "https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg",
+ "demo_data/small-vehicles1.jpeg",
+)
+download_from_url(
+ "https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/terrain2.png",
+ "demo_data/terrain2.png",
+)
```
## Standard Inference with YOLOv8
@@ -85,7 +92,7 @@ You can instantiate a YOLOv8 model for object detection like this:
```python
detection_model = AutoDetectionModel.from_pretrained(
- model_type='yolov8',
+ model_type="yolov8",
model_path=yolov8_model_path,
confidence_threshold=0.3,
device="cpu", # or 'cuda:0'
@@ -124,7 +131,7 @@ result = get_sliced_prediction(
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
- overlap_width_ratio=0.2
+ overlap_width_ratio=0.2,
)
```
diff --git a/docs/en/guides/security-alarm-system.md b/docs/en/guides/security-alarm-system.md
index 4f0a0382..9f6332de 100644
--- a/docs/en/guides/security-alarm-system.md
+++ b/docs/en/guides/security-alarm-system.md
@@ -30,15 +30,16 @@ The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanc
#### Import Libraries
```python
-import torch
-import numpy as np
-import cv2
-from time import time
-from ultralytics import YOLO
-from ultralytics.utils.plotting import Annotator, colors
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
+from time import time
+
+import cv2
+import numpy as np
+import torch
+from ultralytics import YOLO
+from ultralytics.utils.plotting import Annotator, colors
```
#### Set up the parameters of the message
@@ -58,7 +59,7 @@ to_email = "" # receiver email
#### Server creation and authentication
```python
-server = smtplib.SMTP('smtp.gmail.com: 587')
+server = smtplib.SMTP("smtp.gmail.com: 587")
server.starttls()
server.login(from_email, password)
```
@@ -69,13 +70,13 @@ server.login(from_email, password)
def send_email(to_email, from_email, object_detected=1):
"""Sends an email notification indicating the number of objects detected; defaults to 1 object."""
message = MIMEMultipart()
- message['From'] = from_email
- message['To'] = to_email
- message['Subject'] = "Security Alert"
+ message["From"] = from_email
+ message["To"] = to_email
+ message["Subject"] = "Security Alert"
# Add in the message body
- message_body = f'ALERT - {object_detected} objects has been detected!!'
+ message_body = f"ALERT - {object_detected} objects has been detected!!"
- message.attach(MIMEText(message_body, 'plain'))
+ message.attach(MIMEText(message_body, "plain"))
server.sendmail(from_email, to_email, message.as_string())
```
@@ -97,7 +98,7 @@ class ObjectDetection:
self.end_time = 0
# device information
- self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
def predict(self, im0):
"""Run prediction using a YOLO model for the input image `im0`."""
@@ -108,10 +109,16 @@ class ObjectDetection:
"""Displays the FPS on an image `im0` by calculating and overlaying as white text on a black rectangle."""
self.end_time = time()
fps = 1 / np.round(self.end_time - self.start_time, 2)
- text = f'FPS: {int(fps)}'
+ text = f"FPS: {int(fps)}"
text_size = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 1.0, 2)[0]
gap = 10
- cv2.rectangle(im0, (20 - gap, 70 - text_size[1] - gap), (20 + text_size[0] + gap, 70 + gap), (255, 255, 255), -1)
+ cv2.rectangle(
+ im0,
+ (20 - gap, 70 - text_size[1] - gap),
+ (20 + text_size[0] + gap, 70 + gap),
+ (255, 255, 255),
+ -1,
+ )
cv2.putText(im0, text, (20, 70), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 0), 2)
def plot_bboxes(self, results, im0):
@@ -148,7 +155,7 @@ class ObjectDetection:
self.email_sent = False
self.display_fps(im0)
- cv2.imshow('YOLOv8 Detection', im0)
+ cv2.imshow("YOLOv8 Detection", im0)
frame_count += 1
if cv2.waitKey(5) & 0xFF == 27:
break
diff --git a/docs/en/guides/speed-estimation.md b/docs/en/guides/speed-estimation.md
index 95142c72..e846cdac 100644
--- a/docs/en/guides/speed-estimation.md
+++ b/docs/en/guides/speed-estimation.md
@@ -39,8 +39,8 @@ Speed estimation is the process of calculating the rate of movement of an object
=== "Speed Estimation"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
model = YOLO("yolov8n.pt")
names = model.model.names
@@ -50,17 +50,18 @@ Speed estimation is the process of calculating the rate of movement of an object
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Video writer
- video_writer = cv2.VideoWriter("speed_estimation.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ video_writer = cv2.VideoWriter("speed_estimation.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
line_pts = [(0, 360), (1280, 360)]
# Init speed-estimation obj
- speed_obj = solutions.SpeedEstimator(reg_pts=line_pts,
- names=names,
- view_img=True)
+ speed_obj = solutions.SpeedEstimator(
+ reg_pts=line_pts,
+ names=names,
+ view_img=True,
+ )
while cap.isOpened():
-
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
@@ -74,7 +75,6 @@ Speed estimation is the process of calculating the rate of movement of an object
cap.release()
video_writer.release()
cv2.destroyAllWindows()
-
```
???+ warning "Speed is Estimate"
diff --git a/docs/en/guides/triton-inference-server.md b/docs/en/guides/triton-inference-server.md
index 6f3b1d24..f7d1a9b8 100644
--- a/docs/en/guides/triton-inference-server.md
+++ b/docs/en/guides/triton-inference-server.md
@@ -46,10 +46,10 @@ Before deploying the model on Triton, it must be exported to the ONNX format. ON
from ultralytics import YOLO
# Load a model
-model = YOLO('yolov8n.pt') # load an official model
+model = YOLO("yolov8n.pt") # load an official model
# Export the model
-onnx_file = model.export(format='onnx', dynamic=True)
+onnx_file = model.export(format="onnx", dynamic=True)
```
## Setting Up Triton Model Repository
@@ -62,11 +62,11 @@ The Triton Model Repository is a storage location where Triton can access and lo
from pathlib import Path
# Define paths
- triton_repo_path = Path('tmp') / 'triton_repo'
- triton_model_path = triton_repo_path / 'yolo'
+ triton_repo_path = Path("tmp") / "triton_repo"
+ triton_model_path = triton_repo_path / "yolo"
# Create directories
- (triton_model_path / '1').mkdir(parents=True, exist_ok=True)
+ (triton_model_path / "1").mkdir(parents=True, exist_ok=True)
```
2. Move the exported ONNX model to the Triton repository:
@@ -75,10 +75,10 @@ The Triton Model Repository is a storage location where Triton can access and lo
from pathlib import Path
# Move ONNX model to Triton Model path
- Path(onnx_file).rename(triton_model_path / '1' / 'model.onnx')
+ Path(onnx_file).rename(triton_model_path / "1" / "model.onnx")
# Create config file
- (triton_model_path / 'config.pbtxt').touch()
+ (triton_model_path / "config.pbtxt").touch()
```
## Running Triton Inference Server
@@ -92,18 +92,23 @@ import time
from tritonclient.http import InferenceServerClient
# Define image https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver
-tag = 'nvcr.io/nvidia/tritonserver:23.09-py3' # 6.4 GB
+tag = "nvcr.io/nvidia/tritonserver:23.09-py3" # 6.4 GB
# Pull the image
-subprocess.call(f'docker pull {tag}', shell=True)
+subprocess.call(f"docker pull {tag}", shell=True)
# Run the Triton server and capture the container ID
-container_id = subprocess.check_output(
- f'docker run -d --rm -v {triton_repo_path}:/models -p 8000:8000 {tag} tritonserver --model-repository=/models',
- shell=True).decode('utf-8').strip()
+container_id = (
+ subprocess.check_output(
+ f"docker run -d --rm -v {triton_repo_path}:/models -p 8000:8000 {tag} tritonserver --model-repository=/models",
+ shell=True,
+ )
+ .decode("utf-8")
+ .strip()
+)
# Wait for the Triton server to start
-triton_client = InferenceServerClient(url='localhost:8000', verbose=False, ssl=False)
+triton_client = InferenceServerClient(url="localhost:8000", verbose=False, ssl=False)
# Wait until model is ready
for _ in range(10):
@@ -119,17 +124,17 @@ Then run inference using the Triton Server model:
from ultralytics import YOLO
# Load the Triton Server model
-model = YOLO(f'http://localhost:8000/yolo', task='detect')
+model = YOLO(f"http://localhost:8000/yolo", task="detect")
# Run inference on the server
-results = model('path/to/image.jpg')
+results = model("path/to/image.jpg")
```
Cleanup the container:
```python
# Kill and remove the container at the end of the test
-subprocess.call(f'docker kill {container_id}', shell=True)
+subprocess.call(f"docker kill {container_id}", shell=True)
```
---
diff --git a/docs/en/guides/view-results-in-terminal.md b/docs/en/guides/view-results-in-terminal.md
index 24f382cf..b60a5f78 100644
--- a/docs/en/guides/view-results-in-terminal.md
+++ b/docs/en/guides/view-results-in-terminal.md
@@ -47,9 +47,8 @@ The VSCode compatible protocols for viewing images using the integrated terminal
import io
import cv2 as cv
-
- from ultralytics import YOLO
from sixel import SixelWriter
+ from ultralytics import YOLO
```
1. Load a model and execute inference, then plot the results and store in a variable. See more about inference arguments and working with results on the [predict mode](../modes/predict.md) page.
diff --git a/docs/en/guides/vision-eye.md b/docs/en/guides/vision-eye.md
index c51cf2d7..eba2a6d1 100644
--- a/docs/en/guides/vision-eye.md
+++ b/docs/en/guides/vision-eye.md
@@ -24,14 +24,14 @@ keywords: Ultralytics, YOLOv8, Object Detection, Object Tracking, IDetection, Vi
```python
import cv2
from ultralytics import YOLO
- from ultralytics.utils.plotting import colors, Annotator
+ from ultralytics.utils.plotting import Annotator, colors
model = YOLO("yolov8n.pt")
names = model.model.names
cap = cv2.VideoCapture("path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
- out = cv2.VideoWriter('visioneye-pinpoint.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
+ out = cv2.VideoWriter("visioneye-pinpoint.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
center_point = (-10, h)
@@ -54,7 +54,7 @@ keywords: Ultralytics, YOLOv8, Object Detection, Object Tracking, IDetection, Vi
out.write(im0)
cv2.imshow("visioneye-pinpoint", im0)
- if cv2.waitKey(1) & 0xFF == ord('q'):
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
out.release()
@@ -67,13 +67,13 @@ keywords: Ultralytics, YOLOv8, Object Detection, Object Tracking, IDetection, Vi
```python
import cv2
from ultralytics import YOLO
- from ultralytics.utils.plotting import colors, Annotator
+ from ultralytics.utils.plotting import Annotator, colors
model = YOLO("yolov8n.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
- out = cv2.VideoWriter('visioneye-pinpoint.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
+ out = cv2.VideoWriter("visioneye-pinpoint.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
center_point = (-10, h)
@@ -98,7 +98,7 @@ keywords: Ultralytics, YOLOv8, Object Detection, Object Tracking, IDetection, Vi
out.write(im0)
cv2.imshow("visioneye-pinpoint", im0)
- if cv2.waitKey(1) & 0xFF == ord('q'):
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
out.release()
@@ -109,55 +109,56 @@ keywords: Ultralytics, YOLOv8, Object Detection, Object Tracking, IDetection, Vi
=== "VisionEye with Distance Calculation"
```python
- import cv2
import math
+
+ import cv2
from ultralytics import YOLO
from ultralytics.utils.plotting import Annotator, colors
-
+
model = YOLO("yolov8s.pt")
cap = cv2.VideoCapture("Path/to/video/file.mp4")
-
+
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
-
- out = cv2.VideoWriter('visioneye-distance-calculation.avi', cv2.VideoWriter_fourcc(*'MJPG'), fps, (w, h))
-
+
+ out = cv2.VideoWriter("visioneye-distance-calculation.avi", cv2.VideoWriter_fourcc(*"MJPG"), fps, (w, h))
+
center_point = (0, h)
pixel_per_meter = 10
-
+
txt_color, txt_background, bbox_clr = ((0, 0, 0), (255, 255, 255), (255, 0, 255))
-
+
while True:
ret, im0 = cap.read()
if not ret:
print("Video frame is empty or video processing has been successfully completed.")
break
-
+
annotator = Annotator(im0, line_width=2)
-
+
results = model.track(im0, persist=True)
boxes = results[0].boxes.xyxy.cpu()
-
+
if results[0].boxes.id is not None:
track_ids = results[0].boxes.id.int().cpu().tolist()
-
+
for box, track_id in zip(boxes, track_ids):
annotator.box_label(box, label=str(track_id), color=bbox_clr)
annotator.visioneye(box, center_point)
-
- x1, y1 = int((box[0] + box[2]) // 2), int((box[1] + box[3]) // 2) # Bounding box centroid
-
- distance = (math.sqrt((x1 - center_point[0]) ** 2 + (y1 - center_point[1]) ** 2))/pixel_per_meter
-
- text_size, _ = cv2.getTextSize(f"Distance: {distance:.2f} m", cv2.FONT_HERSHEY_SIMPLEX,1.2, 3)
- cv2.rectangle(im0, (x1, y1 - text_size[1] - 10),(x1 + text_size[0] + 10, y1), txt_background, -1)
- cv2.putText(im0, f"Distance: {distance:.2f} m",(x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 1.2,txt_color, 3)
-
+
+ x1, y1 = int((box[0] + box[2]) // 2), int((box[1] + box[3]) // 2) # Bounding box centroid
+
+ distance = (math.sqrt((x1 - center_point[0]) ** 2 + (y1 - center_point[1]) ** 2)) / pixel_per_meter
+
+ text_size, _ = cv2.getTextSize(f"Distance: {distance:.2f} m", cv2.FONT_HERSHEY_SIMPLEX, 1.2, 3)
+ cv2.rectangle(im0, (x1, y1 - text_size[1] - 10), (x1 + text_size[0] + 10, y1), txt_background, -1)
+ cv2.putText(im0, f"Distance: {distance:.2f} m", (x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 1.2, txt_color, 3)
+
out.write(im0)
cv2.imshow("visioneye-distance-calculation", im0)
-
- if cv2.waitKey(1) & 0xFF == ord('q'):
+
+ if cv2.waitKey(1) & 0xFF == ord("q"):
break
-
+
out.release()
cap.release()
cv2.destroyAllWindows()
diff --git a/docs/en/guides/workouts-monitoring.md b/docs/en/guides/workouts-monitoring.md
index 370aaf20..d0d04803 100644
--- a/docs/en/guides/workouts-monitoring.md
+++ b/docs/en/guides/workouts-monitoring.md
@@ -39,28 +39,30 @@ Monitoring workouts through pose estimation with [Ultralytics YOLOv8](https://gi
=== "Workouts Monitoring"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
model = YOLO("yolov8n-pose.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
- gym_object = solutions.AIGym(line_thickness=2,
- view_img=True,
- pose_type="pushup",
- kpts_to_check=[6, 8, 10])
+ gym_object = solutions.AIGym(
+ line_thickness=2,
+ view_img=True,
+ pose_type="pushup",
+ kpts_to_check=[6, 8, 10],
+ )
frame_count = 0
while cap.isOpened():
success, im0 = cap.read()
if not success:
- print("Video frame is empty or video processing has been successfully completed.")
