Add Chinese Modes and Tasks Docs (#6274)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
This commit is contained in:
parent
795b95bdcb
commit
e3a538bbde
293 changed files with 3681 additions and 736 deletions
|
|
@ -11,6 +11,21 @@ keywords: Ultralytics, YOLOv8, 目标检测, 图像分割, 机器学习, 深度
|
|||
<a href="https://yolovision.ultralytics.com" target="_blank">
|
||||
<img width="1024" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov8/banner-yolov8.png" alt="Ultralytics YOLO banner"></a>
|
||||
</p>
|
||||
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
||||
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
||||
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
||||
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
||||
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
||||
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
||||
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
||||
<br>
|
||||
<br>
|
||||
<a href="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml"><img src="https://github.com/ultralytics/ultralytics/actions/workflows/ci.yaml/badge.svg" alt="Ultralytics CI"></a>
|
||||
<a href="https://codecov.io/github/ultralytics/ultralytics"><img src="https://codecov.io/github/ultralytics/ultralytics/branch/main/graph/badge.svg?token=HHW7IIVFVY" alt="Ultralytics Code Coverage"></a>
|
||||
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv8 Citation"></a>
|
||||
|
|
@ -27,10 +42,10 @@ keywords: Ultralytics, YOLOv8, 目标检测, 图像分割, 机器学习, 深度
|
|||
|
||||
## 从哪里开始
|
||||
|
||||
- **安装** `ultralytics` 并通过 pip 在几分钟内开始运行 [:material-clock-fast: 开始使用](https://docs.ultralytics.com/quickstart/){ .md-button }
|
||||
- **预测** 使用YOLOv8预测新的图像和视频 [:octicons-image-16: 在图像上预测](https://docs.ultralytics.com/predict/){ .md-button }
|
||||
- **训练** 在您自己的自定义数据集上训练新的YOLOv8模型 [:fontawesome-solid-brain: 训练模型](https://docs.ultralytics.com/modes/train/){ .md-button }
|
||||
- **探索** YOLOv8的任务,如分割、分类、姿态和跟踪 [:material-magnify-expand: 探索任务](https://docs.ultralytics.com/tasks/){ .md-button }
|
||||
- **安装** `ultralytics` 并通过 pip 在几分钟内开始运行 [:material-clock-fast: 开始使用](quickstart.md){ .md-button }
|
||||
- **预测** 使用YOLOv8预测新的图像和视频 [:octicons-image-16: 在图像上预测](modes/predict.md){ .md-button }
|
||||
- **训练** 在您自己的自定义数据集上训练新的YOLOv8模型 [:fontawesome-solid-brain: 训练模型](modes/train.md){ .md-button }
|
||||
- **探索** YOLOv8的任务,如分割、分类、姿态和跟踪 [:material-magnify-expand: 探索任务](tasks/index.md){ .md-button }
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
|
|
@ -66,4 +81,4 @@ Ultralytics提供两种许可选项以适应不同的使用场景:
|
|||
|
||||
---
|
||||
|
||||
**注意**:我们正在努力为我们的文档页面提供中文文档,并希望在接下来的几个月内发布。请密切关注我们的更新,并感谢您的耐心等待。
|
||||
**注意**:我们正在努力为我们的文档页面提供中文文档,并希望在接下来的几个月内发布。请密切关注我们的更新,并感谢您的耐心等待🙏。
|
||||
|
|
|
|||
94
docs/zh/modes/benchmark.md
Normal file
94
docs/zh/modes/benchmark.md
Normal file
|
|
@ -0,0 +1,94 @@
|
|||
---
|
||||
comments: 真
|
||||
description: 了解如何评估YOLOv8在各种导出格式下的速度和准确性,获取mAP50-95、accuracy_top5等指标的洞察。
|
||||
keywords: Ultralytics, YOLOv8, 基准测试, 速度分析, 准确性分析, mAP50-95, accuracy_top5, ONNX, OpenVINO, TensorRT, YOLO导出格式
|
||||
---
|
||||
|
||||
# 使用Ultralytics YOLO进行模型基准测试
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO生态系统和集成">
|
||||
|
||||
## 介绍
|
||||
|
||||
一旦您的模型经过训练和验证,下一个合乎逻辑的步骤是评估它在各种实际场景中的性能。Ultralytics YOLOv8的基准模式通过提供一个健壮的框架来评估模型在一系列导出格式中的速度和准确性,为此目的服务。
|
||||
|
||||
## 为什么基准测试至关重要?
|
||||
|
||||
- **明智的决策:** 洞察速度和准确性之间的权衡。
|
||||
- **资源分配:** 理解不同的导出格式在不同硬件上的性能表现。
|
||||
- **优化:** 了解哪种导出格式为您的特定用例提供最佳性能。
|
||||
- **成本效益:** 根据基准测试结果,更有效地利用硬件资源。
|
||||
|
||||
### 基准模式的关键指标
|
||||
|
||||
- **mAP50-95:** 用于物体检测、分割和姿态估计。
|
||||
- **accuracy_top5:** 用于图像分类。
|
||||
- **推断时间:** 处理每张图片的时间(毫秒)。
|
||||
|
||||
### 支持的导出格式
|
||||
|
||||
- **ONNX:** 为了最佳的CPU性能
|
||||
- **TensorRT:** 为了最大化的GPU效率
|
||||
- **OpenVINO:** 针对Intel硬件的优化
|
||||
- **CoreML、TensorFlow SavedModel 等:** 满足多样化部署需求。
|
||||
|
||||
!!! 技巧 "提示"
|
||||
|
||||
* 导出到ONNX或OpenVINO可实现高达3倍CPU速度提升。
|
||||
* 导出到TensorRT可实现高达5倍GPU速度提升。
|
||||
|
||||
## 使用示例
|
||||
|
||||
在所有支持的导出格式上运行YOLOv8n基准测试,包括ONNX、TensorRT等。更多导出参数的完整列表请见下方的参数部分。
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics.utils.benchmarks import benchmark
|
||||
|
||||
# 在GPU上进行基准测试
|
||||
benchmark(model='yolov8n.pt', data='coco8.yaml', imgsz=640, half=False, device=0)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
|
||||
```
|
||||
|
||||
## 参数
|
||||
|
||||
参数如 `model`、`data`、`imgsz`、`half`、`device` 和 `verbose` 等,为用户提供了灵活性,以便根据具体需求微调基准测试,并轻松比较不同导出格式的性能。
|
||||
|
||||
| 键 | 值 | 描述 |
|
||||
|-----------|---------|----------------------------------------------------|
|
||||
| `model` | `None` | 模型文件路径,如 yolov8n.pt, yolov8n.yaml |
|
||||
| `data` | `None` | 引用基准测试数据集的YAML路径(标记为 `val`) |
|
||||
| `imgsz` | `640` | 图像大小作为标量或(h, w)列表,如 (640, 480) |
|
||||
| `half` | `False` | FP16量化 |
|
||||
| `int8` | `False` | INT8量化 |
|
||||
| `device` | `None` | 运行设备,如 cuda device=0 或 device=0,1,2,3 或 device=cpu |
|
||||
| `verbose` | `False` | 错误时不继续(布尔值),或验证阈值下限(浮点数) |
|
||||
|
||||
## 导出格式
|
||||
|
||||
基准测试将尝试在下方列出的所有可能的导出格式上自动运行。
|
||||
|
||||
| 格式 | `format` 参数 | 模型 | 元数据 | 参数 |
|
||||
|--------------------------------------------------------------------|---------------|---------------------------|-----|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
在[导出](https://docs.ultralytics.com/modes/export/)页面查看完整的 `export` 详情。
|
||||
108
docs/zh/modes/export.md
Normal file
108
docs/zh/modes/export.md
Normal file
|
|
@ -0,0 +1,108 @@
|
|||
---
|
||||
comments: true
|
||||
description: 如何逐步指导您将 YOLOv8 模型导出到各种格式,如 ONNX、TensorRT、CoreML 等以进行部署。现在就探索!
|
||||
keywords: YOLO, YOLOv8, Ultralytics, 模型导出, ONNX, TensorRT, CoreML, TensorFlow SavedModel, OpenVINO, PyTorch, 导出模型
|
||||
---
|
||||
|
||||
# Ultralytics YOLO 的模型导出
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO 生态系统和集成">
|
||||
|
||||
## 引言
|
||||
|
||||
训练模型的最终目标是将其部署到现实世界的应用中。Ultralytics YOLOv8 的导出模式提供了多种选项,用于将您训练好的模型导出到不同的格式,从而可以在各种平台和设备上部署。本综合指南旨在带您逐步了解模型导出的细节,展示如何实现最大的兼容性和性能。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/WbomGeoOT_k?si=aGmuyooWftA0ue9X"
|
||||
title="YouTube 视频播放器" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong>如何导出自定义训练的 Ultralytics YOLOv8 模型并在网络摄像头上实时推理。
|
||||
</p>
|
||||
|
||||
## 为什么选择 YOLOv8 的导出模式?
|
||||
|
||||
- **多功能性:** 支持导出到多种格式,包括 ONNX、TensorRT、CoreML 等。
|
||||
- **性能:** 使用 TensorRT 可实现高达 5 倍 GPU 加速,使用 ONNX 或 OpenVINO 可实现高达 3 倍 CPU 加速。
|
||||
- **兼容性:** 使您的模型可以在众多硬件和软件环境中广泛部署。
|
||||
- **易用性:** 简单的 CLI 和 Python API,快速直接地进行模型导出。
|
||||
|
||||
### 导出模式的关键特性
|
||||
|
||||
以下是一些突出的功能:
|
||||
|
||||
- **一键导出:** 用于导出到不同格式的简单命令。
|
||||
- **批量导出:** 支持批推理能力的模型导出。
|
||||
- **优化推理:** 导出的模型针对更快的推理时间进行优化。
|
||||
- **教学视频:** 提供深入指导和教学,确保流畅的导出体验。
|
||||
|
||||
!!! 提示 "提示"
|
||||
|
||||
* 导出到 ONNX 或 OpenVINO,以实现高达 3 倍的 CPU 加速。
|
||||
* 导出到 TensorRT,以实现高达 5 倍的 GPU 加速。
|
||||
|
||||
## 使用示例
|
||||
|
||||
将 YOLOv8n 模型导出为 ONNX 或 TensorRT 等不同格式。查看下面的参数部分,了解完整的导出参数列表。
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义训练的模型
|
||||
|
||||
# 导出模型
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n.pt format=onnx # 导出官方模型
|
||||
yolo export model=path/to/best.pt format=onnx # 导出自定义训练的模型
|
||||
```
|
||||
|
||||
## 参数
|
||||
|
||||
YOLO 模型的导出设置是指用于在其他环境或平台中使用模型时保存或导出模型的各种配置和选项。这些设置会影响模型的性能、大小和与不同系统的兼容性。一些常见的 YOLO 导出设置包括导出的模型文件格式(例如 ONNX、TensorFlow SavedModel)、模型将在哪个设备上运行(例如 CPU、GPU)以及是否包含附加功能,如遮罩或每个框多个标签。其他可能影响导出过程的因素包括模型用途的具体细节以及目标环境或平台的要求或限制。重要的是要仔细考虑和配置这些设置,以确保导出的模型针对预期用例经过优化,并且可以在目标环境中有效使用。
|
||||
|
||||
| 键 | 值 | 描述 |
|
||||
|-------------|-----------------|-------------------------------------|
|
||||
| `format` | `'torchscript'` | 导出的格式 |
|
||||
| `imgsz` | `640` | 图像尺寸,可以是标量或 (h, w) 列表,比如 (640, 480) |
|
||||
| `keras` | `False` | 使用 Keras 导出 TF SavedModel |
|
||||
| `optimize` | `False` | TorchScript:为移动设备优化 |
|
||||
| `half` | `False` | FP16 量化 |
|
||||
| `int8` | `False` | INT8 量化 |
|
||||
| `dynamic` | `False` | ONNX/TensorRT:动态轴 |
|
||||
| `simplify` | `False` | ONNX/TensorRT:简化模型 |
|
||||
| `opset` | `None` | ONNX:opset 版本(可选,默认为最新版本) |
|
||||
| `workspace` | `4` | TensorRT:工作区大小(GB) |
|
||||
| `nms` | `False` | CoreML:添加 NMS |
|
||||
|
||||
## 导出格式
|
||||
|
||||
下表中提供了可用的 YOLOv8 导出格式。您可以使用 `format` 参数导出任何格式的模型,比如 `format='onnx'` 或 `format='engine'`。
|
||||
|
||||
| 格式 | `format` 参数 | 模型 | 元数据 | 参数 |
|
||||
|--------------------------------------------------------------------|---------------|---------------------------|-----|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
73
docs/zh/modes/index.md
Normal file
73
docs/zh/modes/index.md
Normal file
|
|
@ -0,0 +1,73 @@
|
|||
---
|
||||
comments: true
|
||||
description: 从训练到跟踪,充分利用Ultralytics的YOLOv8。获取支持的每种模式的见解和示例,包括验证、导出和基准测试。
|
||||
keywords: Ultralytics, YOLOv8, 机器学习, 目标检测, 训练, 验证, 预测, 导出, 跟踪, 基准测试
|
||||
---
|
||||
|
||||
# Ultralytics YOLOv8 模式
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO生态系统及整合">
|
||||
|
||||
## 简介
|
||||
|
||||
Ultralytics YOLOv8不仅仅是另一个目标检测模型;它是一个多功能框架,旨在涵盖机器学习模型的整个生命周期——从数据摄取和模型训练到验证、部署和实际跟踪。每种模式都服务于一个特定的目的,并设计为提供您在不同任务和用例中所需的灵活性和效率。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/j8uQc0qB91s?si=dhnGKgqvs7nPgeaM"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong> Ultralytics模式教程:训练、验证、预测、导出和基准测试。
|
||||
</p>
|
||||
|
||||
### 模式概览
|
||||
|
||||
理解Ultralytics YOLOv8所支持的不同**模式**对于充分利用您的模型至关重要:
|
||||
|
||||
- **训练(Train)**模式:在自定义或预加载的数据集上微调您的模型。
|
||||
- **验证(Val)**模式:训练后进行校验,以验证模型性能。
|
||||
- **预测(Predict)**模式:在真实世界数据上释放模型的预测能力。
|
||||
- **导出(Export)**模式:以各种格式使模型准备就绪,部署至生产环境。
|
||||
- **跟踪(Track)**模式:将您的目标检测模型扩展到实时跟踪应用中。
|
||||
- **基准(Benchmark)**模式:在不同部署环境中分析模型的速度和准确性。
|
||||
|
||||
本综合指南旨在为您提供每种模式的概览和实用见解,帮助您充分发挥YOLOv8的全部潜力。
|
||||
|
||||
## [训练](train.md)
|
||||
|
||||
训练模式用于在自定义数据集上训练YOLOv8模型。在此模式下,模型将使用指定的数据集和超参数进行训练。训练过程包括优化模型的参数,使其能够准确预测图像中对象的类别和位置。
|
||||
|
||||
[训练示例](train.md){ .md-button .md-button--primary}
|
||||
|
||||
## [验证](val.md)
|
||||
|
||||
验证模式用于训练YOLOv8模型后进行验证。在此模式下,模型在验证集上进行评估,以衡量其准确性和泛化能力。此模式可以用来调整模型的超参数,以改善其性能。
|
||||
|
||||
[验证示例](val.md){ .md-button .md-button--primary}
|
||||
|
||||
## [预测](predict.md)
|
||||
|
||||
预测模式用于使用训练好的YOLOv8模型在新图像或视频上进行预测。在此模式下,模型从检查点文件加载,用户可以提供图像或视频以执行推理。模型预测输入图像或视频中对象的类别和位置。
|
||||
|
||||
[预测示例](predict.md){ .md-button .md-button--primary}
|
||||
|
||||
## [导出](export.md)
|
||||
|
||||
导出模式用于将YOLOv8模型导出为可用于部署的格式。在此模式下,模型被转换为其他软件应用或硬件设备可以使用的格式。当模型部署到生产环境时,此模式十分有用。
|
||||
|
||||
[导出示例](export.md){ .md-button .md-button--primary}
|
||||
|
||||
## [跟踪](track.md)
|
||||
|
||||
跟踪模式用于使用YOLOv8模型实时跟踪对象。在此模式下,模型从检查点文件加载,用户可以提供实时视频流以执行实时对象跟踪。此模式适用于监控系统或自动驾驶汽车等应用。
|
||||
|
||||
[跟踪示例](track.md){ .md-button .md-button--primary}
|
||||
|
||||
## [基准](benchmark.md)
|
||||
|
||||
基准模式用于对YOLOv8的各种导出格式的速度和准确性进行评估。基准提供了有关导出格式大小、其针对目标检测、分割和姿态的`mAP50-95`指标,或针对分类的`accuracy_top5`指标,以及每张图像跨各种导出格式(如ONNX、OpenVINO、TensorRT等)的推理时间(以毫秒为单位)的信息。此信息可以帮助用户根据对速度和准确性的具体需求,选择最佳的导出格式。
|
||||
|
||||
[基准示例](benchmark.md){ .md-button .md-button--primary}
|
||||
707
docs/zh/modes/predict.md
Normal file
707
docs/zh/modes/predict.md
Normal file
|
|
@ -0,0 +1,707 @@
|
|||
---
|
||||
comments: true
|
||||
description: 了解如何使用 YOLOv8 预测模式进行各种任务。学习关于不同推理源如图像,视频和数据格式的内容。
|
||||
keywords: Ultralytics, YOLOv8, 预测模式, 推理源, 预测任务, 流式模式, 图像处理, 视频处理, 机器学习, 人工智能
|
||||
---
|
||||
|
||||
# 使用 Ultralytics YOLO 进行模型预测
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO 生态系统和集成">
|
||||
|
||||
## 引言
|
||||
|
||||
在机器学习和计算机视觉领域,将视觉数据转化为有用信息的过程被称为'推理'或'预测'。Ultralytics YOLOv8 提供了一个强大的功能,称为 **预测模式**,它专为各种数据来源的高性能实时推理而设计。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/QtsI0TnwDZs?si=ljesw75cMO2Eas14"
|
||||
title="YouTube 视频播放器" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong> 如何从 Ultralytics YOLOv8 模型中提取输出,用于自定义项目。
|
||||
</p>
|
||||
|
||||
## 实际应用领域
|
||||
|
||||
| 制造业 | 体育 | 安全 |
|
||||
|:-------------------------------------------------------------------------------------------------------------:|:-------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------:|
|
||||
| 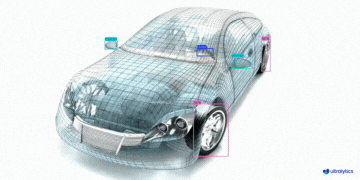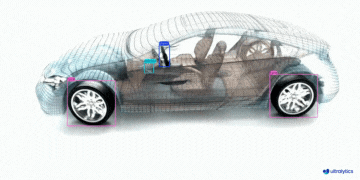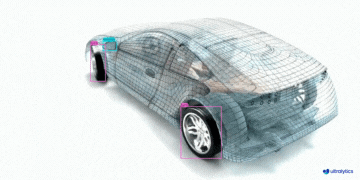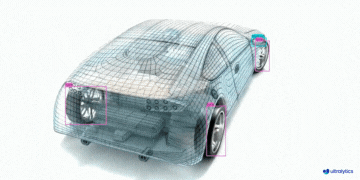 | 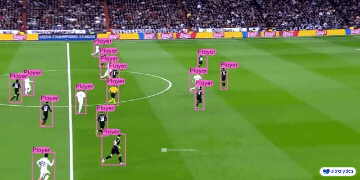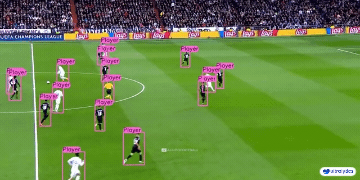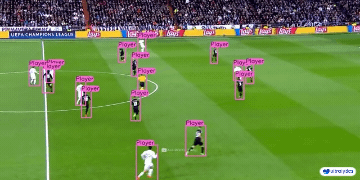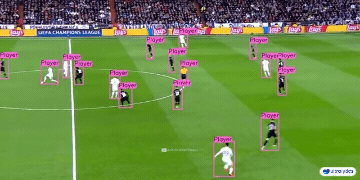 |  |