- break
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
frame_count += 1
results = model.track(im0, verbose=False) # Tracking recommended
- #results = model.predict(im0) # Prediction also supported
+ # results = model.predict(im0) # Prediction also supported
im0 = gym_object.start_counting(im0, results, frame_count)
cv2.destroyAllWindows()
@@ -69,30 +71,32 @@ Monitoring workouts through pose estimation with [Ultralytics YOLOv8](https://gi
=== "Workouts Monitoring with Save Output"
```python
- from ultralytics import YOLO, solutions
import cv2
+ from ultralytics import YOLO, solutions
model = YOLO("yolov8n-pose.pt")
cap = cv2.VideoCapture("path/to/video/file.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
- video_writer = cv2.VideoWriter("workouts.avi", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
+ video_writer = cv2.VideoWriter("workouts.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
- gym_object = solutions.AIGym(line_thickness=2,
- view_img=True,
- pose_type="pushup",
- kpts_to_check=[6, 8, 10])
+ gym_object = solutions.AIGym(
+ line_thickness=2,
+ view_img=True,
+ pose_type="pushup",
+ kpts_to_check=[6, 8, 10],
+ )
frame_count = 0
while cap.isOpened():
success, im0 = cap.read()
if not success:
- print("Video frame is empty or video processing has been successfully completed.")
- break
+ print("Video frame is empty or video processing has been successfully completed.")
+ break
frame_count += 1
results = model.track(im0, verbose=False) # Tracking recommended
- #results = model.predict(im0) # Prediction also supported
+ # results = model.predict(im0) # Prediction also supported
im0 = gym_object.start_counting(im0, results, frame_count)
video_writer.write(im0)
diff --git a/docs/en/guides/yolo-common-issues.md b/docs/en/guides/yolo-common-issues.md
index 09a0daf0..bca0e3cd 100644
--- a/docs/en/guides/yolo-common-issues.md
+++ b/docs/en/guides/yolo-common-issues.md
@@ -79,7 +79,7 @@ This section will address common issues faced while training and their respectiv
- Make sure you pass the path to your `.yaml` file as the `data` argument when calling `model.train()`, as shown below:
```python
-model.train(data='/path/to/your/data.yaml', batch=4)
+model.train(data="/path/to/your/data.yaml", batch=4)
```
#### Accelerating Training with Multiple GPUs
@@ -98,7 +98,7 @@ model.train(data='/path/to/your/data.yaml', batch=4)
```python
# Adjust the batch size and other settings as needed to optimize training speed
-model.train(data='/path/to/your/data.yaml', batch=32, multi_scale=True)
+model.train(data="/path/to/your/data.yaml", batch=32, multi_scale=True)
```
#### Continuous Monitoring Parameters
@@ -221,10 +221,10 @@ yolo task=detect mode=segment model=yolov8n-seg.pt source='path/to/car.mp4' show
from ultralytics import YOLO
# Load a pre-trained YOLOv8 model
-model = YOLO('yolov8n.pt')
+model = YOLO("yolov8n.pt")
# Specify the source image
-source = 'https://ultralytics.com/images/bus.jpg'
+source = "https://ultralytics.com/images/bus.jpg"
# Make predictions
results = model.predict(source, save=True, imgsz=320, conf=0.5)
diff --git a/docs/en/guides/yolo-thread-safe-inference.md b/docs/en/guides/yolo-thread-safe-inference.md
index 901f58d0..ce7fa971 100644
--- a/docs/en/guides/yolo-thread-safe-inference.md
+++ b/docs/en/guides/yolo-thread-safe-inference.md
@@ -28,9 +28,10 @@ When using threads in Python, it's important to recognize patterns that can lead
```python
# Unsafe: Sharing a single model instance across threads
-from ultralytics import YOLO
from threading import Thread
+from ultralytics import YOLO
+
# Instantiate the model outside the thread
shared_model = YOLO("yolov8n.pt")
@@ -54,9 +55,10 @@ Similarly, here is an unsafe pattern with multiple YOLO model instances:
```python
# Unsafe: Sharing multiple model instances across threads can still lead to issues
-from ultralytics import YOLO
from threading import Thread
+from ultralytics import YOLO
+
# Instantiate multiple models outside the thread
shared_model_1 = YOLO("yolov8n_1.pt")
shared_model_2 = YOLO("yolov8n_2.pt")
@@ -85,9 +87,10 @@ Here's how to instantiate a YOLO model inside each thread for safe parallel infe
```python
# Safe: Instantiating a single model inside each thread
-from ultralytics import YOLO
from threading import Thread
+from ultralytics import YOLO
+
def thread_safe_predict(image_path):
"""Predict on an image using a new YOLO model instance in a thread-safe manner; takes image path as input."""
diff --git a/docs/en/help/contributing.md b/docs/en/help/contributing.md
index 7874d48b..4c164c13 100644
--- a/docs/en/help/contributing.md
+++ b/docs/en/help/contributing.md
@@ -57,19 +57,19 @@ When adding new functions or classes, please include a [Google-style docstring](
=== "Google-style"
- This example shows both Google-style docstrings. Note that both input and output `types` must always be enclosed by parentheses, i.e. `(bool)`.
+ This example shows a Google-style docstring. Note that both input and output `types` must always be enclosed by parentheses, i.e. `(bool)`.
```python
def example_function(arg1, arg2=4):
"""
Example function that demonstrates Google-style docstrings.
-
+
Args:
arg1 (int): The first argument.
arg2 (int): The second argument. Default value is 4.
-
+
Returns:
(bool): True if successful, False otherwise.
-
+
Examples:
>>> result = example_function(1, 2) # returns False
"""
@@ -80,19 +80,19 @@ When adding new functions or classes, please include a [Google-style docstring](
=== "Google-style with type hints"
- This example shows both Google-style docstrings and argument and return type hints, though both are not required, one can be used without the other.
+ This example shows both a Google-style docstring and argument and return type hints, though both are not required, one can be used without the other.
```python
def example_function(arg1: int, arg2: int = 4) -> bool:
"""
Example function that demonstrates Google-style docstrings.
-
+
Args:
arg1: The first argument.
arg2: The second argument. Default value is 4.
-
+
Returns:
True if successful, False otherwise.
-
+
Examples:
>>> result = example_function(1, 2) # returns False
"""
diff --git a/docs/en/help/privacy.md b/docs/en/help/privacy.md
index c9bc3a52..731f432f 100644
--- a/docs/en/help/privacy.md
+++ b/docs/en/help/privacy.md
@@ -85,7 +85,7 @@ To gain insight into the current configuration of your settings, you can view th
print(settings)
# Return analytics and crash reporting setting
- value = settings['sync']
+ value = settings["sync"]
```
=== "CLI"
@@ -106,7 +106,7 @@ Ultralytics allows users to easily modify their settings. Changes can be perform
from ultralytics import settings
# Disable analytics and crash reporting
- settings.update({'sync': False})
+ settings.update({"sync": False})
# Reset settings to default values
settings.reset()
diff --git a/docs/en/integrations/amazon-sagemaker.md b/docs/en/integrations/amazon-sagemaker.md
index 3b94726e..25585d4a 100644
--- a/docs/en/integrations/amazon-sagemaker.md
+++ b/docs/en/integrations/amazon-sagemaker.md
@@ -117,21 +117,22 @@ After creating the AWS CloudFormation Stack, the next step is to deploy YOLOv8.
```python
import json
+
def output_fn(prediction_output, content_type):
"""Formats model outputs as JSON string according to content_type, extracting attributes like boxes, masks, keypoints."""
print("Executing output_fn from inference.py ...")
infer = {}
for result in prediction_output:
if result.boxes is not None:
- infer['boxes'] = result.boxes.numpy().data.tolist()
+ infer["boxes"] = result.boxes.numpy().data.tolist()
if result.masks is not None:
- infer['masks'] = result.masks.numpy().data.tolist()
+ infer["masks"] = result.masks.numpy().data.tolist()
if result.keypoints is not None:
- infer['keypoints'] = result.keypoints.numpy().data.tolist()
+ infer["keypoints"] = result.keypoints.numpy().data.tolist()
if result.obb is not None:
- infer['obb'] = result.obb.numpy().data.tolist()
+ infer["obb"] = result.obb.numpy().data.tolist()
if result.probs is not None:
- infer['probs'] = result.probs.numpy().data.tolist()
+ infer["probs"] = result.probs.numpy().data.tolist()
return json.dumps(infer)
```
diff --git a/docs/en/integrations/clearml.md b/docs/en/integrations/clearml.md
index 3af8d707..b59a7828 100644
--- a/docs/en/integrations/clearml.md
+++ b/docs/en/integrations/clearml.md
@@ -67,17 +67,14 @@ Before diving into the usage instructions, be sure to check out the range of [YO
from ultralytics import YOLO
# Step 1: Creating a ClearML Task
- task = Task.init(
- project_name="my_project",
- task_name="my_yolov8_task"
- )
+ task = Task.init(project_name="my_project", task_name="my_yolov8_task")
# Step 2: Selecting the YOLOv8 Model
model_variant = "yolov8n"
task.set_parameter("model_variant", model_variant)
# Step 3: Loading the YOLOv8 Model
- model = YOLO(f'{model_variant}.pt')
+ model = YOLO(f"{model_variant}.pt")
# Step 4: Setting Up Training Arguments
args = dict(data="coco8.yaml", epochs=16)
diff --git a/docs/en/integrations/comet.md b/docs/en/integrations/comet.md
index 99b376de..e395d202 100644
--- a/docs/en/integrations/comet.md
+++ b/docs/en/integrations/comet.md
@@ -74,12 +74,12 @@ Before diving into the usage instructions, be sure to check out the range of [YO
# train the model
results = model.train(
- data="coco8.yaml",
- project="comet-example-yolov8-coco128",
- batch=32,
- save_period=1,
- save_json=True,
- epochs=3
+ data="coco8.yaml",
+ project="comet-example-yolov8-coco128",
+ batch=32,
+ save_period=1,
+ save_json=True,
+ epochs=3,
)
```
@@ -144,7 +144,7 @@ Comet ML allows you to specify how often batches of image predictions are logged
```python
import os
-os.environ['COMET_EVAL_BATCH_LOGGING_INTERVAL'] = "4"
+os.environ["COMET_EVAL_BATCH_LOGGING_INTERVAL"] = "4"
```
### Disabling Confusion Matrix Logging
diff --git a/docs/en/integrations/coreml.md b/docs/en/integrations/coreml.md
index 5533da57..8c76cd61 100644
--- a/docs/en/integrations/coreml.md
+++ b/docs/en/integrations/coreml.md
@@ -83,16 +83,16 @@ Before diving into the usage instructions, be sure to check out the range of [YO
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to CoreML format
- model.export(format='coreml') # creates 'yolov8n.mlpackage'
+ model.export(format="coreml") # creates 'yolov8n.mlpackage'
# Load the exported CoreML model
- coreml_model = YOLO('yolov8n.mlpackage')
+ coreml_model = YOLO("yolov8n.mlpackage")
# Run inference
- results = coreml_model('https://ultralytics.com/images/bus.jpg')
+ results = coreml_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/dvc.md b/docs/en/integrations/dvc.md
index 542a91a6..b723a1a2 100644
--- a/docs/en/integrations/dvc.md
+++ b/docs/en/integrations/dvc.md
@@ -149,7 +149,7 @@ If you are using a Jupyter Notebook and you want to display the generated DVC pl
from IPython.display import HTML
# Display the DVC plots as HTML
-HTML(filename='./dvc_plots/index.html')
+HTML(filename="./dvc_plots/index.html")
```
This code will render the HTML file containing the DVC plots directly in your Jupyter Notebook, providing an easy and convenient way to analyze the visualized experiment data.
diff --git a/docs/en/integrations/edge-tpu.md b/docs/en/integrations/edge-tpu.md
index ec2ec4a8..98a22309 100644
--- a/docs/en/integrations/edge-tpu.md
+++ b/docs/en/integrations/edge-tpu.md
@@ -73,16 +73,16 @@ Before diving into the usage instructions, it's important to note that while all
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to TFLite Edge TPU format
- model.export(format='edgetpu') # creates 'yolov8n_full_integer_quant_edgetpu.tflite’
+ model.export(format="edgetpu") # creates 'yolov8n_full_integer_quant_edgetpu.tflite’
# Load the exported TFLite Edge TPU model
- edgetpu_model = YOLO('yolov8n_full_integer_quant_edgetpu.tflite')
+ edgetpu_model = YOLO("yolov8n_full_integer_quant_edgetpu.tflite")
# Run inference
- results = edgetpu_model('https://ultralytics.com/images/bus.jpg')
+ results = edgetpu_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/gradio.md b/docs/en/integrations/gradio.md
index a1475050..285234f5 100644
--- a/docs/en/integrations/gradio.md
+++ b/docs/en/integrations/gradio.md
@@ -44,9 +44,8 @@ pip install gradio
This section provides the Python code used to create the Gradio interface with the Ultralytics YOLOv8 model. Supports classification tasks, detection tasks, segmentation tasks, and key point tasks.