|
||||
| 车辆零部件检测 | 足球运动员检测 | 人员摔倒检测 |
|
||||
|
||||
## 为何使用 Ultralytics YOLO 进行推理?
|
||||
|
||||
以下是考虑使用 YOLOv8 的预测模式满足您的各种推理需求的几个原因:
|
||||
|
||||
- **多功能性:** 能够对图像、视频乃至实时流进行推理。
|
||||
- **性能:** 工程化为实时、高速处理而设计,不牺牲准确性。
|
||||
- **易用性:** 直观的 Python 和 CLI 接口,便于快速部署和测试。
|
||||
- **高度可定制性:** 多种设置和参数可调,依据您的具体需求调整模型的推理行为。
|
||||
|
||||
### 预测模式的关键特性
|
||||
|
||||
YOLOv8 的预测模式被设计为强大且多功能,包括以下特性:
|
||||
|
||||
- **兼容多个数据来源:** 无论您的数据是单独图片,图片集合,视频文件,还是实时视频流,预测模式都能胜任。
|
||||
- **流式模式:** 使用流式功能生成一个内存高效的 `Results` 对象生成器。在调用预测器时,通过设置 `stream=True` 来启用此功能。
|
||||
- **批处理:** 能够在单个批次中处理多个图片或视频帧,进一步加快推理时间。
|
||||
- **易于集成:** 由于其灵活的 API,易于与现有数据管道和其他软件组件集成。
|
||||
|
||||
Ultralytics YOLO 模型在进行推理时返回一个 Python `Results` 对象列表,或者当传入 `stream=True` 时,返回一个内存高效的 Python `Results` 对象生成器:
|
||||
|
||||
!!! 示例 "预测"
|
||||
|
||||
=== "使用 `stream=False` 返回列表"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 预训练的 YOLOv8n 模型
|
||||
|
||||
# 在图片列表上运行批量推理
|
||||
results = model(['im1.jpg', 'im2.jpg']) # 返回 Results 对象列表
|
||||
|
||||
# 处理结果列表
|
||||
for result in results:
|
||||
boxes = result.boxes # 边界框输出的 Boxes 对象
|
||||
masks = result.masks # 分割掩码输出的 Masks 对象
|
||||
keypoints = result.keypoints # 姿态输出的 Keypoints 对象
|
||||
probs = result.probs # 分类输出的 Probs 对象
|
||||
```
|
||||
|
||||
=== "使用 `stream=True` 返回生成器"
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 预训练的 YOLOv8n 模型
|
||||
|
||||
# 在图片列表上运行批量推理
|
||||
results = model(['im1.jpg', 'im2.jpg'], stream=True) # 返回 Results 对象生成器
|
||||
|
||||
# 处理结果生成器
|
||||
for result in results:
|
||||
boxes = result.boxes # 边界框输出的 Boxes 对象
|
||||
masks = result.masks # 分割掩码输出的 Masks 对象
|
||||
keypoints = result.keypoints # 姿态输出的 Keypoints 对象
|
||||
probs = result.probs # 分类输出的 Probs 对象
|
||||
```
|
||||
|
||||
## 推理来源
|
||||
|
||||
YOLOv8 可以处理推理输入的不同类型,如下表所示。来源包括静态图像、视频流和各种数据格式。表格还表示了每种来源是否可以在流式模式下使用,使用参数 `stream=True` ✅。流式模式对于处理视频或实时流非常有利,因为它创建了结果的生成器,而不是将所有帧加载到内存。
|
||||
|
||||
!!! 提示 "提示"
|
||||
|
||||
使用 `stream=True` 处理长视频或大型数据集来高效地管理内存。当 `stream=False` 时,所有帧或数据点的结果都将存储在内存中,这可能很快导致内存不足错误。相对地,`stream=True` 使用生成器,只保留当前帧或数据点的结果在内存中,显著减少了内存消耗,防止内存不足问题。
|
||||
|
||||
| 来源 | 参数 | 类型 | 备注 |
|
||||
|-----------|--------------------------------------------|----------------|----------------------------------------------------|
|
||||
| 图像 | `'image.jpg'` | `str` 或 `Path` | 单个图像文件。 |
|
||||
| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | 图像的 URL 地址。 |
|
||||
| 截屏 | `'screen'` | `str` | 截取屏幕图像。 |
|
||||
| PIL | `Image.open('im.jpg')` | `PIL.Image` | RGB 通道的 HWC 格式图像。 |
|
||||
| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` | BGR 通道的 HWC 格式图像 `uint8 (0-255)`。 |
|
||||
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | BGR 通道的 HWC 格式图像 `uint8 (0-255)`。 |
|
||||
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | RGB 通道的 BCHW 格式图像 `float32 (0.0-1.0)`。 |
|
||||
| CSV | `'sources.csv'` | `str` 或 `Path` | 包含图像、视频或目录路径的 CSV 文件。 |
|
||||
| 视频 ✅ | `'video.mp4'` | `str` 或 `Path` | 如 MP4, AVI 等格式的视频文件。 |
|
||||
| 目录 ✅ | `'path/'` | `str` 或 `Path` | 包含图像或视频文件的目录路径。 |
|
||||
| 通配符 ✅ | `'path/*.jpg'` | `str` | 匹配多个文件的通配符模式。使用 `*` 字符作为通配符。 |
|
||||
| YouTube ✅ | `'https://youtu.be/LNwODJXcvt4'` | `str` | YouTube 视频的 URL 地址。 |
|
||||
| 流媒体 ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, TCP 或 IP 地址等流协议的 URL 地址。 |
|
||||
| 多流媒体 ✅ | `'list.streams'` | `str` 或 `Path` | 一个流 URL 每行的 `*.streams` 文本文件,例如 8 个流将以 8 的批处理大小运行。 |
|
||||
|
||||
下面为每种来源类型使用代码的示例:
|
||||
|
||||
!!! 示例 "预测来源"
|
||||
|
||||
=== "图像"
|
||||
对图像文件进行推理。
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 定义图像文件的路径
|
||||
source = 'path/to/image.jpg'
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source) # Results 对象列表
|
||||
```
|
||||
|
||||
=== "截屏"
|
||||
对当前屏幕内容作为截屏进行推理。
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 定义当前截屏为来源
|
||||
source = 'screen'
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source) # Results 对象列表
|
||||
```
|
||||
|
||||
=== "URL"
|
||||
对通过 URL 远程托管的图像或视频进行推理。
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 定义远程图像或视频 URL
|
||||
source = 'https://ultralytics.com/images/bus.jpg'
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source) # Results 对象列表
|
||||
```
|
||||
|
||||
=== "PIL"
|
||||
对使用 Python Imaging Library (PIL) 打开的图像进行推理。
|
||||
```python
|
||||
from PIL import Image
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 使用 PIL 打开图像
|
||||
source = Image.open('path/to/image.jpg')
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source) # Results 对象列表
|
||||
```
|
||||
|
||||
=== "OpenCV"
|
||||
对使用 OpenCV 读取的图像进行推理。
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 使用 OpenCV 读取图像
|
||||
source = cv2.imread('path/to/image.jpg')
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source) # Results 对象列表
|
||||
```
|
||||
|
||||
=== "numpy"
|
||||
对表示为 numpy 数组的图像进行推理。
|
||||
```python
|
||||
import numpy as np
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 创建一个 HWC 形状 (640, 640, 3) 的随机 numpy 数组,数值范围 [0, 255] 类型为 uint8
|
||||
source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype='uint8')
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source) # Results 对象列表
|
||||
```
|
||||
|
||||
=== "torch"
|
||||
对表示为 PyTorch 张量的图像进行推理。
|
||||
```python
|
||||
import torch
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 创建一个 BCHW 形状 (1, 3, 640, 640) 的随机 torch 张量,数值范围 [0, 1] 类型为 float32
|
||||
source = torch.rand(1, 3, 640, 640, dtype=torch.float32)
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source) # Results 对象列表
|
||||
```
|
||||
|
||||
=== "CSV"
|
||||
对 CSV 文件中列出的图像、URLs、视频和目录进行推理。
|
||||
```python
|
||||
import torch
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 定义一个包含图像、URLs、视频和目录路径的 CSV 文件路径
|
||||
source = 'path/to/file.csv'
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source) # Results 对象列表
|
||||
```
|
||||
|
||||
=== "视频"
|
||||
对视频文件进行推理。使用 `stream=True` 时,可以创建一个 Results 对象的生成器,减少内存使用。
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 定义视频文件路径
|
||||
source = 'path/to/video.mp4'
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source, stream=True) # Results 对象的生成器
|
||||
```
|
||||
|
||||
=== "目录"
|
||||
对目录中的所有图像和视频进行推理。要包含子目录中的图像和视频,使用通配符模式,例如 `path/to/dir/**/*`。
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 定义包含图像和视频文件用于推理的目录路径
|
||||
source = 'path/to/dir'
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source, stream=True) # Results 对象的生成器
|
||||
```
|
||||
|
||||
=== "通配符"
|
||||
对与 `*` 字符匹配的所有图像和视频进行推理。
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的 YOLOv8n 模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 定义一个目录下所有 JPG 文件的通配符搜索
|
||||
source = 'path/to/dir/*.jpg'
|
||||
|
||||
# 或定义一个包括子目录的所有 JPG 文件的递归通配符搜索
|
||||
source = 'path/to/dir/**/*.jpg'
|
||||
|
||||
# 对来源进行推理
|
||||
results = model(source, stream=True) # Results 对象的生成器
|
||||
```
|
||||
|
||||
=== "YouTube"
|
||||
在YouTube视频上运行推理。通过使用`stream=True`,您可以创建一个Results对象的生成器,以减少长视频的内存使用。
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 定义源为YouTube视频URL
|
||||
source = 'https://youtu.be/LNwODJXcvt4'
|
||||
|
||||
# 在源上运行推理
|
||||
results = model(source, stream=True) # Results对象的生成器
|
||||
```
|
||||
|
||||
=== "Streams"
|
||||
使用RTSP、RTMP、TCP和IP地址协议在远程流媒体源上运行推理。如果在`*.streams`文本文件中提供了多个流,则将运行批量推理,例如,8个流将以批大小8运行,否则单个流将以批大小1运行。
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 单流媒体源批大小1推理
|
||||
source = 'rtsp://example.com/media.mp4' # RTSP、RTMP、TCP或IP流媒体地址
|
||||
|
||||
# 多个流媒体源的批量推理(例如,8个流的批大小为8)
|
||||
source = 'path/to/list.streams' # *.streams文本文件,每行一个流媒体地址
|
||||
|
||||
# 在源上运行推理
|
||||
results = model(source, stream=True) # Results对象的生成器
|
||||
```
|
||||
|
||||
## 推理参数
|
||||
|
||||
`model.predict()` 在推理时接受多个参数,可以用来覆盖默认值:
|
||||
|
||||
!!! 示例
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 在'bus.jpg'上运行推理,并附加参数
|
||||
model.predict('bus.jpg', save=True, imgsz=320, conf=0.5)
|
||||
```
|
||||
|
||||
支持的所有参数:
|
||||
|
||||
| 名称 | 类型 | 默认值 | 描述 |
|
||||
|-----------------|----------------|------------------------|------------------------------------------|
|
||||
| `source` | `str` | `'ultralytics/assets'` | 图像或视频的源目录 |
|
||||
| `conf` | `float` | `0.25` | 检测对象的置信度阈值 |
|
||||
| `iou` | `float` | `0.7` | 用于NMS的交并比(IoU)阈值 |
|
||||
| `imgsz` | `int or tuple` | `640` | 图像大小,可以是标量或(h, w)列表,例如(640, 480) |
|
||||
| `half` | `bool` | `False` | 使用半精度(FP16) |
|
||||
| `device` | `None or str` | `None` | 运行设备,例如 cuda device=0/1/2/3 或 device=cpu |
|
||||
| `show` | `bool` | `False` | 如果可能,显示结果 |
|
||||
| `save` | `bool` | `False` | 保存带有结果的图像 |
|
||||
| `save_txt` | `bool` | `False` | 将结果保存为.txt文件 |
|
||||
| `save_conf` | `bool` | `False` | 保存带有置信度分数的结果 |
|
||||
| `save_crop` | `bool` | `False` | 保存带有结果的裁剪图像 |
|
||||
| `hide_labels` | `bool` | `False` | 隐藏标签 |
|
||||
| `hide_conf` | `bool` | `False` | 隐藏置信度分数 |
|
||||
| `max_det` | `int` | `300` | 每张图像的最大检测数量 |
|
||||
| `vid_stride` | `bool` | `False` | 视频帧速率跳跃 |
|
||||
| `stream_buffer` | `bool` | `False` | 缓冲所有流媒体帧(True)或返回最新帧(False) |
|
||||
| `line_width` | `None or int` | `None` | 边框线宽度。如果为None,则按图像大小缩放。 |
|
||||
| `visualize` | `bool` | `False` | 可视化模型特征 |
|
||||
| `augment` | `bool` | `False` | 应用图像增强到预测源 |
|
||||
| `agnostic_nms` | `bool` | `False` | 类别不敏感的NMS |
|
||||
| `retina_masks` | `bool` | `False` | 使用高分辨率分割掩码 |
|
||||
| `classes` | `None or list` | `None` | 按类别过滤结果,例如 classes=0,或 classes=[0,2,3] |
|
||||
| `boxes` | `bool` | `True` | 在分割预测中显示框 |
|
||||
|
||||
## 图像和视频格式
|
||||
|
||||
YOLOv8支持多种图像和视频格式,如[data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/data/utils.py)所指定。请参阅下表了解有效的后缀名和示例预测命令。
|
||||
|
||||
### 图像
|
||||
|
||||
以下表格包含有效的Ultralytics图像格式。
|
||||
|
||||
| 图像后缀名 | 示例预测命令 | 参考链接 | |
|
||||
|
||||
----------------|-----------------------------------------|-------------------------------------------------------------------------------| | .bmp | `yolo predict source=image.bmp` | [Microsoft BMP文件格式](https://en.wikipedia.org/wiki/BMP_file_format) | | .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) | | .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) | | .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) | | .mpo | `yolo predict source=image.mpo` | [多图像对象](https://fileinfo.com/extension/mpo) | | .png | `yolo predict source=image.png` | [便携式网络图形](https://en.wikipedia.org/wiki/PNG) | | .tif | `yolo predict source=image.tif` | [标签图像文件格式](https://en.wikipedia.org/wiki/TIFF) | | .tiff | `yolo predict source=image.tiff` | [标签图像文件格式](https://en.wikipedia.org/wiki/TIFF) | | .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) | | .pfm | `yolo predict source=image.pfm` | [便携式浮点图](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
|
||||
|
||||
### 视频
|
||||
|
||||
以下表格包含有效的Ultralytics视频格式。
|
||||
|
||||
| 视频后缀名 | 示例预测命令 | 参考链接 |
|
||||
|-------|----------------------------------|----------------------------------------------------------------------|
|
||||
| .asf | `yolo predict source=video.asf` | [高级系统格式](https://en.wikipedia.org/wiki/Advanced_Systems_Format) |
|