```python
-import PIL.Image as Image
import gradio as gr
-
+import PIL.Image as Image
from ultralytics import ASSETS, YOLO
model = YOLO("yolov8n.pt")
@@ -75,7 +74,7 @@ iface = gr.Interface(
inputs=[
gr.Image(type="pil", label="Upload Image"),
gr.Slider(minimum=0, maximum=1, value=0.25, label="Confidence threshold"),
- gr.Slider(minimum=0, maximum=1, value=0.45, label="IoU threshold")
+ gr.Slider(minimum=0, maximum=1, value=0.45, label="IoU threshold"),
],
outputs=gr.Image(type="pil", label="Result"),
title="Ultralytics Gradio",
@@ -83,10 +82,10 @@ iface = gr.Interface(
examples=[
[ASSETS / "bus.jpg", 0.25, 0.45],
[ASSETS / "zidane.jpg", 0.25, 0.45],
- ]
+ ],
)
-if __name__ == '__main__':
+if __name__ == "__main__":
iface.launch()
```
diff --git a/docs/en/integrations/mlflow.md b/docs/en/integrations/mlflow.md
index c2fc53e9..cf67d803 100644
--- a/docs/en/integrations/mlflow.md
+++ b/docs/en/integrations/mlflow.md
@@ -42,7 +42,7 @@ Make sure that MLflow logging is enabled in Ultralytics settings. Usually, this
from ultralytics import settings
# Update a setting
- settings.update({'mlflow': True})
+ settings.update({"mlflow": True})
# Reset settings to default values
settings.reset()
diff --git a/docs/en/integrations/ncnn.md b/docs/en/integrations/ncnn.md
index 835f8fcd..a2841bc7 100644
--- a/docs/en/integrations/ncnn.md
+++ b/docs/en/integrations/ncnn.md
@@ -73,18 +73,18 @@ Before diving into the usage instructions, it's important to note that while all
```python
from ultralytics import YOLO
-
+
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
-
+ model = YOLO("yolov8n.pt")
+
# Export the model to NCNN format
- model.export(format='ncnn') # creates '/yolov8n_ncnn_model'
-
+ model.export(format="ncnn") # creates '/yolov8n_ncnn_model'
+
# Load the exported NCNN model
- ncnn_model = YOLO('./yolov8n_ncnn_model')
-
+ ncnn_model = YOLO("./yolov8n_ncnn_model")
+
# Run inference
- results = ncnn_model('https://ultralytics.com/images/bus.jpg')
+ results = ncnn_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/neural-magic.md b/docs/en/integrations/neural-magic.md
index 293c1991..3e9e0e38 100644
--- a/docs/en/integrations/neural-magic.md
+++ b/docs/en/integrations/neural-magic.md
@@ -109,10 +109,7 @@ With your YOLOv8 model in ONNX format, you can deploy and run inferences using D
model_path = "path/to/yolov8n.onnx"
# Set up the DeepSparse Pipeline
- yolo_pipeline = Pipeline.create(
- task="yolov8",
- model_path=model_path
- )
+ yolo_pipeline = Pipeline.create(task="yolov8", model_path=model_path)
# Run the model on your images
images = ["path/to/image.jpg"]
diff --git a/docs/en/integrations/onnx.md b/docs/en/integrations/onnx.md
index b869b044..a050b198 100644
--- a/docs/en/integrations/onnx.md
+++ b/docs/en/integrations/onnx.md
@@ -91,16 +91,16 @@ Before diving into the usage instructions, be sure to check out the range of [YO
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to ONNX format
- model.export(format='onnx') # creates 'yolov8n.onnx'
+ model.export(format="onnx") # creates 'yolov8n.onnx'
# Load the exported ONNX model
- onnx_model = YOLO('yolov8n.onnx')
+ onnx_model = YOLO("yolov8n.onnx")
# Run inference
- results = onnx_model('https://ultralytics.com/images/bus.jpg')
+ results = onnx_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/openvino.md b/docs/en/integrations/openvino.md
index 36d2293c..3a49b00f 100644
--- a/docs/en/integrations/openvino.md
+++ b/docs/en/integrations/openvino.md
@@ -35,16 +35,16 @@ Export a YOLOv8n model to OpenVINO format and run inference with the exported mo
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model
- model.export(format='openvino') # creates 'yolov8n_openvino_model/'
+ model.export(format="openvino") # creates 'yolov8n_openvino_model/'
# Load the exported OpenVINO model
- ov_model = YOLO('yolov8n_openvino_model/')
+ ov_model = YOLO("yolov8n_openvino_model/")
# Run inference
- results = ov_model('https://ultralytics.com/images/bus.jpg')
+ results = ov_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
@@ -259,10 +259,10 @@ To reproduce the Ultralytics benchmarks above on all export [formats](../modes/e
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
- results= model.benchmarks(data='coco8.yaml')
+ results = model.benchmarks(data="coco8.yaml")
```
=== "CLI"
diff --git a/docs/en/integrations/paddlepaddle.md b/docs/en/integrations/paddlepaddle.md
index bc8ccead..97e3e698 100644
--- a/docs/en/integrations/paddlepaddle.md
+++ b/docs/en/integrations/paddlepaddle.md
@@ -77,16 +77,16 @@ Before diving into the usage instructions, it's important to note that while all
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to PaddlePaddle format
- model.export(format='paddle') # creates '/yolov8n_paddle_model'
+ model.export(format="paddle") # creates '/yolov8n_paddle_model'
# Load the exported PaddlePaddle model
- paddle_model = YOLO('./yolov8n_paddle_model')
+ paddle_model = YOLO("./yolov8n_paddle_model")
# Run inference
- results = paddle_model('https://ultralytics.com/images/bus.jpg')
+ results = paddle_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/ray-tune.md b/docs/en/integrations/ray-tune.md
index 9e4a6363..65f6f771 100644
--- a/docs/en/integrations/ray-tune.md
+++ b/docs/en/integrations/ray-tune.md
@@ -50,10 +50,10 @@ To install the required packages, run:
from ultralytics import YOLO
# Load a YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Start tuning hyperparameters for YOLOv8n training on the COCO8 dataset
- result_grid = model.tune(data='coco8.yaml', use_ray=True)
+ result_grid = model.tune(data="coco8.yaml", use_ray=True)
```
## `tune()` Method Parameters
@@ -112,10 +112,12 @@ In this example, we demonstrate how to use a custom search space for hyperparame
model = YOLO("yolov8n.pt")
# Run Ray Tune on the model
- result_grid = model.tune(data="coco8.yaml",
- space={"lr0": tune.uniform(1e-5, 1e-1)},
- epochs=50,
- use_ray=True)
+ result_grid = model.tune(
+ data="coco8.yaml",
+ space={"lr0": tune.uniform(1e-5, 1e-1)},
+ epochs=50,
+ use_ray=True,
+ )
```
In the code snippet above, we create a YOLO model with the "yolov8n.pt" pretrained weights. Then, we call the `tune()` method, specifying the dataset configuration with "coco8.yaml". We provide a custom search space for the initial learning rate `lr0` using a dictionary with the key "lr0" and the value `tune.uniform(1e-5, 1e-1)`. Finally, we pass additional training arguments, such as the number of epochs directly to the tune method as `epochs=50`.
@@ -164,10 +166,14 @@ You can plot the history of reported metrics for each trial to see how the metri
import matplotlib.pyplot as plt
for result in result_grid:
- plt.plot(result.metrics_dataframe["training_iteration"], result.metrics_dataframe["mean_accuracy"], label=f"Trial {i}")
+ plt.plot(
+ result.metrics_dataframe["training_iteration"],
+ result.metrics_dataframe["mean_accuracy"],
+ label=f"Trial {i}",
+ )
-plt.xlabel('Training Iterations')
-plt.ylabel('Mean Accuracy')
+plt.xlabel("Training Iterations")
+plt.ylabel("Mean Accuracy")
plt.legend()
plt.show()
```
diff --git a/docs/en/integrations/tensorrt.md b/docs/en/integrations/tensorrt.md
index 4ffb9cb2..af53d9f7 100644
--- a/docs/en/integrations/tensorrt.md
+++ b/docs/en/integrations/tensorrt.md
@@ -85,16 +85,16 @@ Before diving into the usage instructions, be sure to check out the range of [YO
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to TensorRT format
- model.export(format='engine') # creates 'yolov8n.engine'
+ model.export(format="engine") # creates 'yolov8n.engine'
# Load the exported TensorRT model
- tensorrt_model = YOLO('yolov8n.engine')
+ tensorrt_model = YOLO("yolov8n.engine")
# Run inference
- results = tensorrt_model('https://ultralytics.com/images/bus.jpg')
+ results = tensorrt_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
@@ -434,7 +434,7 @@ Expand sections below for information on how these models were exported and test
result = model.predict(
[img] * 8, # batch=8 of the same image
verbose=False,
- device="cuda"
+ device="cuda",
)
```
@@ -451,7 +451,7 @@ Expand sections below for information on how these models were exported and test
batch=1,
imgsz=640,
verbose=False,
- device="cuda"
+ device="cuda",
)
```
diff --git a/docs/en/integrations/tf-graphdef.md b/docs/en/integrations/tf-graphdef.md
index 68a6ab04..95d6f392 100644
--- a/docs/en/integrations/tf-graphdef.md
+++ b/docs/en/integrations/tf-graphdef.md
@@ -81,16 +81,16 @@ Before diving into the usage instructions, it's important to note that while all
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to TF GraphDef format
- model.export(format='pb') # creates 'yolov8n.pb'
+ model.export(format="pb") # creates 'yolov8n.pb'
# Load the exported TF GraphDef model
- tf_graphdef_model = YOLO('yolov8n.pb')
+ tf_graphdef_model = YOLO("yolov8n.pb")
# Run inference
- results = tf_graphdef_model('https://ultralytics.com/images/bus.jpg')
+ results = tf_graphdef_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/tf-savedmodel.md b/docs/en/integrations/tf-savedmodel.md
index 50a4f228..4fdbd001 100644
--- a/docs/en/integrations/tf-savedmodel.md
+++ b/docs/en/integrations/tf-savedmodel.md
@@ -75,16 +75,16 @@ Before diving into the usage instructions, it's important to note that while all
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to TF SavedModel format
- model.export(format='saved_model') # creates '/yolov8n_saved_model'
+ model.export(format="saved_model") # creates '/yolov8n_saved_model'
# Load the exported TF SavedModel model
- tf_savedmodel_model = YOLO('./yolov8n_saved_model')
+ tf_savedmodel_model = YOLO("./yolov8n_saved_model")
# Run inference
- results = tf_savedmodel_model('https://ultralytics.com/images/bus.jpg')
+ results = tf_savedmodel_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/tfjs.md b/docs/en/integrations/tfjs.md
index 6f80ecc7..513adefb 100644
--- a/docs/en/integrations/tfjs.md
+++ b/docs/en/integrations/tfjs.md
@@ -73,16 +73,16 @@ Before diving into the usage instructions, it's important to note that while all
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to TF.js format