||||
| .avi | `yolo predict source=video.avi` | [音视频交错](https://en.wikipedia.org/wiki/Audio_Video_Interleave) |
|
||||
| .gif | `yolo predict source=video.gif` | [图形交换格式](https://en.wikipedia.org/wiki/GIF) |
|
||||
| .m4v | `yolo predict source=video.m4v` | [MPEG-4第14部分](https://en.wikipedia.org/wiki/M4V) |
|
||||
| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) |
|
||||
| .mov | `yolo predict source=video.mov` | [QuickTime文件格式](https://en.wikipedia.org/wiki/QuickTime_File_Format) |
|
||||
| .mp4 | `yolo predict source=video.mp4` | [MPEG-4第14部分](https://en.wikipedia.org/wiki/MPEG-4_Part_14) |
|
||||
| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1第2部分](https://en.wikipedia.org/wiki/MPEG-1) |
|
||||
| .mpg | `yolo predict source=video.mpg` | [MPEG-1第2部分](https://en.wikipedia.org/wiki/MPEG-1) |
|
||||
| .ts | `yolo predict source=video.ts` | [MPEG传输流](https://en.wikipedia.org/wiki/MPEG_transport_stream) |
|
||||
| .wmv | `yolo predict source=video.wmv` | [Windows媒体视频](https://en.wikipedia.org/wiki/Windows_Media_Video) |
|
||||
| .webm | `yolo predict source=video.webm` | [WebM项目](https://en.wikipedia.org/wiki/WebM) |
|
||||
|
||||
## 处理结果
|
||||
|
||||
所有Ultralytics的`predict()`调用都将返回一个`Results`对象列表:
|
||||
|
||||
!!! 示例 "结果"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 在图片上运行推理
|
||||
results = model('bus.jpg') # 1个Results对象的列表
|
||||
results = model(['bus.jpg', 'zidane.jpg']) # 2个Results对象的列表
|
||||
```
|
||||
|
||||
`Results`对象具有以下属性:
|
||||
|
||||
| 属性 | 类型 | 描述 |
|
||||
|--------------|-----------------|------------------------------|
|
||||
| `orig_img` | `numpy.ndarray` | 原始图像的numpy数组。 |
|
||||
| `orig_shape` | `tuple` | 原始图像的形状,格式为(高度,宽度)。 |
|
||||
| `boxes` | `Boxes, 可选` | 包含检测边界框的Boxes对象。 |
|
||||
| `masks` | `Masks, 可选` | 包含检测掩码的Masks对象。 |
|
||||
| `probs` | `Probs, 可选` | 包含每个类别的概率的Probs对象,用于分类任务。 |
|
||||
| `keypoints` | `Keypoints, 可选` | 包含每个对象检测到的关键点的Keypoints对象。 |
|
||||
| `speed` | `dict` | 以毫秒为单位的每张图片的预处理、推理和后处理速度的字典。 |
|
||||
| `names` | `dict` | 类别名称的字典。 |
|
||||
| `path` | `str` | 图像文件的路径。 |
|
||||
|
||||
`Results`对象具有以下方法:
|
||||
|
||||
| 方法 | 返回类型 | 描述 |
|
||||
|-----------------|-----------------|----------------------------------------|
|
||||
| `__getitem__()` | `Results` | 返回指定索引的Results对象。 |
|
||||
| `__len__()` | `int` | 返回Results对象中的检测数量。 |
|
||||
| `update()` | `None` | 更新Results对象的boxes, masks和probs属性。 |
|
||||
| `cpu()` | `Results` | 将所有张量移动到CPU内存上的Results对象的副本。 |
|
||||
| `numpy()` | `Results` | 将所有张量转换为numpy数组的Results对象的副本。 |
|
||||
| `cuda()` | `Results` | 将所有张量移动到GPU内存上的Results对象的副本。 |
|
||||
| `to()` | `Results` | 返回将张量移动到指定设备和dtype的Results对象的副本。 |
|
||||
| `new()` | `Results` | 返回一个带有相同图像、路径和名称的新Results对象。 |
|
||||
| `keys()` | `List[str]` | 返回非空属性名称的列表。 |
|
||||
| `plot()` | `numpy.ndarray` | 绘制检测结果。返回带有注释的图像的numpy数组。 |
|
||||
| `verbose()` | `str` | 返回每个任务的日志字符串。 |
|
||||
| `save_txt()` | `None` | 将预测保存到txt文件中。 |
|
||||
| `save_crop()` | `None` | 将裁剪的预测保存到`save_dir/cls/file_name.jpg`。 |
|
||||
| `tojson()` | `None` | 将对象转换为JSON格式。 |
|
||||
|
||||
有关更多详细信息,请参阅`Results`类的[文档](/../reference/engine/results.md)。
|
||||
|
||||
### 边界框(Boxes)
|
||||
|
||||
`Boxes`对象可用于索引、操作和转换边界框到不同格式。
|
||||
|
||||
!!! 示例 "边界框(Boxes)"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 在图片上运行推理
|
||||
results = model('bus.jpg')
|
||||
|
||||
# results列表
|
||||
|
||||
# 查看结果
|
||||
for r in results:
|
||||
print(r.boxes) # 打印包含检测边界框的Boxes对象
|
||||
```
|
||||
|
||||
以下是`Boxes`类方法和属性的表格,包括它们的名称、类型和描述:
|
||||
|
||||
| 名称 | 类型 | 描述 |
|
||||
|-----------|---------------------|-------------------------|
|
||||
| `cpu()` | 方法 | 将对象移动到CPU内存。 |
|
||||
| `numpy()` | 方法 | 将对象转换为numpy数组。 |
|
||||
| `cuda()` | 方法 | 将对象移动到CUDA内存。 |
|
||||
| `to()` | 方法 | 将对象移动到指定的设备。 |
|
||||
| `xyxy` | 属性 (`torch.Tensor`) | 以xyxy格式返回边界框。 |
|
||||
| `conf` | 属性 (`torch.Tensor`) | 返回边界框的置信度值。 |
|
||||
| `cls` | 属性 (`torch.Tensor`) | 返回边界框的类别值。 |
|
||||
| `id` | 属性 (`torch.Tensor`) | 返回边界框的跟踪ID(如果可用)。 |
|
||||
| `xywh` | 属性 (`torch.Tensor`) | 以xywh格式返回边界框。 |
|
||||
| `xyxyn` | 属性 (`torch.Tensor`) | 以原始图像大小归一化的xyxy格式返回边界框。 |
|
||||
| `xywhn` | 属性 (`torch.Tensor`) | 以原始图像大小归一化的xywh格式返回边界框。 |
|
||||
|
||||
有关更多详细信息,请参阅`Boxes`类的[文档](/../reference/engine/results.md)。
|
||||
|
||||
### 掩码(Masks)
|
||||
|
||||
`Masks`对象可用于索引、操作和将掩码转换为分段。
|
||||
|
||||
!!! 示例 "掩码(Masks)"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n-seg分割模型
|
||||
model = YOLO('yolov8n-seg.pt')
|
||||
|
||||
# 在图片上运行推理
|
||||
results = model('bus.jpg') # results列表
|
||||
|
||||
# 查看结果
|
||||
for r in results:
|
||||
print(r.masks) # 打印包含检测到的实例掩码的Masks对象
|
||||
```
|
||||
|
||||
以下是`Masks`类方法和属性的表格,包括它们的名称、类型和描述:
|
||||
|
||||
| 名称 | 类型 | 描述 |
|
||||
|-----------|---------------------|----------------------|
|
||||
| `cpu()` | 方法 | 将掩码张量返回到CPU内存。 |
|
||||
| `numpy()` | 方法 | 将掩码张量转换为numpy数组。 |
|
||||
| `cuda()` | 方法 | 将掩码张量返回到GPU内存。 |
|
||||
| `to()` | 方法 | 将掩码张量带有指定设备和dtype返回。 |
|
||||
| `xyn` | 属性 (`torch.Tensor`) | 以张量表示的归一化分段的列表。 |
|
||||
| `xy` | 属性 (`torch.Tensor`) | 以像素坐标表示的分段的张量列表。 |
|
||||
|
||||
有关更多详细信息,请参阅`Masks`类的[文档](/../reference/engine/results.md)。
|
||||
|
||||
### 关键点 (Keypoints)
|
||||
|
||||
`Keypoints` 对象可以用于索引、操作和规范化坐标。
|
||||
|
||||
!!! 示例 "关键点"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n-pose 姿态模型
|
||||
model = YOLO('yolov8n-pose.pt')
|
||||
|
||||
# 在图像上运行推理
|
||||
results = model('bus.jpg') # 结果列表
|
||||
|
||||
# 查看结果
|
||||
for r in results:
|
||||
print(r.keypoints) # 打印包含检测到的关键点的Keypoints对象
|
||||
```
|
||||
|
||||
以下是`Keypoints`类方法和属性的表格,包括它们的名称、类型和描述:
|
||||
|
||||
| 名称 | 类型 | 描述 |
|
||||
|-----------|--------------------|---------------------------|
|
||||
| `cpu()` | 方法 | 返回CPU内存上的关键点张量。 |
|
||||
| `numpy()` | 方法 | 返回作为numpy数组的关键点张量。 |
|
||||
| `cuda()` | 方法 | 返回GPU内存上的关键点张量。 |
|
||||
| `to()` | 方法 | 返回指定设备和dtype的关键点张量。 |
|
||||
| `xyn` | 属性(`torch.Tensor`) | 规范化关键点的列表,表示为张量。 |
|
||||
| `xy` | 属性(`torch.Tensor`) | 以像素坐标表示的关键点列表,表示为张量。 |
|
||||
| `conf` | 属性(`torch.Tensor`) | 返回关键点的置信度值(如果有),否则返回None。 |
|
||||
|
||||
有关更多详细信息,请参阅`Keypoints`类[文档](/../reference/engine/results.md)。
|
||||
|
||||
### 概率 (Probs)
|
||||
|
||||
`Probs` 对象可以用于索引,获取分类的 `top1` 和 `top5` 索引和分数。
|
||||
|
||||
!!! 示例 "概率"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n-cls 分类模型
|
||||
model = YOLO('yolov8n-cls.pt')
|
||||
|
||||
# 在图像上运行推理
|
||||
results = model('bus.jpg') # 结果列表
|
||||
|
||||
# 查看结果
|
||||
for r in results:
|
||||
print(r.probs) # 打印包含检测到的类别概率的Probs对象
|
||||
```
|
||||
|
||||
以下是`Probs`类的方法和属性的表格总结:
|
||||
|
||||
| 名称 | 类型 | 描述 |
|
||||
|------------|--------------------|-------------------------|
|
||||
| `cpu()` | 方法 | 返回CPU内存上的概率张量的副本。 |
|
||||
| `numpy()` | 方法 | 返回概率张量的副本作为numpy数组。 |
|
||||
| `cuda()` | 方法 | 返回GPU内存上的概率张量的副本。 |
|
||||
| `to()` | 方法 | 返回带有指定设备和dtype的概率张量的副本。 |
|
||||
| `top1` | 属性(`int`) | 第1类的索引。 |
|
||||
| `top5` | 属性(`list[int]`) | 前5类的索引。 |
|
||||
| `top1conf` | 属性(`torch.Tensor`) | 第1类的置信度。 |
|
||||
| `top5conf` | 属性(`torch.Tensor`) | 前5类的置信度。 |
|
||||
|
||||
有关更多详细信息,请参阅`Probs`类[文档](/../reference/engine/results.md)。
|
||||
|
||||
## 绘制结果
|
||||
|
||||
您可以使用`Result`对象的`plot()`方法来可视化预测结果。它会将`Results`对象中包含的所有预测类型(框、掩码、关键点、概率等)绘制到一个numpy数组上,然后可以显示或保存。
|
||||
|
||||
!!! 示例 "绘制"
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载预训练的YOLOv8n模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 在'bus.jpg'上运行推理
|
||||
results = model('bus.jpg') # 结果列表
|
||||
|
||||
# 展示结果
|
||||
for r in results:
|
||||
im_array = r.plot() # 绘制包含预测结果的BGR numpy数组
|
||||
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
|
||||
im.show() # 显示图像
|
||||
im.save('results.jpg') # 保存图像
|
||||
```
|
||||
|
||||
`plot()`方法支持以下参数:
|
||||
|
||||
| 参数 | 类型 | 描述 | 默认值 |
|
||||
|---------------|-----------------|------------------------------------------------------------------------|---------------|
|
||||
| `conf` | `bool` | 是否绘制检测置信度分数。 | `True` |
|
||||
| `line_width` | `float` | 边框线宽度。如果为None,则按图像大小缩放。 | `None` |
|
||||
| `font_size` | `float` | 文本字体大小。如果为None,则按图像大小缩放。 | `None` |
|
||||
| `font` | `str` | 文本字体。 | `'Arial.ttf'` |
|
||||
| `pil` | `bool` | 是否将图像返回为PIL图像。 | `False` |
|
||||
| `img` | `numpy.ndarray` | 绘制到另一个图像上。如果没有,则绘制到原始图像上。 | `None` |
|
||||
| `im_gpu` | `torch.Tensor` | 形状为(1, 3, 640, 640)的规范化GPU图像,用于更快地绘制掩码。 | `None` |
|
||||
| `kpt_radius` | `int` | 绘制关键点的半径。默认为5。 | `5` |
|
||||
| `kpt_line` | `bool` | 是否绘制连接关键点的线条。 | `True` |
|
||||
| `labels` | `bool` | 是否绘制边框标签。 | `True` |
|
||||
| `boxes` | `bool` | 是否绘制边框。 | `True` |
|
||||
| `masks` | `bool` | 是否绘制掩码。 | `True` |
|
||||
| `probs` | `bool` | 是否绘制分类概率 | `True` |
|
||||
|
||||
## 线程安全推理
|
||||
|
||||
在多线程中并行运行多个YOLO模型时,确保推理过程的线程安全性至关重要。线程安全的推理保证了每个线程的预测结果是隔离的,不会相互干扰,避免竞态条件,确保输出的一致性和可靠性。
|
||||
|
||||
在多线程应用中使用YOLO模型时,重要的是为每个线程实例化单独的模型对象,或使用线程本地存储来防止冲突:
|
||||
|
||||
!!! 示例 "线程安全推理"
|
||||
|
||||
在每个线程内实例化单个模型以实现线程安全的推理:
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
from threading import Thread
|
||||
|
||||
def thread_safe_predict(image_path):
|
||||
# 在线程内实例化新模型
|
||||
local_model = YOLO("yolov8n.pt")
|
||||
results = local_model.predict(image_path)
|
||||
# 处理结果
|
||||
|
||||
# 启动拥有各自模型实例的线程
|
||||
Thread(target=thread_safe_predict, args=("image1.jpg",)).start()
|
||||
Thread(target=thread_safe_predict, args=("image2.jpg",)).start()
|
||||
```
|
||||
|
||||
有关YOLO模型线程安全推理的深入讨论和逐步指导,请参阅我们的[YOLO线程安全推理指南](/../guides/yolo-thread-safe-inference.md)。该指南将为您提供避免常见陷阱并确保多线程推理顺利进行所需的所有必要信息。
|
||||
|
||||
## 流媒体源`for`循环
|
||||
|
||||
以下是使用OpenCV(`cv2`)和YOLOv8在视频帧上运行推理的Python脚本。此脚本假设您已经安装了必要的包(`opencv-python`和`ultralytics`)。
|
||||
|
||||
!!! 示例 "流媒体for循环"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载YOLOv8模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 打开视频文件
|
||||
video_path = "path/to/your/video/file.mp4"
|
||||
cap = cv2.VideoCapture(video_path)
|
||||
|
||||
# 遍历视频帧
|
||||
while cap.isOpened():
|
||||
# 从视频中读取一帧
|
||||
success, frame = cap.read()
|
||||
|
||||
if success:
|
||||
# 在该帧上运行YOLOv8推理
|
||||
results = model(frame)
|
||||
|
||||
# 在帧上可视化结果
|
||||
annotated_frame = results[0].plot()
|
||||
|
||||
# 显示带注释的帧
|
||||
cv2.imshow("YOLOv8推理", annotated_frame)
|
||||
|
||||
# 如果按下'q'则中断循环
|
||||
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||
break
|
||||
else:
|
||||
# 如果视频结束则中断循环
|
||||
break
|
||||
|
||||
# 释放视频捕获对象并关闭显示窗口
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
此脚本将对视频的每一帧进行预测,可视化结果,并在窗口中显示。按下'q'键可以退出循环。
|
||||
277
docs/zh/modes/track.md
Normal file
277
docs/zh/modes/track.md
Normal file
|
|
@ -0,0 +1,277 @@
|
|||
---
|
||||
评论: 真
|
||||
描述: 学习如何使用Ultralytics YOLO进行视频流中的物体追踪。指南包括使用不同的追踪器和自定义追踪器配置。
|
||||
关键词: Ultralytics, YOLO, 物体追踪, 视频流, BoT-SORT, ByteTrack, Python 指南, CLI 指南
|
||||
---
|
||||
|
||||
# 使用Ultralytics YOLO进行多物体追踪
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418637-1d6250fd-1515-4c10-a844-a32818ae6d46.png" alt="多物体追踪示例">
|
||||
|
||||
视频分析领域的物体追踪是一项关键任务,它不仅能标识出帧内物体的位置和类别,还能在视频进行过程中为每个检测到的物体保持一个唯一的ID。应用场景无限广阔——从监控与安全到实时体育分析。
|
||||
|
||||
## 为什么选择Ultralytics YOLO进行物体追踪?
|
||||
|
||||
Ultralytics 追踪器的输出与标准的物体检测结果一致,但增加了物体ID的附加值。这使其易于追踪视频流中的物体并进行后续分析。以下是您应考虑使用Ultralytics YOLO来满足您物体追踪需求的原因:
|
||||
|
||||
- **效率:** 实时处理视频流,同时保持准确性。
|
||||
- **灵活性:** 支持多种追踪算法和配置。
|
||||
- **易用性:** 简单的Python API和CLI选项,便于快速集成和部署。
|
||||
- **可定制性:** 易于使用自定义训练的YOLO模型,允许集成到特定领域的应用中。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/hHyHmOtmEgs?si=VNZtXmm45Nb9s-N-"
|
||||
title="YouTube视频播放器" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong>使用Ultralytics YOLOv8的物体检测与追踪。
|
||||
</p>
|
||||
|
||||
## 实际应用场景
|
||||
|
||||
| 交通运输 | 零售 | 水产养殖 |
|
||||
|:----------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------:|
|
||||
|  |  |  |
|
||||
| 车辆追踪 | 人员追踪 | 鱼类追踪 |
|
||||
|
||||
## 一瞥特点
|
||||
|
||||
Ultralytics YOLO扩展了其物体检测功能,以提供强大且多功能的物体追踪:
|
||||
|
||||
- **实时追踪:** 在高帧率视频中无缝追踪物体。
|
||||
- **支持多个追踪器:** 从多种成熟的追踪算法中选择。
|
||||
- **自定义追踪器配置:** 通过调整各种参数来定制追踪算法,以满足特定需求。
|
||||
|
||||
## 可用的追踪器
|
||||
|
||||
Ultralytics YOLO支持以下追踪算法。可以通过传递相关的YAML配置文件如`tracker=tracker_type.yaml`来启用:
|
||||
|
||||
* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - 使用 `botsort.yaml` 启用此追踪器。
|
||||
* [ByteTrack](https://github.com/ifzhang/ByteTrack) - 使用 `bytetrack.yaml` 启用此追踪器。
|
||||
|
||||
默认追踪器是BoT-SORT。
|
||||
|
||||
## 追踪
|
||||
|
||||
要在视频流中运行追踪器,请使用已训练的检测、分割或姿态模型,例如YOLOv8n、YOLOv8n-seg和YOLOv8n-pose。
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载官方或自定义模型
|
||||
model = YOLO('yolov8n.pt') # 加载一个官方的检测模型
|
||||
model = YOLO('yolov8n-seg.pt') # 加载一个官方的分割模型
|
||||
model = YOLO('yolov8n-pose.pt') # 加载一个官方的姿态模型
|
||||
model = YOLO('path/to/best.pt') # 加载一个自定义训练的模型
|
||||
|
||||
# 使用模型进行追踪
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True) # 使用默认追踪器进行追踪
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml") # 使用ByteTrack追踪器进行追踪
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 使用命令行界面进行各种模型的追踪
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" # 官方检测模型
|
||||
yolo track model=yolov8n-seg.pt source="https://youtu.be/LNwODJXcvt4" # 官方分割模型
|
||||
yolo track model=yolov8n-pose.pt source="https://youtu.be/LNwODJXcvt4" # 官方姿态模型
|
||||
yolo track model=path/to/best.pt source="https://youtu.be/LNwODJXcvt4" # 自定义训练模型
|
||||
|
||||
# 使用ByteTrack追踪器进行追踪
|
||||
yolo track model=path/to/best.pt tracker="bytetrack.yaml"
|
||||
```
|
||||
|
||||
如上所述,Detect、Segment和Pose模型在视频或流媒体源上运行时均可进行追踪。
|
||||
|
||||
## 配置
|
||||
|
||||
### 追踪参数
|
||||
|
||||
追踪配置与预测模式共享一些属性,如`conf`、`iou`和`show`。有关进一步配置,请参见[预测](https://docs.ultralytics.com/modes/predict/)模型页面。
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 配置追踪参数并运行追踪器
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 使用命令行界面配置追踪参数并运行追踪器
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3, iou=0.5 show
|
||||
```
|
||||
|
||||
### 选择追踪器
|
||||
|
||||
Ultralytics还允许您使用修改后的追踪器配置文件。要执行此操作,只需从[ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers)中复制一个追踪器配置文件(例如,`custom_tracker.yaml`)并根据您的需求修改任何配置(除了`tracker_type`)。
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型并使用自定义配置文件运行追踪器
|
||||
model = YOLO('yolov8n.pt')
|
||||
results = model.track(source="https://youtu.be/LNwODJXcvt4", tracker='custom_tracker.yaml')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 使用命令行界面加载模型并使用自定义配置文件运行追踪器
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" tracker='custom_tracker.yaml'
|
||||
```
|
||||
|
||||
有关追踪参数的全面列表,请参考[ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers)页面。
|
||||
|
||||
## Python示例
|
||||
|
||||
### 持续追踪循环
|
||||
|
||||
这是一个使用OpenCV(`cv2`)和YOLOv8在视频帧上运行物体追踪的Python脚本。此脚本假设您已经安装了必要的包(`opencv-python`和`ultralytics`)。参数`persist=True`告诉追踪器当前的图像或帧是序列中的下一个,并且期望在当前图像中从上一个图像中获得追踪路径。
|
||||
|
||||
!!! 示例 "带追踪功能的流循环"
|
||||
|
||||
```python
|
||||
import cv2
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载YOLOv8模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 打开视频文件
|
||||
video_path = "path/to/video.mp4"
|
||||
cap = cv2.VideoCapture(video_path)
|
||||
|
||||
# 循环遍历视频帧
|
||||
while cap.isOpened():
|
||||
# 从视频读取一帧
|
||||
success, frame = cap.read()
|
||||
|
||||
if success:
|
||||
# 在帧上运行YOLOv8追踪,持续追踪帧间的物体
|
||||
results = model.track(frame, persist=True)
|
||||
|
||||
# 在帧上展示结果
|
||||
annotated_frame = results[0].plot()
|
||||
|
||||
# 展示带注释的帧
|
||||
cv2.imshow("YOLOv8 Tracking", annotated_frame)
|
||||
|
||||
# 如果按下'q'则退出循环
|
||||
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||
break
|
||||
else:
|
||||
# 如果视频结束则退出循环
|
||||
break
|
||||
|
||||
# 释放视频捕获对象并关闭显示窗口
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
请注意从`model(frame)`更改为`model.track(frame)`的变化,这使能够启用物体追踪而不只是简单的检测。这个修改的脚本将在视频的每一帧上运行追踪器,可视化结果,并在窗口中显示它们。通过按'q'可以退出循环。
|
||||
|
||||
### 随时间绘制追踪路径
|
||||
|
||||
在连续帧上可视化物体追踪路径可以提供有关视频中检测到的物体的运动模式和行为的有价值的洞见。使用Ultralytics YOLOv8,绘制这些路径是一个无缝且高效的过程。
|
||||
|
||||
在以下示例中,我们演示了如何利用YOLOv8的追踪功能在多个视频帧上绘制检测物体的移动。这个脚本涉及打开视频文件、逐帧读取,并使用YOLO模型识别并追踪各种物体。通过保留检测到的边界框的中心点并连接它们,我们可以绘制表示跟踪物体路径的线条。
|
||||
|
||||
!!! 示例 "在多个视频帧上绘制追踪路径"
|
||||
|
||||
```python
|
||||
from collections import defaultdict
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载YOLOv8模型
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 打开视频文件
|
||||
video_path = "path/to/video.mp4"
|
||||
cap = cv2.VideoCapture(video_path)
|
||||
|
||||
# 存储追踪历史
|
||||
track_history = defaultdict(lambda: [])
|
||||
|
||||
# 循环遍历视频帧
|
||||
while cap.isOpened():
|
||||
# 从视频读取一帧
|
||||
success, frame = cap.read()
|
||||
|
||||
if success:
|
||||
# 在帧上运行YOLOv8追踪,持续追踪帧间的物体
|
||||
results = model.track(frame, persist=True)
|
||||
|
||||
# 获取框和追踪ID
|
||||
boxes = results[0].boxes.xywh.cpu()
|
||||
track_ids = results[0].boxes.id.int().cpu().tolist()
|
||||
|
||||
# 在帧上展示结果
|
||||
annotated_frame = results[0].plot()
|
||||
|
||||
# 绘制追踪路径
|
||||
for box, track_id in zip(boxes, track_ids):
|
||||
x, y, w, h = box
|
||||
track = track_history[track_id]
|
||||
track.append((float(x), float(y))) # x, y中心点
|
||||
if len(track) > 30: # 在90帧中保留90个追踪点
|
||||
track.pop(0)
|
||||
|
||||
# 绘制追踪线
|
||||
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
|
||||
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
|
||||
|
||||
# 展示带注释的帧
|
||||
cv2.imshow("YOLOv8 Tracking", annotated_frame)
|
||||
|
||||
# 如果按下'q'则退出循环
|
||||
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||
break
|
||||
else:
|
||||
# 如果视频结束则退出循环
|
||||
break
|
||||
|
||||
# 释放视频捕获对象并关闭显示窗口
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
|
||||
### 多线程追踪
|
||||
|
||||
多线程追踪提供了同时在多个视频流上运行物体追踪的能力。当处理多个视频输入,例如来自多个监控摄像头时,这一功能特别有用,其中并发处理可以大大提高效率和性能。
|
||||
|
||||
在提供的Python脚本中,我们利用Python的`threading`模块来同时运行多个追踪器实例。每个线程负责在一个视频文件上运行追踪器,所有线程在后台同时运行。
|
||||
|
||||
为了确保每个线程接收到正确的参数(视频文件、要使用的模型和文件索引),我们定义了一个函数`run_tracker_in_thread`,它接受这些参数并包含主追踪循环。此函数逐帧读取视频,运行追踪器,并显示结果。
|
||||
|
||||
在这个例子中,两个不同的模型被使用:`yolov8n.pt`和`yolov8n-seg.pt`,每个模型都在不同的视频文件中追踪物体。视频文件分别指定在`video_file1`和`video_file2`中。
|
||||
|
||||
在`threading.Thread`中参数`daemon=True`表示,这些线程会在主程序结束时关闭。然后我们用`start()`来开始线程,并使用`join()`来使主线程等待,直到两个追踪线程都结束。
|
||||
|
||||
最后,在所有线程完成任务后,使用`cv2.destroyAllWindows()`关闭显示结果的窗口。
|
||||
|
||||
!!! 示例 "带追踪功能的流循环"
|
||||
|
||||
```pyth
|
||||
294
docs/zh/modes/train.md
Normal file
294
docs/zh/modes/train.md
Normal file
|
|
@ -0,0 +1,294 @@
|
|||
---
|
||||
评论: 真
|
||||
描述: 使用Ultralytics YOLO训练YOLOv8模型的逐步指南,包括单GPU和多GPU训练示例
|
||||
关键词: Ultralytics, YOLOv8, YOLO, 目标检测, 训练模式, 自定义数据集, GPU训练, 多GPU, 超参数, CLI示例, Python示例
|
||||
---
|
||||
|
||||
# 使用Ultralytics YOLO进行模型训练
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO生态系统与集成">
|
||||
|
||||
## 引言
|
||||
|
||||
训练深度学习模型涉及向其输入数据并调整参数,以便准确预测。Ultralytics YOLOv8的训练模式旨在有效高效地训练目标检测模型,充分利用现代硬件功能。本指南旨在涵盖使用YOLOv8的强大功能集训练自己模型的所有细节。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/LNwODJXcvt4?si=7n1UvGRLSd9p5wKs"
|
||||
title="YouTube视频播放器" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong> 如何在Google Colab中用你的自定义数据集训练一个YOLOv8模型。