- model.export(format='tfjs') # creates '/yolov8n_web_model'
+ model.export(format="tfjs") # creates '/yolov8n_web_model'
# Load the exported TF.js model
- tfjs_model = YOLO('./yolov8n_web_model')
+ tfjs_model = YOLO("./yolov8n_web_model")
# Run inference
- results = tfjs_model('https://ultralytics.com/images/bus.jpg')
+ results = tfjs_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/tflite.md b/docs/en/integrations/tflite.md
index 03fe1565..5a39185b 100644
--- a/docs/en/integrations/tflite.md
+++ b/docs/en/integrations/tflite.md
@@ -77,18 +77,18 @@ Before diving into the usage instructions, it's important to note that while all
```python
from ultralytics import YOLO
-
+
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
-
+ model = YOLO("yolov8n.pt")
+
# Export the model to TFLite format
- model.export(format='tflite') # creates 'yolov8n_float32.tflite'
-
+ model.export(format="tflite") # creates 'yolov8n_float32.tflite'
+
# Load the exported TFLite model
- tflite_model = YOLO('yolov8n_float32.tflite')
-
+ tflite_model = YOLO("yolov8n_float32.tflite")
+
# Run inference
- results = tflite_model('https://ultralytics.com/images/bus.jpg')
+ results = tflite_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/torchscript.md b/docs/en/integrations/torchscript.md
index f050986c..61ba35af 100644
--- a/docs/en/integrations/torchscript.md
+++ b/docs/en/integrations/torchscript.md
@@ -83,16 +83,16 @@ Before diving into the usage instructions, it's important to note that while all
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Export the model to TorchScript format
- model.export(format='torchscript') # creates 'yolov8n.torchscript'
+ model.export(format="torchscript") # creates 'yolov8n.torchscript'
# Load the exported TorchScript model
- torchscript_model = YOLO('yolov8n.torchscript')
+ torchscript_model = YOLO("yolov8n.torchscript")
# Run inference
- results = torchscript_model('https://ultralytics.com/images/bus.jpg')
+ results = torchscript_model("https://ultralytics.com/images/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/integrations/weights-biases.md b/docs/en/integrations/weights-biases.md
index 3c43b3ea..847172ca 100644
--- a/docs/en/integrations/weights-biases.md
+++ b/docs/en/integrations/weights-biases.md
@@ -63,9 +63,9 @@ Before diving into the usage instructions for YOLOv8 model training with Weights
=== "Python"
```python
+ import wandb
from ultralytics import YOLO
from wandb.integration.ultralytics import add_wandb_callback
- import wandb
# Step 1: Initialize a Weights & Biases run
wandb.init(project="ultralytics", job_type="training")
diff --git a/docs/en/models/fast-sam.md b/docs/en/models/fast-sam.md
index 4e5d77a1..720e2c15 100644
--- a/docs/en/models/fast-sam.md
+++ b/docs/en/models/fast-sam.md
@@ -56,16 +56,16 @@ To perform object detection on an image, use the `predict` method as shown below
from ultralytics.models.fastsam import FastSAMPrompt
# Define an inference source
- source = 'path/to/bus.jpg'
+ source = "path/to/bus.jpg"
# Create a FastSAM model
- model = FastSAM('FastSAM-s.pt') # or FastSAM-x.pt
+ model = FastSAM("FastSAM-s.pt") # or FastSAM-x.pt
# Run inference on an image
- everything_results = model(source, device='cpu', retina_masks=True, imgsz=1024, conf=0.4, iou=0.9)
+ everything_results = model(source, device="cpu", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9)
# Prepare a Prompt Process object
- prompt_process = FastSAMPrompt(source, everything_results, device='cpu')
+ prompt_process = FastSAMPrompt(source, everything_results, device="cpu")
# Everything prompt
ann = prompt_process.everything_prompt()
@@ -74,13 +74,13 @@ To perform object detection on an image, use the `predict` method as shown below
ann = prompt_process.box_prompt(bbox=[200, 200, 300, 300])
# Text prompt
- ann = prompt_process.text_prompt(text='a photo of a dog')
+ ann = prompt_process.text_prompt(text="a photo of a dog")
# Point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[[200, 200]], pointlabel=[1])
- prompt_process.plot(annotations=ann, output='./')
+ prompt_process.plot(annotations=ann, output="./")
```
=== "CLI"
@@ -104,10 +104,10 @@ Validation of the model on a dataset can be done as follows:
from ultralytics import FastSAM
# Create a FastSAM model
- model = FastSAM('FastSAM-s.pt') # or FastSAM-x.pt
+ model = FastSAM("FastSAM-s.pt") # or FastSAM-x.pt
# Validate the model
- results = model.val(data='coco8-seg.yaml')
+ results = model.val(data="coco8-seg.yaml")
```
=== "CLI"
@@ -131,7 +131,7 @@ To perform object tracking on an image, use the `track` method as shown below:
from ultralytics import FastSAM
# Create a FastSAM model
- model = FastSAM('FastSAM-s.pt') # or FastSAM-x.pt
+ model = FastSAM("FastSAM-s.pt") # or FastSAM-x.pt
# Track with a FastSAM model on a video
results = model.track(source="path/to/video.mp4", imgsz=640)
diff --git a/docs/en/models/index.md b/docs/en/models/index.md
index 70a70ef9..ead6ccab 100644
--- a/docs/en/models/index.md
+++ b/docs/en/models/index.md
@@ -53,16 +53,16 @@ Note the below example is for YOLOv8 [Detect](../tasks/detect.md) models for obj
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/models/mobile-sam.md b/docs/en/models/mobile-sam.md
index f868ef4d..496263ca 100644
--- a/docs/en/models/mobile-sam.md
+++ b/docs/en/models/mobile-sam.md
@@ -77,10 +77,10 @@ You can download the model [here](https://github.com/ChaoningZhang/MobileSAM/blo
from ultralytics import SAM
# Load the model
- model = SAM('mobile_sam.pt')
+ model = SAM("mobile_sam.pt")
# Predict a segment based on a point prompt
- model.predict('ultralytics/assets/zidane.jpg', points=[900, 370], labels=[1])
+ model.predict("ultralytics/assets/zidane.jpg", points=[900, 370], labels=[1])
```
### Box Prompt
@@ -93,10 +93,10 @@ You can download the model [here](https://github.com/ChaoningZhang/MobileSAM/blo
from ultralytics import SAM
# Load the model
- model = SAM('mobile_sam.pt')
+ model = SAM("mobile_sam.pt")
# Predict a segment based on a box prompt
- model.predict('ultralytics/assets/zidane.jpg', bboxes=[439, 437, 524, 709])
+ model.predict("ultralytics/assets/zidane.jpg", bboxes=[439, 437, 524, 709])
```
We have implemented `MobileSAM` and `SAM` using the same API. For more usage information, please see the [SAM page](sam.md).
diff --git a/docs/en/models/rtdetr.md b/docs/en/models/rtdetr.md
index 7bfe2eae..b70f0b58 100644
--- a/docs/en/models/rtdetr.md
+++ b/docs/en/models/rtdetr.md
@@ -48,16 +48,16 @@ This example provides simple RT-DETR training and inference examples. For full d
from ultralytics import RTDETR
# Load a COCO-pretrained RT-DETR-l model
- model = RTDETR('rtdetr-l.pt')
+ model = RTDETR("rtdetr-l.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the RT-DETR-l model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/models/sam.md b/docs/en/models/sam.md
index e3e14b87..45b2c13d 100644
--- a/docs/en/models/sam.md
+++ b/docs/en/models/sam.md
@@ -50,16 +50,16 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
from ultralytics import SAM
# Load a model
- model = SAM('sam_b.pt')
+ model = SAM("sam_b.pt")
# Display model information (optional)
model.info()
# Run inference with bboxes prompt
- model('ultralytics/assets/zidane.jpg', bboxes=[439, 437, 524, 709])
+ model("ultralytics/assets/zidane.jpg", bboxes=[439, 437, 524, 709])
# Run inference with points prompt
- model('ultralytics/assets/zidane.jpg', points=[900, 370], labels=[1])
+ model("ultralytics/assets/zidane.jpg", points=[900, 370], labels=[1])
```
!!! Example "Segment everything"
@@ -72,13 +72,13 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
from ultralytics import SAM
# Load a model
- model = SAM('sam_b.pt')
+ model = SAM("sam_b.pt")
# Display model information (optional)
model.info()
# Run inference
- model('path/to/image.jpg')
+ model("path/to/image.jpg")
```
=== "CLI"
@@ -100,7 +100,7 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
from ultralytics.models.sam import Predictor as SAMPredictor
# Create SAMPredictor
- overrides = dict(conf=0.25, task='segment', mode='predict', imgsz=1024, model="mobile_sam.pt")
+ overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=1024, model="mobile_sam.pt")
predictor = SAMPredictor(overrides=overrides)
# Set image
@@ -121,7 +121,7 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
from ultralytics.models.sam import Predictor as SAMPredictor
# Create SAMPredictor
- overrides = dict(conf=0.25, task='segment', mode='predict', imgsz=1024, model="mobile_sam.pt")
+ overrides = dict(conf=0.25, task="segment", mode="predict", imgsz=1024, model="mobile_sam.pt")
predictor = SAMPredictor(overrides=overrides)
# Segment with additional args
@@ -150,27 +150,27 @@ Tests run on a 2023 Apple M2 Macbook with 16GB of RAM. To reproduce this test:
=== "Python"
```python
- from ultralytics import FastSAM, SAM, YOLO
+ from ultralytics import SAM, YOLO, FastSAM
# Profile SAM-b
- model = SAM('sam_b.pt')
+ model = SAM("sam_b.pt")
model.info()
- model('ultralytics/assets')
+ model("ultralytics/assets")
# Profile MobileSAM
- model = SAM('mobile_sam.pt')
+ model = SAM("mobile_sam.pt")
model.info()
- model('ultralytics/assets')
+ model("ultralytics/assets")
# Profile FastSAM-s
- model = FastSAM('FastSAM-s.pt')
+ model = FastSAM("FastSAM-s.pt")
model.info()
- model('ultralytics/assets')
+ model("ultralytics/assets")
# Profile YOLOv8n-seg
- model = YOLO('yolov8n-seg.pt')
+ model = YOLO("yolov8n-seg.pt")
model.info()
- model('ultralytics/assets')
+ model("ultralytics/assets")
```
## Auto-Annotation: A Quick Path to Segmentation Datasets
@@ -188,7 +188,7 @@ To auto-annotate your dataset with the Ultralytics framework, use the `auto_anno
```python
from ultralytics.data.annotator import auto_annotate
- auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model='sam_b.pt')
+ auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam_b.pt")
```
| Argument | Type | Description | Default |
diff --git a/docs/en/models/yolo-nas.md b/docs/en/models/yolo-nas.md
index bc07187f..fff2197d 100644
--- a/docs/en/models/yolo-nas.md
+++ b/docs/en/models/yolo-nas.md
@@ -55,16 +55,16 @@ In this example we validate YOLO-NAS-s on the COCO8 dataset.