|
||||
</p>
|
||||
|
||||
## 为什么选择Ultralytics YOLO进行训练?
|
||||
|
||||
以下是选择YOLOv8训练模式的一些有力理由:
|
||||
|
||||
- **效率:** 充分利用您的硬件资源,无论您是使用单GPU设置还是跨多个GPU扩展。
|
||||
- **多功能:** 除了可随时获取的数据集(如COCO、VOC和ImageNet)之外,还可以对自定义数据集进行训练。
|
||||
- **用户友好:** 简单而强大的CLI和Python接口,为您提供直接的训练体验。
|
||||
- **超参数灵活性:** 可定制的广泛超参数范围,以微调模型性能。
|
||||
|
||||
### 训练模式的关键特性
|
||||
|
||||
以下是YOLOv8训练模式的一些显著特点:
|
||||
|
||||
- **自动数据集下载:** 标准数据集如COCO、VOC和ImageNet将在首次使用时自动下载。
|
||||
- **多GPU支持:** 无缝地跨多个GPU扩展您的训练工作,以加快过程。
|
||||
- **超参数配置:** 通过YAML配置文件或CLI参数修改超参数的选项。
|
||||
- **可视化和监控:** 实时跟踪训练指标并可视化学习过程,以获得更好的洞察力。
|
||||
|
||||
!!! 小贴士 "小贴士"
|
||||
|
||||
* 如COCO、VOC、ImageNet等YOLOv8数据集在首次使用时会自动下载,即 `yolo train data=coco.yaml`
|
||||
|
||||
## 使用示例
|
||||
|
||||
在COCO128数据集上训练YOLOv8n模型100个时期,图像大小为640。可以使用`device`参数指定训练设备。如果没有传递参数,并且有可用的GPU,则将使用GPU `device=0`,否则将使用`device=cpu`。有关完整列表的训练参数,请参见下面的参数部分。
|
||||
|
||||
!!! 示例 "单GPU和CPU训练示例"
|
||||
|
||||
设备将自动确定。如果有可用的GPU,那么将使用它,否则将在CPU上开始训练。
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载一个模型
|
||||
model = YOLO('yolov8n.yaml') # 从YAML建立一个新模型
|
||||
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
|
||||
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML建立并转移权重
|
||||
|
||||
# 训练模型
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 从YAML构建新模型,从头开始训练
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||
|
||||
# 从预训练*.pt模型开始训练
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
|
||||
# 从YAML构建一个新模型,转移预训练权重,然后开始训练
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### 多GPU训练
|
||||
|
||||
多GPU训练通过在多个GPU上分布训练负载,实现对可用硬件资源的更有效利用。无论是通过Python API还是命令行界面,都可以使用此功能。 若要启用多GPU训练,请指定您希望使用的GPU设备ID。
|
||||
|
||||
!!! 示例 "多GPU训练示例"
|
||||
|
||||
要使用2个GPU进行训练,请使用CUDA设备0和1,使用以下命令。根据需要扩展到更多GPU。
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
|
||||
|
||||
# 使用2个GPU训练模型
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 使用GPU 0和1从预训练*.pt模型开始训练
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
|
||||
```
|
||||
|
||||
### 苹果M1和M2 MPS训练
|
||||
|
||||
通过Ultralytics YOLO模型集成对Apple M1和M2芯片的支持,现在可以在使用强大的Metal性能着色器(MPS)框架的设备上训练模型。MPS为在Apple的定制硅上执行计算和图像处理任务提供了一种高性能的方法。
|
||||
|
||||
要在Apple M1和M2芯片上启用训练,您应该在启动训练过程时将设备指定为'mps'。以下是Python和命令行中如何做到这点的示例:
|
||||
|
||||
!!! 示例 "MPS训练示例"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
|
||||
|
||||
# 使用2个GPU训练模型
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640, device='mps')
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 使用GPU 0和1从预训练*.pt模型开始训练
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
|
||||
```
|
||||
|
||||
利用M1/M2芯片的计算能力,这使得训练任务的处理更加高效。有关更详细的指南和高级配置选项,请参阅[PyTorch MPS文档](https://pytorch.org/docs/stable/notes/mps.html)。
|
||||
|
||||
### 恢复中断的训练
|
||||
|
||||
在处理深度学习模型时,从之前保存的状态恢复训练是一个关键特性。在各种情况下,这可能很方便,比如当训练过程意外中断,或者当您希望用新数据或更多时期继续训练模型时。
|
||||
|
||||
恢复训练时,Ultralytics YOLO将加载最后保存的模型的权重,并恢复优化器状态、学习率调度器和时期编号。这允许您无缝地从离开的地方继续训练过程。
|
||||
|
||||
在Ultralytics YOLO中,您可以通过在调用`train`方法时将`resume`参数设置为`True`并指定包含部分训练模型权重的`.pt`文件路径来轻松恢复训练。
|
||||
|
||||
下面是使用Python和命令行恢复中断训练的示例:
|
||||
|
||||
!!! 示例 "恢复训练示例"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('path/to/last.pt') # 加载部分训练的模型
|
||||
|
||||
# 恢复训练
|
||||
results = model.train(resume=True)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 恢复中断的训练
|
||||
yolo train resume model=path/to/last.pt
|
||||
```
|
||||
|
||||
通过设置`resume=True`,`train`函数将从'path/to/last.pt'文件中存储的状态继续训练。如果省略`resume`参数或将其设置为`False`,`train`函数将启动新的训练会话。
|
||||
|
||||
请记住,默认情况下,检查点会在每个时期结束时保存,或者使用`save_period`参数以固定间隔保存,因此您必须至少完成1个时期才能恢复训练运行。
|
||||
|
||||
## 参数
|
||||
|
||||
YOLO模型的训练设置是指用于对数据集进行模型训练的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。一些常见的YOLO训练设置包括批大小、学习率、动量和权重衰减。其他可能影响训练过程的因素包括优化器的选择、损失函数的选择以及训练数据集的大小和组成。仔细调整和实验这些设置以实现给定任务的最佳性能是非常重要的。
|
||||
|
||||
| 键 | 值 | 描述 |
|
||||
|-------------------|----------|---------------------------------------------------------------------|
|
||||
| `model` | `None` | 模型文件路径,例如 yolov8n.pt, yolov8n.yaml |
|
||||
| `data` | `None` | 数据文件路径,例如 coco128.yaml |
|
||||
| `epochs` | `100` | 训练的轮次数量 |
|
||||
| `patience` | `50` | 早停训练的等待轮次 |
|
||||
| `batch` | `16` | 每批图像数量(-1为自动批大小) |
|
||||
| `imgsz` | `640` | 输入图像的大小,以整数表示 |
|
||||
| `save` | `True` | 保存训练检查点和预测结果 |
|
||||
| `save_period` | `-1` | 每x轮次保存检查点(如果<1则禁用) |
|
||||
| `cache` | `False` | True/ram, disk 或 False。使用缓存加载数据 |
|
||||
| `device` | `None` | 运行设备,例如 cuda device=0 或 device=0,1,2,3 或 device=cpu |
|
||||
| `workers` | `8` | 数据加载的工作线程数(如果DDP则为每个RANK) |
|
||||
| `project` | `None` | 项目名称 |
|
||||
| `name` | `None` | 实验名称 |
|
||||
| `exist_ok` | `False` | 是否覆盖现有实验 |
|
||||
| `pretrained` | `True` | (bool 或 str) 是否使用预训练模型(bool)或从中加载权重的模型(str) |
|
||||
| `optimizer` | `'auto'` | 使用的优化器,选择范围=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
|
||||
| `verbose` | `False` | 是否打印详细输出 |
|
||||
| `seed` | `0` | 随机种子,用于可重复性 |
|
||||
| `deterministic` | `True` | 是否启用确定性模式 |
|
||||
| `single_cls` | `False` | 将多类数据作为单类训练 |
|
||||
| `rect` | `False` | 矩形训练,每批为最小填充整合 |
|
||||
| `cos_lr` | `False` | 使用余弦学习率调度器 |
|
||||
| `close_mosaic` | `10` | (int) 最后轮次禁用马赛克增强(0为禁用) |
|
||||
| `resume` | `False` | 从最后检查点恢复训练 |
|
||||
| `amp` | `True` | 自动混合精度(AMP)训练,选择范围=[True, False] |
|
||||
| `fraction` | `1.0` | 训练的数据集比例(默认为1.0,即训练集中的所有图像) |
|
||||
| `profile` | `False` | 在训练期间为记录器分析ONNX和TensorRT速度 |
|
||||
| `freeze` | `None` | (int 或 list, 可选) 在训练期间冻结前n层,或冻结层索引列表 |
|
||||
| `lr0` | `0.01` | 初始学习率(例如 SGD=1E-2, Adam=1E-3) |
|
||||
| `lrf` | `0.01` | 最终学习率 (lr0 * lrf) |
|
||||
| `momentum` | `0.937` | SGD动量/Adam beta1 |
|
||||
| `weight_decay` | `0.0005` | 优化器权重衰减5e-4 |
|
||||
| `warmup_epochs` | `3.0` | 热身轮次(小数ok) |
|
||||
| `warmup_momentum` | `0.8` | 热身初始动量 |
|
||||
| `warmup_bias_lr` | `0.1` | 热身初始偏差lr |
|
||||
| `box` | `7.5` | 框损失增益 |
|
||||
| `cls` | `0.5` | cls损失增益(根据像素缩放) |
|
||||
| `dfl` | `1.5` | dfl损失增益 |
|
||||
| `pose` | `12.0` | 姿态损失增益(仅限姿态) |
|
||||
| `kobj` | `2.0` | 关键点obj损失增益(仅限姿态) |
|
||||
| `label_smoothing` | `0.0` | 标签平滑(小数) |
|
||||
| `nbs` | `64` | 标称批大小 |
|
||||
| `overlap_mask` | `True` | 训练期间掩码应重叠(仅限分割训练) |
|
||||
| `mask_ratio` | `4` | 掩码降采样比率(仅限分割训练) |
|
||||
| `dropout` | `0.0` | 使用dropout正则化(仅限分类训练) |
|
||||
| `val` | `True` | 训练期间验证/测试 |
|
||||
|
||||
## 记录
|
||||
|
||||
在训练YOLOv8模型时,跟踪模型随时间的性能变化可能非常有价值。这就是记录发挥作用的地方。Ultralytics的YOLO提供对三种类型记录器的支持 - Comet、ClearML和TensorBoard。
|
||||
|
||||
要使用记录器,请在上面的代码片段中的下拉菜单中选择它并运行。所选的记录器将被安装和初始化。
|
||||
|
||||
### Comet
|
||||
|
||||
[Comet](https://www.comet.ml/site/)是一个平台,允许数据科学家和开发人员跟踪、比较、解释和优化实验和模型。它提供了实时指标、代码差异和超参数跟踪等功能。
|
||||
|
||||
使用Comet:
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
# pip install comet_ml
|
||||
import comet_ml
|
||||
|
||||
comet_ml.init()
|
||||
```
|
||||
|
||||
记得在他们的网站上登录您的Comet账户并获取您的API密钥。您需要将此添加到您的环境变量或脚本中,以记录您的实验。
|
||||
|
||||
### ClearML
|
||||
|
||||
[ClearML](https://www.clear.ml/) 是一个开源平台,自动跟踪实验并帮助有效共享资源。它旨在帮助团队更有效地管理、执行和复现他们的ML工作。
|
||||
|
||||
使用ClearML:
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "Python"
|
||||
```python
|
||||
# pip install clearml
|
||||
import clearml
|
||||
|
||||
clearml.browser_login()
|
||||
```
|
||||
|
||||
运行此脚本后,您需要在浏览器中登录您的ClearML账户并认证您的会话。
|
||||
|
||||
### TensorBoard
|
||||
|
||||
[TensorBoard](https://www.tensorflow.org/tensorboard) 是TensorFlow的可视化工具包。它允许您可视化TensorFlow图表,绘制有关图表执行的定量指标,并展示通过它的附加数据,如图像。
|
||||
|
||||
在[Google Colab](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb)中使用TensorBoard:
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "CLI"
|
||||
```bash
|
||||
load_ext tensorboard
|
||||
tensorboard --logdir ultralytics/runs # 替换为'runs'目录
|
||||
```
|
||||
|
||||
在本地使用TensorBoard,运行下面的命令并在 http://localhost:6006/ 查看结果。
|
||||
|
||||
!!! 示例 ""
|
||||
|
||||
=== "CLI"
|
||||
```bash
|
||||
tensorboard --logdir ultralytics/runs # 替换为'runs'目录
|
||||
```
|
||||
|
||||
这将加载TensorBoard并将其定向到保存训练日志的目录。
|
||||
|
||||
在设置好日志记录器后,您可以继续进行模型训练。所有训练指标将自动记录在您选择的平台中,您可以访问这些日志以监控模型随时间的表现,比较不同模型,并识别改进的领域。
|
||||
86
docs/zh/modes/val.md
Normal file
86
docs/zh/modes/val.md
Normal file
|
|
@ -0,0 +1,86 @@
|
|||
---
|
||||
comments: true
|
||||
description: 指南 - 验证 YOLOv8 模型。了解如何使用验证设置和指标评估您的 YOLO 模型的性能,包括 Python 和 CLI 示例。
|
||||
keywords: Ultralytics, YOLO 文档, YOLOv8, 验证, 模型评估, 超参数, 准确率, 指标, Python, CLI
|
||||
---
|
||||
|
||||
# 使用 Ultralytics YOLO 进行模型验证
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO 生态系统和集成">
|
||||
|
||||
## 引言
|
||||
|
||||
在机器学习流程中,验证是一个关键步骤,让您能够评估训练模型的质量。Ultralytics YOLOv8 的 Val 模式提供了一整套强大的工具和指标,用于评估您的目标检测模型的性能。本指南作为一个完整资源,用于理解如何有效使用 Val 模式来确保您的模型既准确又可靠。