from ultralytics import NAS
# Load a COCO-pretrained YOLO-NAS-s model
- model = NAS('yolo_nas_s.pt')
+ model = NAS("yolo_nas_s.pt")
# Display model information (optional)
model.info()
# Validate the model on the COCO8 example dataset
- results = model.val(data='coco8.yaml')
+ results = model.val(data="coco8.yaml")
# Run inference with the YOLO-NAS-s model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/models/yolo-world.md b/docs/en/models/yolo-world.md
index 4477471b..3052de5e 100644
--- a/docs/en/models/yolo-world.md
+++ b/docs/en/models/yolo-world.md
@@ -92,13 +92,13 @@ Object detection is straightforward with the `train` method, as illustrated belo
from ultralytics import YOLOWorld
# Load a pretrained YOLOv8s-worldv2 model
- model = YOLOWorld('yolov8s-worldv2.pt')
+ model = YOLOWorld("yolov8s-worldv2.pt")
# Train the model on the COCO8 example dataset for 100 epochs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
@@ -120,10 +120,10 @@ Object detection is straightforward with the `predict` method, as illustrated be
from ultralytics import YOLOWorld
# Initialize a YOLO-World model
- model = YOLOWorld('yolov8s-world.pt') # or select yolov8m/l-world.pt for different sizes
+ model = YOLOWorld("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
# Execute inference with the YOLOv8s-world model on the specified image
- results = model.predict('path/to/image.jpg')
+ results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
@@ -150,10 +150,10 @@ Model validation on a dataset is streamlined as follows:
from ultralytics import YOLO
# Create a YOLO-World model
- model = YOLO('yolov8s-world.pt') # or select yolov8m/l-world.pt for different sizes
+ model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
# Conduct model validation on the COCO8 example dataset
- metrics = model.val(data='coco8.yaml')
+ metrics = model.val(data="coco8.yaml")
```
=== "CLI"
@@ -175,7 +175,7 @@ Object tracking with YOLO-World model on a video/images is streamlined as follow
from ultralytics import YOLO
# Create a YOLO-World model
- model = YOLO('yolov8s-world.pt') # or select yolov8m/l-world.pt for different sizes
+ model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt for different sizes
# Track with a YOLO-World model on a video
results = model.track(source="path/to/video.mp4")
@@ -208,13 +208,13 @@ For instance, if your application only requires detecting 'person' and 'bus' obj
from ultralytics import YOLO
# Initialize a YOLO-World model
- model = YOLO('yolov8s-world.pt') # or choose yolov8m/l-world.pt
-
+ model = YOLO("yolov8s-world.pt") # or choose yolov8m/l-world.pt
+
# Define custom classes
model.set_classes(["person", "bus"])
# Execute prediction for specified categories on an image
- results = model.predict('path/to/image.jpg')
+ results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
@@ -232,8 +232,8 @@ You can also save a model after setting custom classes. By doing this you create
from ultralytics import YOLO
# Initialize a YOLO-World model
- model = YOLO('yolov8s-world.pt') # or select yolov8m/l-world.pt
-
+ model = YOLO("yolov8s-world.pt") # or select yolov8m/l-world.pt
+
# Define custom classes
model.set_classes(["person", "bus"])
@@ -247,10 +247,10 @@ You can also save a model after setting custom classes. By doing this you create
from ultralytics import YOLO
# Load your custom model
- model = YOLO('custom_yolov8s.pt')
+ model = YOLO("custom_yolov8s.pt")
# Run inference to detect your custom classes
- results = model.predict('path/to/image.jpg')
+ results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
@@ -294,8 +294,8 @@ This approach provides a powerful means of customizing state-of-the-art object d
=== "Python"
```python
- from ultralytics.models.yolo.world.train_world import WorldTrainerFromScratch
from ultralytics import YOLOWorld
+ from ultralytics.models.yolo.world.train_world import WorldTrainerFromScratch
data = dict(
train=dict(
@@ -315,7 +315,6 @@ This approach provides a powerful means of customizing state-of-the-art object d
)
model = YOLOWorld("yolov8s-worldv2.yaml")
model.train(data=data, batch=128, epochs=100, trainer=WorldTrainerFromScratch)
-
```
## Citations and Acknowledgements
diff --git a/docs/en/models/yolov3.md b/docs/en/models/yolov3.md
index f24562f4..5779b860 100644
--- a/docs/en/models/yolov3.md
+++ b/docs/en/models/yolov3.md
@@ -54,16 +54,16 @@ This example provides simple YOLOv3 training and inference examples. For full do
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv3n model
- model = YOLO('yolov3n.pt')
+ model = YOLO("yolov3n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv3n model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/models/yolov5.md b/docs/en/models/yolov5.md
index 67a2b14b..744a4f43 100644
--- a/docs/en/models/yolov5.md
+++ b/docs/en/models/yolov5.md
@@ -66,16 +66,16 @@ This example provides simple YOLOv5 training and inference examples. For full do
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv5n model
- model = YOLO('yolov5n.pt')
+ model = YOLO("yolov5n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv5n model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/models/yolov6.md b/docs/en/models/yolov6.md
index 3607917b..481a0e2c 100644
--- a/docs/en/models/yolov6.md
+++ b/docs/en/models/yolov6.md
@@ -46,16 +46,16 @@ This example provides simple YOLOv6 training and inference examples. For full do
from ultralytics import YOLO
# Build a YOLOv6n model from scratch
- model = YOLO('yolov6n.yaml')
+ model = YOLO("yolov6n.yaml")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv6n model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/models/yolov8.md b/docs/en/models/yolov8.md
index 8b3aebc6..5a2d8dc7 100644
--- a/docs/en/models/yolov8.md
+++ b/docs/en/models/yolov8.md
@@ -139,16 +139,16 @@ Note the below example is for YOLOv8 [Detect](../tasks/detect.md) models for obj
from ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/models/yolov9.md b/docs/en/models/yolov9.md
index e84b138b..e89161dd 100644
--- a/docs/en/models/yolov9.md
+++ b/docs/en/models/yolov9.md
@@ -110,19 +110,19 @@ This example provides simple YOLOv9 training and inference examples. For full do
from ultralytics import YOLO
# Build a YOLOv9c model from scratch
- model = YOLO('yolov9c.yaml')
+ model = YOLO("yolov9c.yaml")
# Build a YOLOv9c model from pretrained weight
- model = YOLO('yolov9c.pt')
+ model = YOLO("yolov9c.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv9c model on the 'bus.jpg' image
- results = model('path/to/bus.jpg')
+ results = model("path/to/bus.jpg")
```
=== "CLI"
diff --git a/docs/en/modes/benchmark.md b/docs/en/modes/benchmark.md
index d33e543b..9af9d140 100644
--- a/docs/en/modes/benchmark.md
+++ b/docs/en/modes/benchmark.md
@@ -60,7 +60,7 @@ Run YOLOv8n benchmarks on all supported export formats including ONNX, TensorRT
from ultralytics.utils.benchmarks import benchmark
# Benchmark on GPU
- benchmark(model='yolov8n.pt', data='coco8.yaml', imgsz=640, half=False, device=0)
+ benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
```
=== "CLI"
diff --git a/docs/en/modes/export.md b/docs/en/modes/export.md
index df401214..c9e7237d 100644
--- a/docs/en/modes/export.md
+++ b/docs/en/modes/export.md
@@ -56,11 +56,11 @@ Export a YOLOv8n model to a different format like ONNX or TensorRT. See Argument
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom trained model
+ model = YOLO("yolov8n.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
- model.export(format='onnx')
+ model.export(format="onnx")
```
=== "CLI"
diff --git a/docs/en/modes/predict.md b/docs/en/modes/predict.md
index e17fdd3f..ee5ef58c 100644
--- a/docs/en/modes/predict.md
+++ b/docs/en/modes/predict.md
@@ -58,10 +58,10 @@ Ultralytics YOLO models return either a Python list of `Results` objects, or a m
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt") # pretrained YOLOv8n model
# Run batched inference on a list of images
- results = model(['im1.jpg', 'im2.jpg']) # return a list of Results objects
+ results = model(["im1.jpg", "im2.jpg"]) # return a list of Results objects
# Process results list
for result in results:
@@ -71,7 +71,7 @@ Ultralytics YOLO models return either a Python list of `Results` objects, or a m
probs = result.probs # Probs object for classification outputs
obb = result.obb # Oriented boxes object for OBB outputs
result.show() # display to screen
- result.save(filename='result.jpg') # save to disk
+ result.save(filename="result.jpg") # save to disk
```
=== "Return a generator with `stream=True`"
@@ -80,10 +80,10 @@ Ultralytics YOLO models return either a Python list of `Results` objects, or a m
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # pretrained YOLOv8n model
+ model = YOLO("yolov8n.pt") # pretrained YOLOv8n model
# Run batched inference on a list of images
- results = model(['im1.jpg', 'im2.jpg'], stream=True) # return a generator of Results objects
+ results = model(["im1.jpg", "im2.jpg"], stream=True) # return a generator of Results objects
# Process results generator
for result in results:
@@ -93,7 +93,7 @@ Ultralytics YOLO models return either a Python list of `Results` objects, or a m
probs = result.probs # Probs object for classification outputs
obb = result.obb # Oriented boxes object for OBB outputs
result.show() # display to screen
- result.save(filename='result.jpg') # save to disk
+ result.save(filename="result.jpg") # save to disk
```
## Inference Sources
@@ -132,10 +132,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Define path to the image file
- source = 'path/to/image.jpg'
+ source = "path/to/image.jpg"
# Run inference on the source
results = model(source) # list of Results objects
@@ -148,10 +148,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Define current screenshot as source
- source = 'screen'
+ source = "screen"
# Run inference on the source
results = model(source) # list of Results objects
@@ -164,10 +164,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Define remote image or video URL
- source = 'https://ultralytics.com/images/bus.jpg'
+ source = "https://ultralytics.com/images/bus.jpg"
# Run inference on the source
results = model(source) # list of Results objects
@@ -181,10 +181,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Open an image using PIL
- source = Image.open('path/to/image.jpg')
+ source = Image.open("path/to/image.jpg")
# Run inference on the source
results = model(source) # list of Results objects
@@ -198,10 +198,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Read an image using OpenCV
- source = cv2.imread('path/to/image.jpg')
+ source = cv2.imread("path/to/image.jpg")
# Run inference on the source
results = model(source) # list of Results objects
@@ -215,10 +215,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Create a random numpy array of HWC shape (640, 640, 3) with values in range [0, 255] and type uint8
- source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype='uint8')
+ source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype="uint8")
# Run inference on the source
results = model(source) # list of Results objects
@@ -232,7 +232,7 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Create a random torch tensor of BCHW shape (1, 3, 640, 640) with values in range [0, 1] and type float32
source = torch.rand(1, 3, 640, 640, dtype=torch.float32)
@@ -249,10 +249,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Define a path to a CSV file with images, URLs, videos and directories
- source = 'path/to/file.csv'
+ source = "path/to/file.csv"
# Run inference on the source
results = model(source) # list of Results objects
@@ -265,10 +265,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Define path to video file
- source = 'path/to/video.mp4'
+ source = "path/to/video.mp4"
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
@@ -281,10 +281,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Define path to directory containing images and videos for inference
- source = 'path/to/dir'
+ source = "path/to/dir"
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
@@ -297,13 +297,13 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Define a glob search for all JPG files in a directory
- source = 'path/to/dir/*.jpg'
+ source = "path/to/dir/*.jpg"
# OR define a recursive glob search for all JPG files including subdirectories
- source = 'path/to/dir/**/*.jpg'
+ source = "path/to/dir/**/*.jpg"
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
@@ -316,10 +316,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Define source as YouTube video URL
- source = 'https://youtu.be/LNwODJXcvt4'
+ source = "https://youtu.be/LNwODJXcvt4"
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
@@ -332,13 +332,13 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Single stream with batch-size 1 inference
- source = 'rtsp://example.com/media.mp4' # RTSP, RTMP, TCP or IP streaming address
+ source = "rtsp://example.com/media.mp4" # RTSP, RTMP, TCP or IP streaming address
# Multiple streams with batched inference (i.e. batch-size 8 for 8 streams)
- source = 'path/to/list.streams' # *.streams text file with one streaming address per row
+ source = "path/to/list.streams" # *.streams text file with one streaming address per row
# Run inference on the source
results = model(source, stream=True) # generator of Results objects
@@ -354,10 +354,10 @@ Below are code examples for using each source type:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Run inference on 'bus.jpg' with arguments
- model.predict('bus.jpg', save=True, imgsz=320, conf=0.5)
+ model.predict("bus.jpg", save=True, imgsz=320, conf=0.5)
```
Inference arguments:
@@ -445,11 +445,11 @@ All Ultralytics `predict()` calls will return a list of `Results` objects:
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Run inference on an image
- results = model('bus.jpg') # list of 1 Results object
- results = model(['bus.jpg', 'zidane.jpg']) # list of 2 Results objects
+ results = model("bus.jpg") # list of 1 Results object
+ results = model(["bus.jpg", "zidane.jpg"]) # list of 2 Results objects
```
`Results` objects have the following attributes:
@@ -497,10 +497,10 @@ For more details see the [`Results` class documentation](../reference/engine/res
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Run inference on an image
- results = model('bus.jpg') # results list
+ results = model("bus.jpg") # results list
# View results
for r in results:
@@ -535,10 +535,10 @@ For more details see the [`Boxes` class documentation](../reference/engine/resul
from ultralytics import YOLO
# Load a pretrained YOLOv8n-seg Segment model
- model = YOLO('yolov8n-seg.pt')
+ model = YOLO("yolov8n-seg.pt")
# Run inference on an image
- results = model('bus.jpg') # results list
+ results = model("bus.jpg") # results list
# View results
for r in results:
@@ -568,10 +568,10 @@ For more details see the [`Masks` class documentation](../reference/engine/resul
from ultralytics import YOLO
# Load a pretrained YOLOv8n-pose Pose model
- model = YOLO('yolov8n-pose.pt')
+ model = YOLO("yolov8n-pose.pt")
# Run inference on an image
- results = model('bus.jpg') # results list
+ results = model("bus.jpg") # results list
# View results
for r in results:
@@ -602,10 +602,10 @@ For more details see the [`Keypoints` class documentation](../reference/engine/r
from ultralytics import YOLO
# Load a pretrained YOLOv8n-cls Classify model
- model = YOLO('yolov8n-cls.pt')
+ model = YOLO("yolov8n-cls.pt")
# Run inference on an image
- results = model('bus.jpg') # results list
+ results = model("bus.jpg") # results list
# View results
for r in results:
@@ -637,10 +637,10 @@ For more details see the [`Probs` class documentation](../reference/engine/resul
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n-obb.pt')
+ model = YOLO("yolov8n-obb.pt")
# Run inference on an image
- results = model('bus.jpg') # results list
+ results = model("bus.jpg") # results list
# View results
for r in results:
@@ -676,22 +676,22 @@ The `plot()` method in `Results` objects facilitates visualization of prediction
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Run inference on 'bus.jpg'
- results = model(['bus.jpg', 'zidane.jpg']) # results list
+ results = model(["bus.jpg", "zidane.jpg"]) # results list
# Visualize the results
for i, r in enumerate(results):
# Plot results image
im_bgr = r.plot() # BGR-order numpy array
im_rgb = Image.fromarray(im_bgr[..., ::-1]) # RGB-order PIL image
-
+
# Show results to screen (in supported environments)
r.show()
# Save results to disk
- r.save(filename=f'results{i}.jpg')
+ r.save(filename=f"results{i}.jpg")
```
### `plot()` Method Parameters
@@ -727,9 +727,11 @@ When using YOLO models in a multi-threaded application, it's important to instan
Instantiate a single model inside each thread for thread-safe inference:
```python
- from ultralytics import YOLO
from threading import Thread
+ from ultralytics import YOLO
+
+
def thread_safe_predict(image_path):
"""Performs thread-safe prediction on an image using a locally instantiated YOLO model."""
local_model = YOLO("yolov8n.pt")
@@ -755,7 +757,7 @@ Here's a Python script using OpenCV (`cv2`) and YOLOv8 to run inference on video
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Open the video file
video_path = "path/to/your/video/file.mp4"
diff --git a/docs/en/modes/track.md b/docs/en/modes/track.md
index a1a05434..a72c5578 100644
--- a/docs/en/modes/track.md
+++ b/docs/en/modes/track.md
@@ -70,14 +70,14 @@ To run the tracker on video streams, use a trained Detect, Segment or Pose model
from ultralytics import YOLO
# Load an official or custom model
- model = YOLO('yolov8n.pt') # Load an official Detect model
- model = YOLO('yolov8n-seg.pt') # Load an official Segment model
- model = YOLO('yolov8n-pose.pt') # Load an official Pose model
- model = YOLO('path/to/best.pt') # Load a custom trained model
+ model = YOLO("yolov8n.pt") # Load an official Detect model
+ model = YOLO("yolov8n-seg.pt") # Load an official Segment model
+ model = YOLO("yolov8n-pose.pt") # Load an official Pose model
+ model = YOLO("path/to/best.pt") # Load a custom trained model
# Perform tracking with the model
- results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True) # Tracking with default tracker
- results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # Tracking with ByteTrack tracker
+ results = model.track("https://youtu.be/LNwODJXcvt4", show=True) # Tracking with default tracker
+ results = model.track("https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # with ByteTrack
```
=== "CLI"
@@ -113,7 +113,7 @@ Tracking configuration shares properties with Predict mode, such as `conf`, `iou
from ultralytics import YOLO
# Configure the tracking parameters and run the tracker
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
```
@@ -136,8 +136,8 @@ Ultralytics also allows you to use a modified tracker configuration file. To do
from ultralytics import YOLO
# Load the model and run the tracker with a custom configuration file
- model = YOLO('yolov8n.pt')
- results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker='custom_tracker.yaml')
+ model = YOLO("yolov8n.pt")
+ results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker="custom_tracker.yaml")
```
=== "CLI"
@@ -162,7 +162,7 @@ Here is a Python script using OpenCV (`cv2`) and YOLOv8 to run object tracking o
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Open the video file
video_path = "path/to/video.mp4"
@@ -210,11 +210,10 @@ In the following example, we demonstrate how to utilize YOLOv8's tracking capabi
import cv2
import numpy as np
-
from ultralytics import YOLO
# Load the YOLOv8 model
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Open the video file
video_path = "path/to/video.mp4"
@@ -284,6 +283,7 @@ Finally, after all threads have completed their task, the windows displaying the
```python
import threading
+
import cv2
from ultralytics import YOLO
@@ -318,7 +318,7 @@ Finally, after all threads have completed their task, the windows displaying the
cv2.imshow(f"Tracking_Stream_{file_index}", res_plotted)
key = cv2.waitKey(1)
- if key == ord('q'):
+ if key == ord("q"):
break
# Release video sources
@@ -326,8 +326,8 @@ Finally, after all threads have completed their task, the windows displaying the
# Load the models
- model1 = YOLO('yolov8n.pt')
- model2 = YOLO('yolov8n-seg.pt')
+ model1 = YOLO("yolov8n.pt")
+ model2 = YOLO("yolov8n-seg.pt")
# Define the video files for the trackers
video_file1 = "path/to/video1.mp4" # Path to video file, 0 for webcam
diff --git a/docs/en/modes/train.md b/docs/en/modes/train.md
index 6b644177..d04a84db 100644
--- a/docs/en/modes/train.md
+++ b/docs/en/modes/train.md
@@ -59,12 +59,12 @@ Train YOLOv8n on the COCO8 dataset for 100 epochs at image size 640. The trainin
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.yaml') # build a new model from YAML
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
- model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+ model = YOLO("yolov8n.yaml") # build a new model from YAML
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -94,10 +94,10 @@ Multi-GPU training allows for more efficient utilization of available hardware r
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model with 2 GPUs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640, device=[0, 1])
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=[0, 1])
```
=== "CLI"
@@ -121,10 +121,10 @@ To enable training on Apple M1 and M2 chips, you should specify 'mps' as your de
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Train the model with 2 GPUs
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640, device='mps')
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device="mps")
```
=== "CLI"
@@ -154,7 +154,7 @@ Below is an example of how to resume an interrupted training using Python and vi
from ultralytics import YOLO
# Load a model
- model = YOLO('path/to/last.pt') # load a partially trained model
+ model = YOLO("path/to/last.pt") # load a partially trained model
# Resume training
results = model.train(resume=True)
diff --git a/docs/en/modes/val.md b/docs/en/modes/val.md
index 96703cba..98f6fd00 100644
--- a/docs/en/modes/val.md
+++ b/docs/en/modes/val.md
@@ -57,15 +57,15 @@ Validate trained YOLOv8n model accuracy on the COCO8 dataset. No argument need t
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
- metrics.box.map # map50-95
+ metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
- metrics.box.maps # a list contains map50-95 of each category
+ metrics.box.maps # a list contains map50-95 of each category
```
=== "CLI"
@@ -108,17 +108,12 @@ The below examples showcase YOLO model validation with custom arguments in Pytho
```python
from ultralytics import YOLO
-
+
# Load a model
- model = YOLO('yolov8n.pt')
-
+ model = YOLO("yolov8n.pt")
+
# Customize validation settings
- validation_results = model.val(data='coco8.yaml',
- imgsz=640,
- batch=16,
- conf=0.25,
- iou=0.6,
- device='0')
+ validation_results = model.val(data="coco8.yaml", imgsz=640, batch=16, conf=0.25, iou=0.6, device="0")
```
=== "CLI"
diff --git a/docs/en/quickstart.md b/docs/en/quickstart.md
index 59095d56..f9fdc71c 100644
--- a/docs/en/quickstart.md
+++ b/docs/en/quickstart.md
@@ -220,22 +220,22 @@ For example, users can load a model, train it, evaluate its performance on a val
from ultralytics import YOLO
# Create a new YOLO model from scratch
- model = YOLO('yolov8n.yaml')
+ model = YOLO("yolov8n.yaml")
# Load a pretrained YOLO model (recommended for training)
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Train the model using the 'coco8.yaml' dataset for 3 epochs
- results = model.train(data='coco8.yaml', epochs=3)
+ results = model.train(data="coco8.yaml", epochs=3)
# Evaluate the model's performance on the validation set
results = model.val()
# Perform object detection on an image using the model
- results = model('https://ultralytics.com/images/bus.jpg')
+ results = model("https://ultralytics.com/images/bus.jpg")
# Export the model to ONNX format
- success = model.export(format='onnx')
+ success = model.export(format="onnx")
```
[Python Guide](usage/python.md){.md-button .md-button--primary}
@@ -259,7 +259,7 @@ To gain insight into the current configuration of your settings, you can view th
print(settings)
# Return a specific setting
- value = settings['runs_dir']
+ value = settings["runs_dir"]
```
=== "CLI"
@@ -280,10 +280,10 @@ Ultralytics allows users to easily modify their settings. Changes can be perform
from ultralytics import settings
# Update a setting
- settings.update({'runs_dir': '/path/to/runs'})
+ settings.update({"runs_dir": "/path/to/runs"})
# Update multiple settings
- settings.update({'runs_dir': '/path/to/runs', 'tensorboard': False})
+ settings.update({"runs_dir": "/path/to/runs", "tensorboard": False})
# Reset settings to default values
settings.reset()
diff --git a/docs/en/tasks/classify.md b/docs/en/tasks/classify.md
index a527e25e..fcc76842 100644
--- a/docs/en/tasks/classify.md
+++ b/docs/en/tasks/classify.md
@@ -56,12 +56,12 @@ Train YOLOv8n-cls on the MNIST160 dataset for 100 epochs at image size 64. For a
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.yaml') # build a new model from YAML
- model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
- model = YOLO('yolov8n-cls.yaml').load('yolov8n-cls.pt') # build from YAML and transfer weights
+ model = YOLO("yolov8n-cls.yaml") # build a new model from YAML
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-cls.yaml").load("yolov8n-cls.pt") # build from YAML and transfer weights
# Train the model
- results = model.train(data='mnist160', epochs=100, imgsz=64)
+ results = model.train(data="mnist160", epochs=100, imgsz=64)
```
=== "CLI"
@@ -93,13 +93,13 @@ Validate trained YOLOv8n-cls model accuracy on the MNIST160 dataset. No argument
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n-cls.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
- metrics.top1 # top1 accuracy
- metrics.top5 # top5 accuracy
+ metrics.top1 # top1 accuracy
+ metrics.top5 # top5 accuracy
```
=== "CLI"
@@ -120,11 +120,11 @@ Use a trained YOLOv8n-cls model to run predictions on images.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n-cls.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
- results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
```
=== "CLI"
@@ -147,11 +147,11 @@ Export a YOLOv8n-cls model to a different format like ONNX, CoreML, etc.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-cls.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom trained model
+ model = YOLO("yolov8n-cls.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
- model.export(format='onnx')
+ model.export(format="onnx")
```
=== "CLI"
diff --git a/docs/en/tasks/detect.md b/docs/en/tasks/detect.md
index a6bae4e8..7782e66c 100644
--- a/docs/en/tasks/detect.md
+++ b/docs/en/tasks/detect.md
@@ -56,12 +56,12 @@ Train YOLOv8n on the COCO8 dataset for 100 epochs at image size 640. For a full
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.yaml') # build a new model from YAML
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
- model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+ model = YOLO("yolov8n.yaml") # build a new model from YAML
+ model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
- results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -92,15 +92,15 @@ Validate trained YOLOv8n model accuracy on the COCO8 dataset. No argument need t
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
- metrics.box.map # map50-95
+ metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
- metrics.box.maps # a list contains map50-95 of each category
+ metrics.box.maps # a list contains map50-95 of each category
```
=== "CLI"
@@ -121,11 +121,11 @@ Use a trained YOLOv8n model to run predictions on images.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
- results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
```
=== "CLI"
@@ -148,11 +148,11 @@ Export a YOLOv8n model to a different format like ONNX, CoreML, etc.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom trained model
+ model = YOLO("yolov8n.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
- model.export(format='onnx')
+ model.export(format="onnx")
```
=== "CLI"
diff --git a/docs/en/tasks/obb.md b/docs/en/tasks/obb.md
index 7755f45e..93d14ea1 100644
--- a/docs/en/tasks/obb.md
+++ b/docs/en/tasks/obb.md
@@ -76,12 +76,12 @@ Train YOLOv8n-obb on the `dota8.yaml` dataset for 100 epochs at image size 640.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-obb.yaml') # build a new model from YAML
- model = YOLO('yolov8n-obb.pt') # load a pretrained model (recommended for training)
- model = YOLO('yolov8n-obb.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+ model = YOLO("yolov8n-obb.yaml") # build a new model from YAML
+ model = YOLO("yolov8n-obb.pt") # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-obb.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
- results = model.train(data='dota8.yaml', epochs=100, imgsz=640)
+ results = model.train(data="dota8.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -113,15 +113,15 @@ retains its training `data` and arguments as model attributes.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-obb.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n-obb.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
- metrics = model.val(data='dota8.yaml') # no arguments needed, dataset and settings remembered
- metrics.box.map # map50-95(B)
+ metrics = model.val(data="dota8.yaml") # no arguments needed, dataset and settings remembered
+ metrics.box.map # map50-95(B)
metrics.box.map50 # map50(B)
metrics.box.map75 # map75(B)
- metrics.box.maps # a list contains map50-95(B) of each category
+ metrics.box.maps # a list contains map50-95(B) of each category
```
=== "CLI"
@@ -142,11 +142,11 @@ Use a trained YOLOv8n-obb model to run predictions on images.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-obb.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n-obb.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
- results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
```
=== "CLI"
@@ -169,11 +169,11 @@ Export a YOLOv8n-obb model to a different format like ONNX, CoreML, etc.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-obb.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom trained model
+ model = YOLO("yolov8n-obb.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
- model.export(format='onnx')
+ model.export(format="onnx")
```
=== "CLI"
diff --git a/docs/en/tasks/pose.md b/docs/en/tasks/pose.md
index 13fa05fe..d8c5ed34 100644
--- a/docs/en/tasks/pose.md
+++ b/docs/en/tasks/pose.md
@@ -69,12 +69,12 @@ Train a YOLOv8-pose model on the COCO128-pose dataset.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-pose.yaml') # build a new model from YAML
- model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
- model = YOLO('yolov8n-pose.yaml').load('yolov8n-pose.pt') # build from YAML and transfer weights
+ model = YOLO("yolov8n-pose.yaml") # build a new model from YAML
+ model = YOLO("yolov8n-pose.pt") # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-pose.yaml").load("yolov8n-pose.pt") # build from YAML and transfer weights
# Train the model
- results = model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8-pose.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -107,15 +107,15 @@ retains its training `data` and arguments as model attributes.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-pose.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n-pose.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
- metrics.box.map # map50-95
+ metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
- metrics.box.maps # a list contains map50-95 of each category
+ metrics.box.maps # a list contains map50-95 of each category
```
=== "CLI"
@@ -136,11 +136,11 @@ Use a trained YOLOv8n-pose model to run predictions on images.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-pose.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n-pose.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
- results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
```
=== "CLI"
@@ -163,11 +163,11 @@ Export a YOLOv8n Pose model to a different format like ONNX, CoreML, etc.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-pose.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom trained model
+ model = YOLO("yolov8n-pose.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
- model.export(format='onnx')
+ model.export(format="onnx")
```
=== "CLI"
diff --git a/docs/en/tasks/segment.md b/docs/en/tasks/segment.md
index ea7bfdb1..a73ddb3f 100644
--- a/docs/en/tasks/segment.md
+++ b/docs/en/tasks/segment.md
@@ -56,12 +56,12 @@ Train YOLOv8n-seg on the COCO128-seg dataset for 100 epochs at image size 640. F
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.yaml') # build a new model from YAML
- model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
- model = YOLO('yolov8n-seg.yaml').load('yolov8n.pt') # build from YAML and transfer weights
+ model = YOLO("yolov8n-seg.yaml") # build a new model from YAML
+ model = YOLO("yolov8n-seg.pt") # load a pretrained model (recommended for training)
+ model = YOLO("yolov8n-seg.yaml").load("yolov8n.pt") # build from YAML and transfer weights
# Train the model
- results = model.train(data='coco8-seg.yaml', epochs=100, imgsz=640)
+ results = model.train(data="coco8-seg.yaml", epochs=100, imgsz=640)
```
=== "CLI"
@@ -93,19 +93,19 @@ retains its training `data` and arguments as model attributes.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n-seg.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
- metrics.box.map # map50-95(B)
+ metrics.box.map # map50-95(B)
metrics.box.map50 # map50(B)
metrics.box.map75 # map75(B)
- metrics.box.maps # a list contains map50-95(B) of each category
- metrics.seg.map # map50-95(M)
+ metrics.box.maps # a list contains map50-95(B) of each category
+ metrics.seg.map # map50-95(M)
metrics.seg.map50 # map50(M)
metrics.seg.map75 # map75(M)
- metrics.seg.maps # a list contains map50-95(M) of each category
+ metrics.seg.maps # a list contains map50-95(M) of each category
```
=== "CLI"
@@ -126,11 +126,11 @@ Use a trained YOLOv8n-seg model to run predictions on images.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n-seg.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom model
# Predict with the model
- results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
+ results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
```
=== "CLI"
@@ -153,11 +153,11 @@ Export a YOLOv8n-seg model to a different format like ONNX, CoreML, etc.