|
||||
|
||||
## 为什么要使用 Ultralytics YOLO 进行验证?
|
||||
|
||||
以下是使用 YOLOv8 的 Val 模式的好处:
|
||||
|
||||
- **精确性:** 获取准确的指标,如 mAP50、mAP75 和 mAP50-95,全面评估您的模型。
|
||||
- **便利性:** 利用内置功能记住训练设置,简化验证过程。
|
||||
- **灵活性:** 使用相同或不同的数据集和图像尺寸验证您的模型。
|
||||
- **超参数调优:** 使用验证指标来调整您的模型以获得更好的性能。
|
||||
|
||||
### Val 模式的主要特点
|
||||
|
||||
以下是 YOLOv8 的 Val 模式提供的显著功能:
|
||||
|
||||
- **自动化设置:** 模型记住其训练配置,以便直接进行验证。
|
||||
- **多指标支持:** 根据一系列准确度指标评估您的模型。
|
||||
- **CLI 和 Python API:** 根据您的验证偏好选择命令行界面或 Python API。
|
||||
- **数据兼容性:** 与训练阶段使用的数据集以及自定义数据集无缝协作。
|
||||
|
||||
!!! tip "提示"
|
||||
|
||||
* YOLOv8 模型会自动记住其训练设置,因此您可以很容易地仅使用 `yolo val model=yolov8n.pt` 或 `model('yolov8n.pt').val()` 在原始数据集上并以相同图像大小验证模型。
|
||||
|
||||
## 使用示例
|
||||
|
||||
在 COCO128 数据集上验证训练过的 YOLOv8n 模型的准确性。由于 `model` 保留了其训练的 `data` 和参数作为模型属性,因此无需传递任何参数。有关完整的导出参数列表,请参阅下面的参数部分。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义模型
|
||||
|
||||
# 验证模型
|
||||
metrics = model.val() # 无需参数,数据集和设置记忆
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # 包含每个类别的map50-95列表
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect val model=yolov8n.pt # 验证官方模型
|
||||
yolo detect val model=path/to/best.pt # 验证自定义模型
|
||||
```
|
||||
|
||||
## 参数
|
||||
|
||||
YOLO 模型的验证设置是指用于评估模型在验证数据集上性能的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。一些常见的 YOLO 验证设置包括批处理大小、在训练期间验证频率以及用于评估模型性能的指标。其他可能影响验证过程的因素包括验证数据集的大小和组成以及模型用于特定任务的特性。仔细调整和实验这些设置很重要,以确保模型在验证数据集上表现良好并且检测和预防过拟合。
|
||||
|
||||
| 键 | 值 | 描述 |
|
||||
|---------------|---------|---------------------------------------------|
|
||||
| `data` | `None` | 数据文件的路径,例如 coco128.yaml |
|
||||
| `imgsz` | `640` | 输入图像的大小,以整数表示 |
|
||||
| `batch` | `16` | 每批图像的数量(AutoBatch 为 -1) |
|
||||
| `save_json` | `False` | 将结果保存至 JSON 文件 |
|
||||
| `save_hybrid` | `False` | 保存混合版本的标签(标签 + 额外预测) |
|
||||
| `conf` | `0.001` | 用于检测的对象置信度阈值 |
|
||||
| `iou` | `0.6` | NMS(非极大抑制)用的交并比(IoU)阈值 |
|
||||
| `max_det` | `300` | 每张图像的最大检测数量 |
|
||||
| `half` | `True` | 使用半精度(FP16) |
|
||||
| `device` | `None` | 运行所用的设备,例如 cuda device=0/1/2/3 或 device=cpu |
|
||||
| `dnn` | `False` | 使用 OpenCV DNN 进行 ONNX 推理 |
|
||||
| `plots` | `False` | 在训练期间显示图表 |
|
||||
| `rect` | `False` | 矩形验证,每批图像为了最小填充整齐排列 |
|
||||
| `split` | `val` | 用于验证的数据集分割,例如 'val'、'test' 或 'train' |
|
||||
|
|
||||
314
docs/zh/quickstart.md
Normal file
314
docs/zh/quickstart.md
Normal file
|
|
@ -0,0 +1,314 @@
|
|||
---
|
||||
评论:真
|
||||
描述:探索使用pip、conda、git和Docker安装Ultralytics的各种方法。了解如何在命令行界面或Python项目中使用Ultralytics。
|
||||
关键字:Ultralytics安装,pip安装Ultralytics,Docker安装Ultralytics,Ultralytics命令行界面,Ultralytics Python接口
|
||||
---
|
||||
|
||||
## 安装Ultralytics
|
||||
|
||||
Ultralytics提供了多种安装方法,包括pip、conda和Docker。通过`ultralytics`pip包安装最新稳定版的YOLOv8,或者克隆[Ultralytics GitHub仓库](https://github.com/ultralytics/ultralytics)以获取最新版本。Docker可用于在隔离容器中执行包,避免本地安装。
|
||||
|
||||
!!! 示例 "安装"
|
||||
|
||||
=== "Pip安装(推荐)"
|
||||
使用pip安装`ultralytics`包,或通过运行`pip install -U ultralytics`更新现有安装。访问Python包索引(PyPI)了解更多关于`ultralytics`包的详细信息:[https://pypi.org/project/ultralytics/](https://pypi.org/project/ultralytics/)。
|
||||
|
||||
[](https://badge.fury.io/py/ultralytics) [](https://pepy.tech/project/ultralytics)
|
||||
|
||||
```bash
|
||||
# 从PyPI安装ultralytics包
|
||||
pip install ultralytics
|
||||
```
|
||||
|
||||
你也可以直接从GitHub[仓库](https://github.com/ultralytics/ultralytics)安装`ultralytics`包。如果你想要最新的开发版本,这可能会很有用。确保你的系统上安装了Git命令行工具。`@main`指令安装`main`分支,可修改为其他分支,如`@my-branch`,或完全删除,默认为`main`分支。
|
||||
|
||||
```bash
|
||||
# 从GitHub安装ultralytics包
|
||||
pip install git+https://github.com/ultralytics/ultralytics.git@main
|
||||
```
|
||||
|
||||
|
||||
=== "Conda安装"
|
||||
Conda是pip的一个替代包管理器,也可用于安装。访问Anaconda了解更多详情,网址为[https://anaconda.org/conda-forge/ultralytics](https://anaconda.org/conda-forge/ultralytics)。用于更新conda包的Ultralytics feedstock仓库位于[https://github.com/conda-forge/ultralytics-feedstock/](https://github.com/conda-forge/ultralytics-feedstock/)。
|
||||
|
||||
|
||||
[](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics) [](https://anaconda.org/conda-forge/ultralytics)
|
||||
|
||||
```bash
|
||||
# 使用conda安装ultralytics包
|
||||
conda install -c conda-forge ultralytics
|
||||
```
|
||||
|
||||
!!! 注意
|
||||
|
||||
如果你在CUDA环境中安装,最佳实践是同时安装`ultralytics`、`pytorch`和`pytorch-cuda`,以便conda包管理器解决任何冲突,或者最后安装`pytorch-cuda`,让它必要时覆盖特定于CPU的`pytorch`包。
|
||||
```bash
|
||||
# 使用conda一起安装所有包
|
||||
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
|
||||
```
|
||||
|
||||
### Conda Docker映像
|
||||
|
||||
Ultralytics Conda Docker映像也可从[DockerHub](https://hub.docker.com/r/ultralytics/ultralytics)获得。这些映像基于[Miniconda3](https://docs.conda.io/projects/miniconda/en/latest/),是开始在Conda环境中使用`ultralytics`的简单方式。
|
||||
|
||||
```bash
|
||||
# 将映像名称设置为变量
|
||||
t=ultralytics/ultralytics:latest-conda
|
||||
|
||||
# 从Docker Hub拉取最新的ultralytics映像
|
||||
sudo docker pull $t
|
||||
|
||||
# 使用GPU支持运行ultralytics映像的容器
|
||||
sudo docker run -it --ipc=host --gpus all $t # 所有GPU
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # 指定GPU
|
||||
```
|
||||
|
||||
=== "Git克隆"
|
||||
如果您对参与开发感兴趣或希望尝试最新源代码,请克隆`ultralytics`仓库。克隆后,导航到目录并使用pip以可编辑模式`-e`安装包。
|
||||
```bash
|
||||
# 克隆ultralytics仓库
|
||||
git clone https://github.com/ultralytics/ultralytics
|
||||
|
||||
# 导航到克隆的目录
|
||||
cd ultralytics
|
||||
|
||||
# 为开发安装可编辑模式下的包
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
=== "Docker"
|
||||
|
||||
利用Docker轻松地在隔离的容器中执行`ultralytics`包,确保跨不同环境的一致性和流畅性能。通过选择一款官方`ultralytics`映像,从[Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics)中不仅避免了本地安装的复杂性,还获得了对验证工作环境的访问。Ultralytics提供5种主要支持的Docker映像,每一种都为不同的平台和使用案例设计,以提供高兼容性和效率:
|
||||
|
||||
<a href="https://hub.docker.com/r/ultralytics/ultralytics"><img src="https://img.shields.io/docker/pulls/ultralytics/ultralytics?logo=docker" alt="Docker拉取次数"></a>
|
||||
|
||||
- **Dockerfile:** 推荐用于训练的GPU映像。
|
||||
- **Dockerfile-arm64:** 为ARM64架构优化,允许在树莓派和其他基于ARM64的平台上部署。
|
||||
- **Dockerfile-cpu:** 基于Ubuntu的CPU版,适合无GPU环境下的推理。
|
||||
- **Dockerfile-jetson:** 为NVIDIA Jetson设备量身定制,整合了针对这些平台优化的GPU支持。
|
||||
- **Dockerfile-python:** 最小化映像,只包含Python及必要依赖,理想于轻量级应用和开发。
|
||||
- **Dockerfile-conda:** 基于Miniconda3,包含conda安装的ultralytics包。
|
||||
|
||||
以下是获取最新映像并执行它的命令:
|
||||
|
||||
```bash
|
||||
# 将映像名称设置为变量
|
||||
t=ultralytics/ultralytics:latest
|
||||
|
||||
# 从Docker Hub拉取最新的ultralytics映像
|
||||
sudo docker pull $t
|
||||
|
||||
# 使用GPU支持运行ultralytics映像的容器
|
||||
sudo docker run -it --ipc=host --gpus all $t # 所有GPU
|
||||
sudo docker run -it --ipc=host --gpus '"device=2,3"' $t # 指定GPU
|
||||
```
|
||||
|
||||
上述命令初始化了一个带有最新`ultralytics`映像的Docker容器。`-it`标志分配了一个伪TTY,并保持stdin打开,使您可以与容器交互。`--ipc=host`标志将IPC(进程间通信)命名空间设置为宿主,这对于进程之间的内存共享至关重要。`--gpus all`标志使容器内可以访问所有可用的GPU,这对于需要GPU计算的任务至关重要。
|
||||
|
||||
注意:要在容器中使用本地机器上的文件,请使用Docker卷将本地目录挂载到容器中:
|
||||
|
||||
```bash
|
||||
# 将本地目录挂载到容器内的目录
|
||||
sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
|
||||
```
|
||||
|
||||
将`/path/on/host`更改为您本地机器上的目录路径,将`/path/in/container`更改为Docker容器内希望访问的路径。
|
||||
|
||||
欲了解进阶Docker使用方法,请探索[Ultralytics Docker指南](https://docs.ultralytics.com/guides/docker-quickstart/)。
|
||||
|
||||
有关依赖项列表,请参见`ultralytics`的[requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt)文件。请注意,上述所有示例均安装了所有必需的依赖项。
|
||||
|
||||
!!! 提示 "提示"
|
||||
|
||||
PyTorch的要求因操作系统和CUDA需要而异,因此建议首先根据[https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally)上的指南安装PyTorch。
|
||||
|
||||
<a href="https://pytorch.org/get-started/locally/">
|
||||
<img width="800" alt="PyTorch安装指南" src="https://user-images.githubusercontent.com/26833433/228650108-ab0ec98a-b328-4f40-a40d-95355e8a84e3.png">
|
||||
</a>
|
||||
|
||||
## 通过CLI使用Ultralytics
|
||||
|
||||
Ultralytics命令行界面(CLI)允许您通过简单的单行命令使用,无需Python环境。CLI不需要自定义或Python代码。您可以直接从终端使用`yolo`命令运行所有任务。查看[CLI指南](/../usage/cli.md),了解更多关于从命令行使用YOLOv8的信息。
|
||||
|
||||
!!! 示例
|
||||
|
||||
=== "语法"
|
||||
|
||||
Ultralytics `yolo`命令使用以下语法:
|
||||
```bash
|
||||
yolo 任务 模式 参数
|
||||
|
||||
其中 任务(可选)是[detect, segment, classify]中的一个
|
||||
模式(必需)是[train, val, predict, export, track]中的一个
|
||||
参数(可选)是任意数量的自定义“arg=value”对,如“imgsz=320”,可覆盖默认值。
|
||||
```
|
||||
在完整的[配置指南](/../usage/cfg.md)中查看所有参数,或者用`yolo cfg`查看
|
||||
|
||||
=== "训练"
|
||||
|
||||
用初始学习率0.01训练检测模型10个周期
|
||||
```bash
|
||||
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
|
||||
```
|
||||
|
||||
=== "预测"
|
||||
|
||||
使用预训练的分割模型以320的图像大小预测YouTube视频:
|
||||
```bash
|
||||
yolo predict model=yolov8n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320
|
||||
```
|
||||
|
||||
=== "验证"
|
||||
|
||||
以批量大小1和640的图像大小验证预训练的检测模型:
|
||||
```bash
|
||||
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
|
||||
```
|
||||
|
||||
=== "导出"
|
||||
|
||||
以224x128的图像大小将YOLOv8n分类模型导出到ONNX格式(无需任务)
|
||||
```bash
|
||||
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
|
||||
```
|
||||
|
||||
=== "特殊"
|
||||
|
||||
运行特殊命令以查看版本、查看设置、运行检查等:
|
||||
```bash
|
||||
yolo help
|
||||
yolo checks
|
||||
yolo version
|
||||
yolo settings
|
||||
yolo copy-cfg
|
||||
yolo cfg
|
||||
```
|
||||
|
||||
!!! 警告 "警告"
|
||||
|
||||
参数必须以`arg=val`对的形式传递,用等号`=`分隔,并用空格` `分隔对。不要使用`--`参数前缀或逗号`,`分隔参数。
|
||||
|
||||
- `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
|
||||
- `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
|
||||
- `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
|
||||
|
||||
[CLI指南](/../usage/cli.md){ .md-button .md-button--primary}
|
||||
|
||||
## 通过Python使用Ultralytics
|
||||
|
||||
YOLOv8的Python接口允许无缝集成进您的Python项目,轻松加载、运行模型及处理输出。Python接口设计简洁易用,使用户能快速实现他们项目中的目标检测、分割和分类功能。这使YOLOv8的Python接口成为任何希望在其Python项目中纳入这些功能的人的宝贵工具。
|
||||
|
||||
例如,用户可以加载一个模型,训练它,在验证集上评估性能,甚至只需几行代码就可以将其导出到ONNX格式。查看[Python指南](/../usage/python.md),了解更多关于在Python项目中使用YOLOv8的信息。
|
||||
|
||||
!!! 示例
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 从头开始创建一个新的YOLO模型
|
||||
model = YOLO('yolov8n.yaml')
|
||||
|
||||
# 加载预训练的YOLO模型(推荐用于训练)
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# 使用“coco128.yaml”数据集训练模型3个周期
|
||||
results = model.train(data='coco128.yaml', epochs=3)
|
||||
|
||||
# 评估模型在验证集上的性能
|
||||
results = model.val()
|
||||
|
||||
# 使用模型对图片进行目标检测
|
||||
results = model('https://ultralytics.com/images/bus.jpg')
|
||||
|
||||
# 将模型导出为ONNX格式
|
||||
success = model.export(format='onnx')
|
||||
```
|
||||
|
||||
[Python指南](/../usage/python.md){.md-button .md-button--primary}
|
||||
|
||||
## Ultralytics设置
|
||||
|
||||
Ultralytics库提供了一个强大的设置管理系统,允许您精细控制实验。通过利用`ultralytics.utils`模块中的`SettingsManager`,用户可以轻松访问和修改设置。这些设置存储在YAML文件中,可以直接在Python环境中查看或修改,或者通过命令行界面(CLI)修改。
|
||||
|
||||
### 检查设置
|
||||
|
||||
若要了解当前设置的配置情况,您可以直接查看:
|
||||
|
||||
!!! 示例 "查看设置"
|
||||
|
||||
=== "Python"
|
||||
您可以使用Python查看设置。首先从`ultralytics`模块导入`settings`对象。使用以下命令打印和返回设置:
|
||||
```python
|
||||
from ultralytics import settings
|
||||
|
||||
# 查看所有设置
|
||||
print(settings)
|
||||
|
||||
# 返回特定设置
|
||||
value = settings['runs_dir']
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
或者,命令行界面允许您用一个简单的命令检查您的设置:
|
||||
```bash
|
||||
yolo settings
|
||||
```
|
||||
|
||||
### 修改设置
|
||||
|
||||
Ultralytics允许用户轻松修改他们的设置。更改可以通过以下方式执行:
|
||||
|
||||
!!! 示例 "更新设置"
|
||||
|
||||
=== "Python"
|
||||
在Python环境中,调用`settings`对象上的`update`方法来更改您的设置:
|
||||
```python
|
||||
from ultralytics import settings
|
||||
|
||||
# 更新一个设置
|
||||
settings.update({'runs_dir': '/path/to/runs'})
|
||||
|
||||
# 更新多个设置
|
||||
settings.update({'runs_dir': '/path/to/runs', 'tensorboard': False})
|
||||
|
||||
# 重置设置为默认值
|
||||
settings.reset()
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
如果您更喜欢使用命令行界面,以下命令将允许您修改设置:
|
||||
```bash
|
||||
# 更新一个设置
|
||||
yolo settings runs_dir='/path/to/runs'
|
||||
|
||||
# 更新多个设置
|
||||
yolo settings runs_dir='/path/to/runs' tensorboard=False
|
||||
|
||||
# 重置设置为默认值
|
||||
yolo settings reset
|
||||
```
|
||||
|
||||
### 理解设置
|
||||
|
||||
下表提供了Ultralytics中可调整设置的概览。每个设置都概述了一个示例值、数据类型和简短描述。
|
||||
|
||||
| 名称 | 示例值 | 数据类型 | 描述 |
|
||||
|--------------------|-----------------------|--------|------------------------------------------------------------------------------------------|
|
||||
| `settings_version` | `'0.0.4'` | `str` | Ultralytics _settings_ 版本(不同于Ultralytics [pip](https://pypi.org/project/ultralytics/)版本) |
|
||||
| `datasets_dir` | `'/path/to/datasets'` | `str` | 存储数据集的目录 |
|
||||
| `weights_dir` | `'/path/to/weights'` | `str` | 存储模型权重的目录 |
|
||||
| `runs_dir` | `'/path/to/runs'` | `str` | 存储实验运行的目录 |
|
||||
| `uuid` | `'a1b2c3d4'` | `str` | 当前设置的唯一标识符 |
|
||||
| `sync` | `True` | `bool` | 是否将分析和崩溃同步到HUB |
|
||||
| `api_key` | `''` | `str` | Ultralytics HUB [API Key](https://hub.ultralytics.com/settings?tab=api+keys) |
|
||||
| `clearml` | `True` | `bool` | 是否使用ClearML记录 |
|
||||
| `comet` | `True` | `bool` | 是否使用[Comet ML](https://bit.ly/yolov8-readme-comet)进行实验跟踪和可视化 |
|
||||
| `dvc` | `True` | `bool` | 是否使用[DVC进行实验跟踪](https://dvc.org/doc/dvclive/ml-frameworks/yolo)和版本控制 |
|
||||
| `hub` | `True` | `bool` | 是否使用[Ultralytics HUB](https://hub.ultralytics.com)集成 |
|
||||
| `mlflow` | `True` | `bool` | 是否使用MLFlow进行实验跟踪 |
|
||||
| `neptune` | `True` | `bool` | 是否使用Neptune进行实验跟踪 |
|
||||
| `raytune` | `True` | `bool` | 是否使用Ray Tune进行超参数调整 |
|
||||