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n-seg.pt') # load an official model
- model = YOLO('path/to/best.pt') # load a custom trained model
+ model = YOLO("yolov8n-seg.pt") # load an official model
+ model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
- model.export(format='onnx')
+ model.export(format="onnx")
```
=== "CLI"
diff --git a/docs/en/usage/callbacks.md b/docs/en/usage/callbacks.md
index 91c8373a..2324977b 100644
--- a/docs/en/usage/callbacks.md
+++ b/docs/en/usage/callbacks.md
@@ -41,13 +41,13 @@ def on_predict_batch_end(predictor):
# Create a YOLO model instance
-model = YOLO(f'yolov8n.pt')
+model = YOLO(f"yolov8n.pt")
# Add the custom callback to the model
model.add_callback("on_predict_batch_end", on_predict_batch_end)
# Iterate through the results and frames
-for (result, frame) in model.predict(): # or model.track()
+for result, frame in model.predict(): # or model.track()
pass
```
diff --git a/docs/en/usage/cfg.md b/docs/en/usage/cfg.md
index 17d71181..98057758 100644
--- a/docs/en/usage/cfg.md
+++ b/docs/en/usage/cfg.md
@@ -33,7 +33,7 @@ Ultralytics commands use the following syntax:
from ultralytics import YOLO
# Load a YOLOv8 model from a pre-trained weights file
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Run MODE mode using the custom arguments ARGS (guess TASK)
model.MODE(ARGS)
diff --git a/docs/en/usage/python.md b/docs/en/usage/python.md
index 755c8e43..f8624661 100644
--- a/docs/en/usage/python.md
+++ b/docs/en/usage/python.md
@@ -27,22 +27,22 @@ For example, users can load a model, train it, evaluate its performance on a val
from ultralytics import YOLO
# Create a new YOLO model from scratch
- model = YOLO('yolov8n.yaml')
+ model = YOLO("yolov8n.yaml")
# Load a pretrained YOLO model (recommended for training)
- model = YOLO('yolov8n.pt')
+ model = YOLO("yolov8n.pt")
# Train the model using the 'coco8.yaml' dataset for 3 epochs
- results = model.train(data='coco8.yaml', epochs=3)
+ results = model.train(data="coco8.yaml", epochs=3)
# Evaluate the model's performance on the validation set
results = model.val()
# Perform object detection on an image using the model
- results = model('https://ultralytics.com/images/bus.jpg')
+ results = model("https://ultralytics.com/images/bus.jpg")
# Export the model to ONNX format
- success = model.export(format='onnx')
+ success = model.export(format="onnx")
```
## [Train](../modes/train.md)
@@ -56,7 +56,7 @@ Train mode is used for training a YOLOv8 model on a custom dataset. In this mode
```python
from ultralytics import YOLO
- model = YOLO('yolov8n.pt') # pass any model type
+ model = YOLO("yolov8n.pt") # pass any model type
results = model.train(epochs=5)
```
@@ -65,8 +65,8 @@ Train mode is used for training a YOLOv8 model on a custom dataset. In this mode
```python
from ultralytics import YOLO
- model = YOLO('yolov8n.yaml')
- results = model.train(data='coco8.yaml', epochs=5)
+ model = YOLO("yolov8n.yaml")
+ results = model.train(data="coco8.yaml", epochs=5)
```
=== "Resume"
@@ -117,14 +117,14 @@ Predict mode is used for making predictions using a trained YOLOv8 model on new
=== "From source"
```python
- from ultralytics import YOLO
- from PIL import Image
import cv2
+ from PIL import Image
+ from ultralytics import YOLO
model = YOLO("model.pt")
# accepts all formats - image/dir/Path/URL/video/PIL/ndarray. 0 for webcam
results = model.predict(source="0")
- results = model.predict(source="folder", show=True) # Display preds. Accepts all YOLO predict arguments
+ results = model.predict(source="folder", show=True) # Display preds. Accepts all YOLO predict arguments
# from PIL
im1 = Image.open("bus.jpg")
@@ -153,20 +153,20 @@ Predict mode is used for making predictions using a trained YOLOv8 model on new
for result in results:
# Detection
- result.boxes.xyxy # box with xyxy format, (N, 4)
- result.boxes.xywh # box with xywh format, (N, 4)
+ result.boxes.xyxy # box with xyxy format, (N, 4)
+ result.boxes.xywh # box with xywh format, (N, 4)
result.boxes.xyxyn # box with xyxy format but normalized, (N, 4)
result.boxes.xywhn # box with xywh format but normalized, (N, 4)
- result.boxes.conf # confidence score, (N, 1)
- result.boxes.cls # cls, (N, 1)
+ result.boxes.conf # confidence score, (N, 1)
+ result.boxes.cls # cls, (N, 1)
# Segmentation
- result.masks.data # masks, (N, H, W)
- result.masks.xy # x,y segments (pixels), List[segment] * N
- result.masks.xyn # x,y segments (normalized), List[segment] * N
+ result.masks.data # masks, (N, H, W)
+ result.masks.xy # x,y segments (pixels), List[segment] * N
+ result.masks.xyn # x,y segments (normalized), List[segment] * N
# Classification
- result.probs # cls prob, (num_class, )
+ result.probs # cls prob, (num_class, )
# Each result is composed of torch.Tensor by default,
# in which you can easily use following functionality:
@@ -218,9 +218,9 @@ Track mode is used for tracking objects in real-time using a YOLOv8 model. In th
from ultralytics import YOLO
# Load a model
- model = YOLO('yolov8n.pt') # load an official detection model
- model = YOLO('yolov8n-seg.pt') # load an official segmentation model
- model = YOLO('path/to/best.pt') # load a custom model
+ model = YOLO("yolov8n.pt") # load an official detection model
+ model = YOLO("yolov8n-seg.pt") # load an official segmentation model
+ model = YOLO("path/to/best.pt") # load a custom model
# Track with the model
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True)
@@ -242,7 +242,7 @@ Benchmark mode is used to profile the speed and accuracy of various export forma
from ultralytics.utils.benchmarks import benchmark
# Benchmark
- benchmark(model='yolov8n.pt', data='coco8.yaml', imgsz=640, half=False, device=0)
+ benchmark(model="yolov8n.pt", data="coco8.yaml", imgsz=640, half=False, device=0)
```
[Benchmark Examples](../modes/benchmark.md){ .md-button }
@@ -259,18 +259,16 @@ Explorer API can be used to explore datasets with advanced semantic, vector-simi
from ultralytics import Explorer
# create an Explorer object
- exp = Explorer(data='coco8.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco8.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
- similar = exp.get_similar(img='https://ultralytics.com/images/bus.jpg', limit=10)
+ similar = exp.get_similar(img="https://ultralytics.com/images/bus.jpg", limit=10)
print(similar.head())
# Search using multiple indices
similar = exp.get_similar(
- img=['https://ultralytics.com/images/bus.jpg',
- 'https://ultralytics.com/images/bus.jpg'],
- limit=10
- )
+ img=["https://ultralytics.com/images/bus.jpg", "https://ultralytics.com/images/bus.jpg"], limit=10
+ )
print(similar.head())
```
@@ -280,14 +278,14 @@ Explorer API can be used to explore datasets with advanced semantic, vector-simi
from ultralytics import Explorer
# create an Explorer object
- exp = Explorer(data='coco8.yaml', model='yolov8n.pt')
+ exp = Explorer(data="coco8.yaml", model="yolov8n.pt")
exp.create_embeddings_table()
similar = exp.get_similar(idx=1, limit=10)
print(similar.head())
# Search using multiple indices
- similar = exp.get_similar(idx=[1,10], limit=10)
+ similar = exp.get_similar(idx=[1, 10], limit=10)
print(similar.head())
```
@@ -300,7 +298,7 @@ Explorer API can be used to explore datasets with advanced semantic, vector-simi
!!! Tip "Detection Trainer Example"
```python
- from ultralytics.models.yolo import DetectionTrainer, DetectionValidator, DetectionPredictor
+ from ultralytics.models.yolo import DetectionPredictor, DetectionTrainer, DetectionValidator
# trainer
trainer = DetectionTrainer(overrides={})
diff --git a/docs/en/usage/simple-utilities.md b/docs/en/usage/simple-utilities.md
index dfd33617..704b5435 100644
--- a/docs/en/usage/simple-utilities.md
+++ b/docs/en/usage/simple-utilities.md
@@ -195,15 +195,15 @@ from ultralytics.data.utils import polygon2mask
imgsz = (1080, 810)
polygon = np.array(
- [805, 392, 797, 400, ..., 808, 714, 808, 392], # (238, 2)
+ [805, 392, 797, 400, ..., 808, 714, 808, 392], # (238, 2)
)
mask = polygon2mask(
- imgsz, # tuple
- [polygon], # input as list
- color=255, # 8-bit binary
- downsample_ratio=1
-)
+ imgsz, # tuple
+ [polygon], # input as list
+ color=255, # 8-bit binary
+ downsample_ratio=1,
+)
```
## Bounding Boxes
@@ -326,13 +326,15 @@ xywh
### All Bounding Box Conversions
```python
-from ultralytics.utils.ops import xywh2xyxy
-from ultralytics.utils.ops import xywhn2xyxy # normalized → pixel
-from ultralytics.utils.ops import xyxy2xywhn # pixel → normalized
-from ultralytics.utils.ops import xywh2ltwh # xywh → top-left corner, w, h
-from ultralytics.utils.ops import xyxy2ltwh # xyxy → top-left corner, w, h
-from ultralytics.utils.ops import ltwh2xywh
-from ultralytics.utils.ops import ltwh2xyxy
+from ultralytics.utils.ops import (
+ ltwh2xywh,
+ ltwh2xyxy,
+ xywh2ltwh, # xywh → top-left corner, w, h
+ xywh2xyxy,
+ xywhn2xyxy, # normalized → pixel
+ xyxy2ltwh, # xyxy → top-left corner, w, h
+ xyxy2xywhn, # pixel → normalized
+)
```
See docstring for each function or visit the `ultralytics.utils.ops` [reference page](../reference/utils/ops.md) to read more about each function.