| `tensorboard` | `True` | `bool` | 是否使用TensorBoard进行可视化 |
|
||||
| `wandb` | `True` | `bool` | 是否使用Weights & Biases记录 |
|
||||
|
||||
在您浏览项目或实验时,请务必重新访问这些设置,以确保它们为您的需求提供最佳配置。
|
||||
172
docs/zh/tasks/classify.md
Normal file
172
docs/zh/tasks/classify.md
Normal file
|
|
@ -0,0 +1,172 @@
|
|||
---
|
||||
comments: true
|
||||
description: 学习YOLOv8分类模型进行图像分类。获取关于预训练模型列表及如何训练、验证、预测、导出模型的详细信息。
|
||||
keywords: Ultralytics, YOLOv8, 图像分类, 预训练模型, YOLOv8n-cls, 训练, 验证, 预测, 模型导出
|
||||
---
|
||||
|
||||
# 图像分类
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418606-adf35c62-2e11-405d-84c6-b84e7d013804.png" alt="图像分类示例">
|
||||
|
||||
图像分类是三项任务中最简单的,它涉及将整个图像分类为一组预定义类别中的一个。
|
||||
|
||||
图像分类器的输出是单个类别标签和一个置信度分数。当您只需要知道一幅图像属于哪个类别、而不需要知道该类别对象的位置或它们的确切形状时,图像分类非常有用。
|
||||
|
||||
!!! tip "提示"
|
||||
|
||||
YOLOv8分类模型使用`-cls`后缀,即`yolov8n-cls.pt`,并预先训练在[ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml)上。
|
||||
|
||||
## [模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
这里展示了预训练的YOLOv8分类模型。Detect、Segment和Pose模型是在[COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)数据集上预训练的,而分类模型则是在[ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml)数据集上预训练的。
|
||||
|
||||
[模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models)会在首次使用时自动从Ultralytics的最新[发布版本](https://github.com/ultralytics/assets/releases)中下载。
|
||||
|
||||
| 模型 | 尺寸<br><sup>(像素) | 准确率<br><sup>top1 | 准确率<br><sup>top5 | 速度<br><sup>CPU ONNX<br>(ms) | 速度<br><sup>A100 TensorRT<br>(ms) | 参数<br><sup>(M) | FLOPs<br><sup>(B) at 640 |
|
||||
|----------------------------------------------------------------------------------------------|-----------------|------------------|------------------|-----------------------------|----------------------------------|----------------|--------------------------|
|
||||
| [YOLOv8n-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-cls.pt) | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
|
||||
| [YOLOv8s-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-cls.pt) | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
|
||||
| [YOLOv8m-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-cls.pt) | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
|
||||
| [YOLOv8l-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-cls.pt) | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
|
||||
| [YOLOv8x-cls](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-cls.pt) | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
|
||||
|
||||
- **准确率** 是模型在[ImageNet](https://www.image-net.org/)数据集验证集上的准确度。
|
||||
<br>通过`yolo val classify data=path/to/ImageNet device=0`复现结果。
|
||||
- **速度** 是在使用[Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)实例时,ImageNet验证图像的平均处理速度。
|
||||
<br>通过`yolo val classify data=path/to/ImageNet batch=1 device=0|cpu`复现结果。
|
||||
|
||||
## 训练
|
||||
|
||||
在MNIST160数据集上训练YOLOv8n-cls模型100个时期,图像尺寸为64。有关可用参数的完整列表,请参见[配置](/../usage/cfg.md)页面。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n-cls.yaml') # 从YAML构建新模型
|
||||
model = YOLO('yolov8n-cls.pt') # 加载预训练模型(推荐用于训练)
|
||||
model = YOLO('yolov8n-cls.yaml').load('yolov8n-cls.pt') # 从YAML构建并转移权重
|
||||
|
||||
# 训练模型
|
||||
results = model.train(data='mnist160', epochs=100, imgsz=64)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 从YAML构建新模型并从头开始训练
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.yaml epochs=100 imgsz=64
|
||||
|
||||
# 从预训练的*.pt模型开始训练
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.pt epochs=100 imgsz=64
|
||||
|
||||
# 从YAML构建新模型,转移预训练权重并开始训练
|
||||
yolo classify train data=mnist160 model=yolov8n-cls.yaml pretrained=yolov8n-cls.pt epochs=100 imgsz=64
|
||||
```
|
||||
|
||||
### 数据集格式
|
||||
|
||||
YOLO分类数据集的格式详情请参见[数据集指南](/../datasets/classify/index.md)。
|
||||
|
||||
## 验证
|
||||
|
||||
在MNIST160数据集上验证训练好的YOLOv8n-cls模型准确性。不需要传递任何参数,因为`model`保留了它的训练`data`和参数作为模型属性。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n-cls.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义模型
|
||||
|
||||
# 验证模型
|
||||
metrics = model.val() # 无需参数,数据集和设置已记忆
|
||||
metrics.top1 # top1准确率
|
||||
metrics.top5 # top5准确率
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo classify val model=yolov8n-cls.pt # 验证官方模型
|
||||
yolo classify val model=path/to/best.pt # 验证自定义模型
|
||||
```
|
||||
|
||||
## 预测
|
||||
|
||||
使用训练过的YOLOv8n-cls模型对图像进行预测。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n-cls.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义模型
|
||||
|
||||
# 使用模型进行预测
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # 对图像进行预测
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo classify predict model=yolov8n-cls.pt source='https://ultralytics.com/images/bus.jpg' # 使用官方模型进行预测
|
||||
yolo classify predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # 使用自定义模型进行预测
|
||||
```
|
||||
|
||||
有关`predict`模式的完整详细信息,请参见[预测](https://docs.ultralytics.com/modes/predict/)页面。
|
||||
|
||||
## 导出
|
||||
|
||||
将YOLOv8n-cls模型导出为其他格式,如ONNX、CoreML等。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n-cls.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义训练模型
|
||||
|
||||
# 导出模型
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-cls.pt format=onnx # 导出官方模型
|
||||
yolo export model=path/to/best.pt format=onnx # 导出自定义训练模型
|
||||
```
|
||||
|
||||
下表中提供了YOLOv8-cls模型可导出的格式。您可以直接在导出的模型上进行预测或验证,即`yolo predict model=yolov8n-cls.onnx`。导出完成后,示例用法会显示您的模型。
|
||||
|
||||
| 格式 | `format` 参数 | 模型 | 元数据 | 参数 |
|
||||
|--------------------------------------------------------------------|---------------|-------------------------------|-----|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-cls.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-cls.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-cls.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-cls_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-cls.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-cls.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-cls_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-cls.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-cls.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-cls_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-cls_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-cls_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-cls_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
有关`export`的完整详细信息,请参见[导出](https://docs.ultralytics.com/modes/export/)页面。
|
||||
184
docs/zh/tasks/detect.md
Normal file
184
docs/zh/tasks/detect.md
Normal file
|
|
@ -0,0 +1,184 @@
|
|||
---
|
||||
comments: true
|
||||
description: Ultralytics 官方YOLOv8文档。学习如何训练、验证、预测并以各种格式导出模型。包括详尽的性能统计。
|
||||
keywords: YOLOv8, Ultralytics, 目标检测, 预训练模型, 训练, 验证, 预测, 导出模型, COCO, ImageNet, PyTorch, ONNX, CoreML
|
||||
---
|
||||
|
||||
# 目标检测
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418624-5785cb93-74c9-4541-9179-d5c6782d491a.png" alt="目标检测示例">
|
||||
|
||||
目标检测是一项任务,涉及辨识图像或视频流中物体的位置和类别。
|
||||
|
||||
目标检测器的输出是一组围绕图像中物体的边界框,以及每个框的类别标签和置信度得分。当您需要识别场景中的感兴趣对象,但不需要准确了解物体的位置或其确切形状时,目标检测是一个很好的选择。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/5ku7npMrW40?si=6HQO1dDXunV8gekh"
|
||||
title="YouTube视频播放器" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong>使用预训练的Ultralytics YOLOv8模型进行目标检测。
|
||||
</p>
|
||||
|
||||
!!! tip "提示"
|
||||
|
||||
YOLOv8 Detect 模型是默认的 YOLOv8 模型,即 `yolov8n.pt` ,并在 [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml) 数据集上进行了预训练。
|
||||
|
||||
## [模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
此处展示了预训练的YOLOv8 Detect模型。Detect、Segment和Pose模型在 [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml) 数据集上预训练,而Classify模型在 [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml) 数据集上预训练。
|
||||
|
||||
[模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) 会在首次使用时自动从Ultralytics的最新 [发布](https://github.com/ultralytics/assets/releases) 中下载。
|
||||
|
||||
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>val<br>50-95 | 速度<br><sup>CPU ONNX<br>(毫秒) | 速度<br><sup>A100 TensorRT<br>(毫秒) | 参数<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
|--------------------------------------------------------------------------------------|-----------------|----------------------|-----------------------------|----------------------------------|----------------|-------------------|
|
||||
| [YOLOv8n](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt) | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
|
||||
| [YOLOv8s](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt) | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
|
||||
| [YOLOv8m](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt) | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
|
||||
| [YOLOv8l](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt) | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
|
||||
| [YOLOv8x](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt) | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
|
||||
|
||||
- **mAP<sup>val</sup>** 值适用于 [COCO val2017](http://cocodataset.org) 数据集上的单模型单尺度。
|
||||
<br>通过 `yolo val detect data=coco.yaml device=0` 复现。
|
||||
- **速度** 是在使用 [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) 云实例对COCO val图像的平均值。
|
||||
<br>通过 `yolo val detect data=coco128.yaml batch=1 device=0|cpu` 复现。
|
||||
|
||||
## 训练
|
||||
|
||||
在COCO128数据集上使用图像尺寸640将YOLOv8n训练100个epochs。要查看可用参数的完整列表,请参阅 [配置](/../usage/cfg.md) 页面。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.yaml') # 从YAML构建新模型
|
||||
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
|
||||
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML构建并转移权重
|
||||
|
||||
# 训练模型
|
||||
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 从YAML构建新模型并从头开始训练
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||
|
||||
# 从预训练的*.pt模型开始训练
|
||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
|
||||
# 从YAML构建新模型,传递预训练权重并开始训练
|
||||
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### 数据集格式
|
||||
|
||||
YOLO检测数据集格式可以在 [数据集指南](/../datasets/detect/index.md) 中详细找到。要将您现有的数据集从其他格式(如COCO等)转换为YOLO格式,请使用Ultralytics的 [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO) 工具。
|
||||
|
||||
## 验证
|
||||
|
||||
在COCO128数据集上验证训练好的YOLOv8n模型准确性。无需传递参数,`model` 作为模型属性保留其训练的 `data` 和参数。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义模型
|
||||
|
||||
# 验证模型
|
||||
metrics = model.val() # 无需参数,数据集和设置通过模型属性记住
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # 包含每个类别map50-95的列表
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect val model=yolov8n.pt # 验证官方模型
|
||||
yolo detect val model=path/to/best.pt # 验证自定义模型
|
||||
```
|
||||
|
||||
## 预测
|
||||
|
||||
使用训练好的YOLOv8n模型在图像上进行预测。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义模型
|
||||
|
||||
# 使用模型进行预测
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # 对图像进行预测
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # 使用官方模型进行预测
|
||||
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # 使用自定义模型进行预测
|
||||
```
|
||||
|
||||
完整的 `predict` 模式细节请见 [预测](https://docs.ultralytics.com/modes/predict/) 页面。
|
||||
|
||||
## 导出
|
||||
|
||||
将YOLOv8n模型导出为ONNX、CoreML等不同格式。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义训练模型
|
||||
|
||||
# 导出模型
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n.pt format=onnx # 导出官方模型
|
||||
yolo export model=path/to/best.pt format=onnx # 导出自定义训练模型
|
||||
```
|
||||
|
||||
下表中提供了可用的YOLOv8导出格式。您可以直接在导出的模型上进行预测或验证,即 `yolo predict model=yolov8n.onnx`。导出完成后,会为您的模型显示使用示例。
|
||||
|
||||
| 格式 | `format` 参数 | 模型 | 元数据 | 参数 |
|
||||
|--------------------------------------------------------------------|---------------|---------------------------|-----|-------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ | `imgsz`,`optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ | `imgsz`,`half`,`dynamic`,`simplify`,`opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ | `imgsz`,`half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ | `imgsz`,`half`,`dynamic`,`simplify`,`workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlpackage` | ✅ | `imgsz`,`half`,`int8`,`nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ | `imgsz`,`keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`,`half`,`int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`,`half` |
|
||||
|
||||
完整的 `export` 详情请见 [导出](https://docs.ultralytics.com/modes/export/) 页面。
|
||||
51
docs/zh/tasks/index.md
Normal file
51
docs/zh/tasks/index.md
Normal file
|
|
@ -0,0 +1,51 @@
|
|||
---
|
||||
comments: true
|
||||
description: 了解 YOLOv8 能够执行的基础计算机视觉任务,包括检测、分割、分类和姿态估计。理解它们在你的 AI 项目中的应用。
|
||||
keywords: Ultralytics, YOLOv8, 检测, 分割, 分类, 姿态估计, AI 框架, 计算机视觉任务
|
||||
---
|
||||
|
||||
# Ultralytics YOLOv8 任务
|
||||
|
||||
<br>
|
||||
<img width="1024" src="https://raw.githubusercontent.com/ultralytics/assets/main/im/banner-tasks.png" alt="Ultralytics YOLO 支持的任务">
|
||||
|
||||
YOLOv8 是一个支持多种计算机视觉**任务**的 AI 框架。该框架可用于执行[检测](detect.md)、[分割](segment.md)、[分类](classify.md)和[姿态](pose.md)估计。每项任务都有不同的目标和用例。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/NAs-cfq9BDw"
|
||||
title="YouTube 视频播放器" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong>探索 Ultralytics YOLO 任务:对象检测、分割、追踪和姿态估计。
|
||||
</p>
|
||||
|
||||
## [检测](detect.md)
|
||||
|
||||