@@ -394,17 +396,18 @@ from ultralytics.utils.plotting import Annotator, colors
obb_names = {10: "small vehicle"}
obb_image = cv.imread("datasets/dota8/images/train/P1142__1024__0___824.jpg")
obb_boxes = np.array(
- [[ 0, 635, 560, 919, 719, 1087, 420, 803, 261,], # class-idx x1 y1 x2 y2 x3 y2 x4 y4
- [ 0, 331, 19, 493, 260, 776, 70, 613, -171,],
- [ 9, 869, 161, 886, 147, 851, 101, 833, 115,]
+ [
+ [0, 635, 560, 919, 719, 1087, 420, 803, 261], # class-idx x1 y1 x2 y2 x3 y2 x4 y4
+ [0, 331, 19, 493, 260, 776, 70, 613, -171],
+ [9, 869, 161, 886, 147, 851, 101, 833, 115],
]
)
ann = Annotator(
obb_image,
line_width=None, # default auto-size
- font_size=None, # default auto-size
- font="Arial.ttf", # must be ImageFont compatible
- pil=False, # use PIL, otherwise uses OpenCV
+ font_size=None, # default auto-size
+ font="Arial.ttf", # must be ImageFont compatible
+ pil=False, # use PIL, otherwise uses OpenCV
)
for obb in obb_boxes:
c_idx, *obb = obb
diff --git a/docs/en/yolov5/tutorials/architecture_description.md b/docs/en/yolov5/tutorials/architecture_description.md
index c2cc9d28..a38cfbf4 100644
--- a/docs/en/yolov5/tutorials/architecture_description.md
+++ b/docs/en/yolov5/tutorials/architecture_description.md
@@ -32,6 +32,7 @@ To test the speed of `SPP` and `SPPF`, the following code can be used:
```python
import time
+
import torch
import torch.nn as nn
@@ -87,7 +88,7 @@ def main():
print(f"SPPF time: {time.time() - t_start}")
-if __name__ == '__main__':
+if __name__ == "__main__":
main()
```
diff --git a/docs/en/yolov5/tutorials/model_export.md b/docs/en/yolov5/tutorials/model_export.md
index abc5730d..ed29ce43 100644
--- a/docs/en/yolov5/tutorials/model_export.md
+++ b/docs/en/yolov5/tutorials/model_export.md
@@ -181,20 +181,20 @@ Use PyTorch Hub with exported YOLOv5 models:
import torch
# Model
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt')
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.torchscript ') # TorchScript
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx') # ONNX Runtime
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s_openvino_model') # OpenVINO
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.engine') # TensorRT
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.mlmodel') # CoreML (macOS Only)
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s_saved_model') # TensorFlow SavedModel
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pb') # TensorFlow GraphDef
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.tflite') # TensorFlow Lite
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s_edgetpu.tflite') # TensorFlow Edge TPU
-model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s_paddle_model') # PaddlePaddle
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s.pt")
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s.torchscript ") # TorchScript
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s.onnx") # ONNX Runtime
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s_openvino_model") # OpenVINO
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s.engine") # TensorRT
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s.mlmodel") # CoreML (macOS Only)
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s_saved_model") # TensorFlow SavedModel
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s.pb") # TensorFlow GraphDef
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s.tflite") # TensorFlow Lite
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s_edgetpu.tflite") # TensorFlow Edge TPU
+model = torch.hub.load("ultralytics/yolov5", "custom", "yolov5s_paddle_model") # PaddlePaddle
# Images
-img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
+img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
diff --git a/docs/en/yolov5/tutorials/neural_magic_pruning_quantization.md b/docs/en/yolov5/tutorials/neural_magic_pruning_quantization.md
index 37c89c14..46317380 100644
--- a/docs/en/yolov5/tutorials/neural_magic_pruning_quantization.md
+++ b/docs/en/yolov5/tutorials/neural_magic_pruning_quantization.md
@@ -135,14 +135,16 @@ deepsparse.server \
An example request, using Python's `requests` package:
```python
-import requests, json
+import json
+
+import requests
# list of images for inference (local files on client side)
-path = ['basilica.jpg']
-files = [('request', open(img, 'rb')) for img in path]
+path = ["basilica.jpg"]
+files = [("request", open(img, "rb")) for img in path]
# send request over HTTP to /predict/from_files endpoint
-url = 'http://0.0.0.0:5543/predict/from_files'
+url = "http://0.0.0.0:5543/predict/from_files"
resp = requests.post(url=url, files=files)
# response is returned in JSON
diff --git a/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md b/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
index be4baaf2..bf11397a 100644
--- a/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
+++ b/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
@@ -26,10 +26,10 @@ This example loads a pretrained YOLOv5s model from PyTorch Hub as `model` and pa
import torch
# Model
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+model = torch.hub.load("ultralytics/yolov5", "yolov5s")
# Image
-im = 'https://ultralytics.com/images/zidane.jpg'
+im = "https://ultralytics.com/images/zidane.jpg"
# Inference
results = model(im)
@@ -52,13 +52,13 @@ import torch
from PIL import Image
# Model
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+model = torch.hub.load("ultralytics/yolov5", "yolov5s")
# Images
-for f in 'zidane.jpg', 'bus.jpg':
- torch.hub.download_url_to_file('https://ultralytics.com/images/' + f, f) # download 2 images
-im1 = Image.open('zidane.jpg') # PIL image
-im2 = cv2.imread('bus.jpg')[..., ::-1] # OpenCV image (BGR to RGB)
+for f in "zidane.jpg", "bus.jpg":
+ torch.hub.download_url_to_file("https://ultralytics.com/images/" + f, f) # download 2 images
+im1 = Image.open("zidane.jpg") # PIL image
+im2 = cv2.imread("bus.jpg")[..., ::-1] # OpenCV image (BGR to RGB)
# Inference
results = model([im1, im2], size=640) # batch of images
@@ -110,7 +110,7 @@ model.to(device) # i.e. device=torch.device(0)
Models can also be created directly on any `device`:
```python
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU
+model = torch.hub.load("ultralytics/yolov5", "yolov5s", device="cpu") # load on CPU
```
💡 ProTip: Input images are automatically transferred to the correct model device before inference.
@@ -120,7 +120,7 @@ model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on
Models can be loaded silently with `_verbose=False`:
```python
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently
+model = torch.hub.load("ultralytics/yolov5", "yolov5s", _verbose=False) # load silently
```
### Input Channels
@@ -128,7 +128,7 @@ model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load
To load a pretrained YOLOv5s model with 4 input channels rather than the default 3:
```python
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
+model = torch.hub.load("ultralytics/yolov5", "yolov5s", channels=4)
```
In this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.
@@ -138,7 +138,7 @@ In this case the model will be composed of pretrained weights **except for** the
To load a pretrained YOLOv5s model with 10 output classes rather than the default 80:
```python
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
+model = torch.hub.load("ultralytics/yolov5", "yolov5s", classes=10)
```
In this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.
@@ -148,7 +148,7 @@ In this case the model will be composed of pretrained weights **except for** the
If you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.
```python
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload
+model = torch.hub.load("ultralytics/yolov5", "yolov5s", force_reload=True) # force reload
```
### Screenshot Inference
@@ -160,7 +160,7 @@ import torch
from PIL import ImageGrab
# Model
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+model = torch.hub.load("ultralytics/yolov5", "yolov5s")
# Image
im = ImageGrab.grab() # take a screenshot
@@ -174,9 +174,10 @@ results = model(im)
YOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:
```python
-import torch
import threading
+import torch
+
def run(model, im):
"""Performs inference on an image using a given model and saves the output; model must support `.save()` method."""
@@ -185,12 +186,12 @@ def run(model, im):
# Models
-model0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)
-model1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)
+model0 = torch.hub.load("ultralytics/yolov5", "yolov5s", device=0)
+model1 = torch.hub.load("ultralytics/yolov5", "yolov5s", device=1)
# Inference
-threading.Thread(target=run, args=[model0, 'https://ultralytics.com/images/zidane.jpg'], daemon=True).start()
-threading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.jpg'], daemon=True).start()
+threading.Thread(target=run, args=[model0, "https://ultralytics.com/images/zidane.jpg"], daemon=True).start()
+threading.Thread(target=run, args=[model1, "https://ultralytics.com/images/bus.jpg"], daemon=True).start()
```
### Training
@@ -200,8 +201,8 @@ To load a YOLOv5 model for training rather than inference, set `autoshape=False`
```python
import torch
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
+model = torch.hub.load("ultralytics/yolov5", "yolov5s", autoshape=False) # load pretrained
+model = torch.hub.load("ultralytics/yolov5", "yolov5s", autoshape=False, pretrained=False) # load scratch
```
### Base64 Results
@@ -217,7 +218,7 @@ for im in results.ims:
buffered = BytesIO()
im_base64 = Image.fromarray(im)
im_base64.save(buffered, format="JPEG")
- print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results
+ print(base64.b64encode(buffered.getvalue()).decode("utf-8")) # base64 encoded image with results
```
### Cropped Results
@@ -258,7 +259,7 @@ Results can be sorted by column, i.e. to sort license plate digit detection left
```python
results = model(im) # inference
-results.pandas().xyxy[0].sort_values('xmin') # sorted left-right
+results.pandas().xyxy[0].sort_values("xmin") # sorted left-right
```
### Box-Cropped Results
@@ -332,8 +333,8 @@ This example loads a custom 20-class [VOC](https://github.com/ultralytics/yolov5
```python
import torch
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt') # local model
-model = torch.hub.load('path/to/yolov5', 'custom', path='path/to/best.pt', source='local') # local repo
+model = torch.hub.load("ultralytics/yolov5", "custom", path="path/to/best.pt") # local model
+model = torch.hub.load("path/to/yolov5", "custom", path="path/to/best.pt", source="local") # local repo
```
## TensorRT, ONNX and OpenVINO Models
@@ -346,14 +347,14 @@ PyTorch Hub supports inference on most YOLOv5 export formats, including custom t
```python
import torch
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.pt') # PyTorch
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.torchscript') # TorchScript
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.onnx') # ONNX
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s_openvino_model/') # OpenVINO
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.engine') # TensorRT
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.mlmodel') # CoreML (macOS-only)
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.tflite') # TFLite
-model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s_paddle_model/') # PaddlePaddle
+model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.pt") # PyTorch
+model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.torchscript") # TorchScript
+model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.onnx") # ONNX
+model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s_openvino_model/") # OpenVINO
+model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.engine") # TensorRT
+model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.mlmodel") # CoreML (macOS-only)
+model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s.tflite") # TFLite
+model = torch.hub.load("ultralytics/yolov5", "custom", path="yolov5s_paddle_model/") # PaddlePaddle
```
## Supported Environments
diff --git a/docs/en/yolov5/tutorials/test_time_augmentation.md b/docs/en/yolov5/tutorials/test_time_augmentation.md
index 6a585efc..b7d33461 100644
--- a/docs/en/yolov5/tutorials/test_time_augmentation.md
+++ b/docs/en/yolov5/tutorials/test_time_augmentation.md
@@ -131,10 +131,10 @@ TTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.or
import torch
# Model
-model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom
+model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5m, yolov5x, custom
# Images
-img = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple
+img = "https://ultralytics.com/images/zidane.jpg" # or file, PIL, OpenCV, numpy, multiple
# Inference
results = model(img, augment=True) # <--- TTA inference
diff --git a/docs/en/yolov5/tutorials/train_custom_data.md b/docs/en/yolov5/tutorials/train_custom_data.md
index 62998254..1afdc311 100644
--- a/docs/en/yolov5/tutorials/train_custom_data.md
+++ b/docs/en/yolov5/tutorials/train_custom_data.md
@@ -192,7 +192,7 @@ Results file `results.csv` is updated after each epoch, and then plotted as `res
```python
from utils.plots import plot_results
-plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
+plot_results("path/to/results.csv") # plot 'results.csv' as 'results.png'
```

diff --git a/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md b/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
index 8fb0da81..b7100e82 100644
--- a/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
+++ b/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
@@ -22,11 +22,11 @@ All layers that match the train.py `freeze` list in train.py will be frozen by s
```python
# Freeze
-freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
+freeze = [f"model.{x}." for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
- print(f'freezing {k}')
+ print(f"freezing {k}")
v.requires_grad = False
```
diff --git a/examples/YOLOv8-ONNXRuntime-CPP/README.md b/examples/YOLOv8-ONNXRuntime-CPP/README.md
index 1cb6eb3d..331ca56b 100644
--- a/examples/YOLOv8-ONNXRuntime-CPP/README.md
+++ b/examples/YOLOv8-ONNXRuntime-CPP/README.md
@@ -40,9 +40,9 @@ yolo export model=yolov8n.pt opset=12 simplify=True dynamic=False format=onnx im
import onnx
from onnxconverter_common import float16
-model = onnx.load(R'YOUR_ONNX_PATH')
+model = onnx.load(R"YOUR_ONNX_PATH")
model_fp16 = float16.convert_float_to_float16(model)
-onnx.save(model_fp16, R'YOUR_FP16_ONNX_PATH')
+onnx.save(model_fp16, R"YOUR_FP16_ONNX_PATH")
```
## Download COCO.yaml file 📂
diff --git a/examples/YOLOv8-Region-Counter/readme.md b/examples/YOLOv8-Region-Counter/readme.md
index 4ab8e7fc..a0811359 100644
--- a/examples/YOLOv8-Region-Counter/readme.md
+++ b/examples/YOLOv8-Region-Counter/readme.md
@@ -91,9 +91,7 @@ counting_regions = [
},
{
"name": "YOLOv8 Rectangle Region",
- "polygon": Polygon(
- [(200, 250), (440, 250), (440, 550), (200, 550)]
- ), # Rectangle with four points
+ "polygon": Polygon([(200, 250), (440, 250), (440, 550), (200, 550)]), # Rectangle with four points
"counts": 0,
"dragging": False,
"region_color": (37, 255, 225), # BGR Value
diff --git a/ultralytics/trackers/README.md b/ultralytics/trackers/README.md
index 7833a19b..3d5b60f5 100644
--- a/ultralytics/trackers/README.md
+++ b/ultralytics/trackers/README.md
@@ -48,9 +48,7 @@ model = YOLO("yolov8n-pose.pt") # Load an official Pose model
model = YOLO("path/to/best.pt") # Load a custom trained model
# Perform tracking with the model
-results = model.track(
- source="https://youtu.be/LNwODJXcvt4", show=True
-) # Tracking with default tracker
+results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True) # Tracking with default tracker
results = model.track(
source="https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml"
) # Tracking with ByteTrack tracker
@@ -84,9 +82,7 @@ from ultralytics import YOLO
# Configure the tracking parameters and run the tracker
model = YOLO("yolov8n.pt")
-results = model.track(
- source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True
-)
+results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
```
#### CLI
@@ -107,9 +103,7 @@ from ultralytics import YOLO
# Load the model and run the tracker with a custom configuration file
model = YOLO("yolov8n.pt")
-results = model.track(
- source="https://youtu.be/LNwODJXcvt4", tracker="custom_tracker.yaml"
-)
+results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker="custom_tracker.yaml")
```
#### CLI
@@ -182,7 +176,6 @@ from collections import defaultdict
import cv2
import numpy as np
-
from ultralytics import YOLO
# Load the YOLOv8 model
@@ -290,12 +283,8 @@ video_file1 = "path/to/video1.mp4"
video_file2 = "path/to/video2.mp4"
# Create the tracker threads
-tracker_thread1 = threading.Thread(
- target=run_tracker_in_thread, args=(video_file1, model1), daemon=True
-)
-tracker_thread2 = threading.Thread(
- target=run_tracker_in_thread, args=(video_file2, model2), daemon=True
-)
+tracker_thread1 = threading.Thread(target=run_tracker_in_thread, args=(video_file1, model1), daemon=True)
+tracker_thread2 = threading.Thread(target=run_tracker_in_thread, args=(video_file2, model2), daemon=True)
# Start the tracker threads
tracker_thread1.start()