检测是 YOLOv8 支持的主要任务。它涉及在图像或视频帧中检测对象并围绕它们绘制边界框。侦测到的对象根据其特征被归类到不同的类别。YOLOv8 能够在单个图像或视频帧中检测多个对象,具有高准确性和速度。
|
||||
|
||||
[检测示例](detect.md){ .md-button .md-button--primary}
|
||||
|
||||
## [分割](segment.md)
|
||||
|
||||
分割是一项涉及将图像分割成基于图像内容的不同区域的任务。每个区域根据其内容被分配一个标签。该任务在应用程序中非常有用,如图像分割和医学成像。YOLOv8 使用 U-Net 架构的变体来执行分割。
|
||||
|
||||
[分割示例](segment.md){ .md-button .md-button--primary}
|
||||
|
||||
## [分类](classify.md)
|
||||
|
||||
分类是一项涉及将图像归类为不同类别的任务。YOLOv8 可用于根据图像内容对图像进行分类。它使用 EfficientNet 架构的变体来执行分类。
|
||||
|
||||
[分类示例](classify.md){ .md-button .md-button--primary}
|
||||
|
||||
## [姿态](pose.md)
|
||||
|
||||
姿态/关键点检测是一项涉及在图像或视频帧中检测特定点的任务。这些点被称为关键点,用于跟踪移动或姿态估计。YOLOv8 能够在图像或视频帧中准确迅速地检测关键点。
|
||||
|
||||
[姿态示例](pose.md){ .md-button .md-button--primary}
|
||||
|
||||
## 结论
|
||||
|
||||
YOLOv8 支持多个任务,包括检测、分割、分类和关键点检测。这些任务都具有不同的目标和用例。通过理解这些任务之间的差异,您可以为您的计算机视觉应用选择合适的任务。
|
||||
185
docs/zh/tasks/pose.md
Normal file
185
docs/zh/tasks/pose.md
Normal file
|
|
@ -0,0 +1,185 @@
|
|||
---
|
||||
评论:真
|
||||
描述:学习如何使用Ultralytics YOLOv8进行姿态估计任务。找到预训练模型,学习如何训练、验证、预测以及导出你自己的模型。
|
||||
关键词:Ultralytics, YOLO, YOLOv8, 姿态估计, 关键点检测, 物体检测, 预训练模型, 机器学习, 人工智能
|
||||
---
|
||||
|
||||
# 姿态估计
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418616-9811ac0b-a4a7-452a-8aba-484ba32bb4a8.png" alt="姿态估计示例">
|
||||
|
||||
姿态估计是一项任务,其涉及识别图像中特定点的位置,通常被称为关键点。这些关键点可以代表物体的各种部位,如关节、地标或其他显著特征。关键点的位置通常表示为一组2D `[x, y]` 或3D `[x, y, visible]` 坐标。
|
||||
|
||||
姿态估计模型的输出是一组点集,这些点代表图像中物体上的关键点,通常还包括每个点的置信度得分。当你需要在场景中识别物体的特定部位及其相互之间的位置时,姿态估计是一个不错的选择。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/Y28xXQmju64?si=pCY4ZwejZFu6Z4kZ"
|
||||
title="YouTube视频播放器" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
允许全屏>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong>使用Ultralytics YOLOv8进行姿态估计。
|
||||
</p>
|
||||
|
||||
!!! tip "提示"
|
||||
|
||||
YOLOv8 _姿态_ 模型使用 `-pose` 后缀,例如 `yolov8n-pose.pt`。这些模型在 [COCO关键点](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco-pose.yaml) 数据集上进行了训练,并且适用于各种姿态估计任务。
|
||||
|
||||
## [模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
这里展示了YOLOv8预训练的姿态模型。检测、分割和姿态模型在 [COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml) 数据集上进行预训练,而分类模型则在 [ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml) 数据集上进行预训练。
|
||||
|
||||
[模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models) 在首次使用时将自动从最新的Ultralytics [发布版本](https://github.com/ultralytics/assets/releases)中下载。
|
||||
|
||||
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>姿态<br>50-95 | mAP<sup>姿态<br>50 | 速度<br><sup>CPU ONNX<br>(毫秒) | 速度<br><sup>A100 TensorRT<br>(毫秒) | 参数<br><sup>(M) | 浮点数运算<br><sup>(B) |
|
||||
|----------------------------------------------------------------------------------------------------|-----------------|---------------------|------------------|-----------------------------|----------------------------------|----------------|-------------------|
|
||||
| [YOLOv8n-姿态](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-pose.pt) | 640 | 50.4 | 80.1 | 131.8 | 1.18 | 3.3 | 9.2 |
|
||||
| [YOLOv8s-姿态](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-pose.pt) | 640 | 60.0 | 86.2 | 233.2 | 1.42 | 11.6 | 30.2 |
|
||||
| [YOLOv8m-姿态](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
|
||||
| [YOLOv8l-姿态](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
|
||||
| [YOLOv8x-姿态](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
|
||||
| [YOLOv8x-姿态-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
|
||||
|
||||
- **mAP<sup>val</sup>** 值适用于[COCO 关键点 val2017](http://cocodataset.org)数据集上的单模型单尺度。
|
||||
<br>通过执行 `yolo val pose data=coco-pose.yaml device=0` 来复现。
|
||||
- **速度** 是在 [亚马逊EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)实例上使用COCO val图像的平均值。
|
||||
<br>通过执行 `yolo val pose data=coco8-pose.yaml batch=1 device=0|cpu` 来复现。
|
||||
|
||||
## 训练
|
||||
|
||||
在COCO128姿态数据集上训练一个YOLOv8姿态模型。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n-pose.yaml') # 从YAML构建一个新模型
|
||||
model = YOLO('yolov8n-pose.pt') # 加载一个预训练模型(推荐用于训练)
|
||||
model = YOLO('yolov8n-pose.yaml').load('yolov8n-pose.pt') # 从YAML构建并传输权重
|
||||
|
||||
# 训练模型
|
||||
results = model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 从YAML构建一个新模型并从头开始训练
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml epochs=100 imgsz=640
|
||||
|
||||
# 从一个预训练的*.pt模型开始训练
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
|
||||
|
||||
# 从YAML构建一个新模型,传输预训练权重并开始训练
|
||||
yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml pretrained=yolov8n-pose.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### 数据集格式
|
||||
|
||||
YOLO姿态数据集格式可详细找到在[数据集指南](/../datasets/pose/index.md)中。若要将您现有的数据集从其他格式(如COCO等)转换为YOLO格式,请使用Ultralytics的 [JSON2YOLO](https://github.com/ultralytics/JSON2YOLO) 工具。
|
||||
|
||||
## 验证
|
||||
|
||||
在COCO128姿态数据集上验证训练好的YOLOv8n姿态模型的准确性。没有参数需要传递,因为`模型`保存了其训练`数据`和参数作为模型属性。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n-pose.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义模型
|
||||
|
||||
# 验证模型
|
||||
metrics = model.val() # 无需参数,数据集和设置都记住了
|
||||
metrics.box.map # map50-95
|
||||
metrics.box.map50 # map50
|
||||
metrics.box.map75 # map75
|
||||
metrics.box.maps # 包含每个类别map50-95的列表
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo pose val model=yolov8n-pose.pt # 验证官方模型
|
||||
yolo pose val model=path/to/best.pt # 验证自定义模型
|
||||
```
|
||||
|
||||
## 预测
|
||||
|
||||
使用训练好的YOLOv8n姿态模型在图片上运行预测。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n-pose.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义模型
|
||||
|
||||
# 用模型进行预测
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # 在一张图片上预测
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo pose predict model=yolov8n-pose.pt source='https://ultralytics.com/images/bus.jpg' # 用官方模型预测
|
||||
yolo pose predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # 用自定义模型预测
|
||||
```
|
||||
|
||||
在[预测](https://docs.ultralytics.com/modes/predict/)页面中查看完整的`预测`模式细节。
|
||||
|
||||
## 导出
|
||||
|
||||
将YOLOv8n姿态模型导出为ONNX、CoreML等不同格式。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 加载模型
|
||||
model = YOLO('yolov8n-pose.pt') # 加载官方模型
|
||||
model = YOLO('path/to/best.pt') # 加载自定义训练好的模型
|
||||
|
||||
# 导出模型
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-pose.pt format=onnx # 导出官方模型
|
||||
yolo export model=path/to/best.pt format=onnx # 导出自定义训练好的模型
|
||||
```
|
||||
|
||||
以下表格中有可用的YOLOv8姿态导出格式。您可以直接在导出的模型上进行预测或验证,例如 `yolo predict model=yolov8n-pose.onnx`。导出完成后,为您的模型显示用法示例。
|
||||
|
||||
| 格式 | `format` 参数 | 模型 | 元数据 | 参数 |
|
||||
|--------------------------------------------------------------------|---------------|--------------------------------|-----|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-pose.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-pose.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-pose.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-pose_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-pose.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-pose.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-pose_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-pose.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-pose.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-pose_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-pose_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-pose_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-pose_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
在[导出](https://docs.ultralytics.com/modes/export/) 页面中查看完整的`导出`细节。
|
||||
188
docs/zh/tasks/segment.md
Normal file
188
docs/zh/tasks/segment.md
Normal file
|
|
@ -0,0 +1,188 @@
|
|||
---
|
||||
comments: true
|
||||
description: 学习如何使用Ultralytics YOLO进行实例分割模型。包括训练、验证、图像预测和模型导出的说明。
|
||||
keywords: yolov8, 实例分割, Ultralytics, COCO数据集, 图像分割, 物体检测, 模型训练, 模型验证, 图像预测, 模型导出
|
||||
---
|
||||
|
||||
# 实例分割
|
||||
|
||||
<img width="1024" src="https://user-images.githubusercontent.com/26833433/243418644-7df320b8-098d-47f1-85c5-26604d761286.png" alt="实例分割示例">
|
||||
|
||||
实例分割比物体检测有所深入,它涉及到识别图像中的个别物体并将它们从图像的其余部分中分割出来。
|
||||
|
||||
实例分割模型的输出是一组蒙版或轮廓,用于勾画图像中每个物体,以及每个物体的类别标签和置信度分数。实例分割在您需要不仅知道图像中的物体位置,还需要知道它们确切形状时非常有用。
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<iframe width="720" height="405" src="https://www.youtube.com/embed/o4Zd-IeMlSY?si=37nusCzDTd74Obsp"
|
||||
title="YouTube视频播放器" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>观看:</strong> 在Python中使用预训练的Ultralytics YOLOv8模型运行分割。
|
||||
</p>
|
||||
|
||||
!!! tip "提示"
|
||||
|
||||
YOLOv8分割模型使用`-seg`后缀,即`yolov8n-seg.pt`,并在[COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)上进行预训练。
|
||||
|
||||
## [模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8)
|
||||
|
||||
这里展示了预训练的YOLOv8分割模型。Detect、Segment和Pose模型都是在[COCO](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml)数据集上进行预训练的,而Classify模型则是在[ImageNet](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/ImageNet.yaml)数据集上进行预训练的。
|
||||
|
||||
[模型](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models)会在首次使用时自动从Ultralytics的最新[版本](https://github.com/ultralytics/assets/releases)下载。
|
||||
|
||||
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | 速度<br><sup>CPU ONNX<br>(ms) | 速度<br><sup>A100 TensorRT<br>(ms) | 参数<br><sup>(M) | FLOPs<br><sup>(B) |
|
||||
|----------------------------------------------------------------------------------------------|-----------------|----------------------|-----------------------|-----------------------------|----------------------------------|----------------|-------------------|
|
||||
| [YOLOv8n-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n-seg.pt) | 640 | 36.7 | 30.5 | 96.1 | 1.21 | 3.4 | 12.6 |
|
||||
| [YOLOv8s-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s-seg.pt) | 640 | 44.6 | 36.8 | 155.7 | 1.47 | 11.8 | 42.6 |
|
||||
| [YOLOv8m-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-seg.pt) | 640 | 49.9 | 40.8 | 317.0 | 2.18 | 27.3 | 110.2 |
|
||||
| [YOLOv8l-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-seg.pt) | 640 | 52.3 | 42.6 | 572.4 | 2.79 | 46.0 | 220.5 |
|
||||
| [YOLOv8x-seg](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-seg.pt) | 640 | 53.4 | 43.4 | 712.1 | 4.02 | 71.8 | 344.1 |
|
||||
|
||||
- **mAP<sup>val</sup>** 值针对[COCO val2017](http://cocodataset.org)数据集的单模型单尺度。
|
||||
<br>通过`yolo val segment data=coco.yaml device=0`复现。
|
||||
- **速度** 基于在[Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)实例上运行的COCO val图像的平均值。
|
||||
<br>通过`yolo val segment data=coco128-seg.yaml batch=1 device=0|cpu`复现。
|
||||
|
||||
## 训练
|
||||
|
||||
在COCO128-seg数据集上以640的图像尺寸训练YOLOv8n-seg模型共100个周期。想了解更多可用的参数,请查阅[配置](/../usage/cfg.md)页面。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 载入一个模型
|
||||
model = YOLO('yolov8n-seg.yaml') # 从YAML构建一个新模型
|
||||
model = YOLO('yolov8n-seg.pt') # 载入预训练模型(推荐用于训练)
|
||||
model = YOLO('yolov8n-seg.yaml').load('yolov8n.pt') # 从YAML构建并传递权重
|
||||
|
||||
# 训练模型
|
||||
results = model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# 从YAML构建新模型并从头开始训练
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml epochs=100 imgsz=640
|
||||
|
||||
# 从预训练*.pt模型开始训练
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
|
||||
|
||||
# 从YAML构建新模型,传递预训练权重,开始训练
|
||||
yolo segment train data=coco128-seg.yaml model=yolov8n-seg.yaml pretrained=yolov8n-seg.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
### 数据集格式
|
||||
|
||||
可以在[数据集指南](/../datasets/segment/index.md)中详细了解YOLO分割数据集格式。要将现有数据集从其他格式(如COCO等)转换为YOLO格式,请使用Ultralytics的[JSON2YOLO](https://github.com/ultralytics/JSON2YOLO)工具。
|
||||
|
||||
## 验证
|
||||
|
||||
在COCO128-seg数据集上验证已训练的YOLOv8n-seg模型的准确性。不需要传递任何参数,因为`model`保留了其训练的`data`和作为模型属性的设置。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 载入一个模型
|
||||
model = YOLO('yolov8n-seg.pt') # 载入官方模型
|
||||
model = YOLO('path/to/best.pt') # 载入自定义模型
|
||||
|
||||
# 验证模型
|
||||
metrics = model.val() # 不需要参数,数据集和设置被记住了
|
||||
metrics.box.map # map50-95(B)
|
||||
metrics.box.map50 # map50(B)
|
||||
metrics.box.map75 # map75(B)
|
||||
metrics.box.maps # 各类别map50-95(B)列表
|
||||
metrics.seg.map # map50-95(M)
|
||||
metrics.seg.map50 # map50(M)
|
||||
metrics.seg.map75 # map75(M)
|
||||
metrics.seg.maps # 各类别map50-95(M)列表
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo segment val model=yolov8n-seg.pt # 验证官方模型
|
||||
yolo segment val model=path/to/best.pt # 验证自定义模型
|
||||
```
|
||||
|
||||
## 预测
|
||||
|
||||
使用已训练的YOLOv8n-seg模型在图像上进行预测。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 载入一个模型
|
||||
model = YOLO('yolov8n-seg.pt') # 载入官方模型
|
||||
model = YOLO('path/to/best.pt') # 载入自定义模型
|
||||
|
||||
# 使用模型进行预测
|
||||
results = model('https://ultralytics.com/images/bus.jpg') # 对一张图像进行预测
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo segment predict model=yolov8n-seg.pt source='https://ultralytics.com/images/bus.jpg' # 使用官方模型进行预测
|
||||
yolo segment predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # 使用自定义模型进行预测
|
||||
```
|
||||
|
||||
预测模式的完整详情请参见[Predict](https://docs.ultralytics.com/modes/predict/)页面。
|
||||
|
||||
## 导出
|
||||
|
||||
将YOLOv8n-seg模型导出为ONNX、CoreML等不同格式。
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# 载入一个模型
|
||||
model = YOLO('yolov8n-seg.pt') # 载入官方模型
|
||||
model = YOLO('path/to/best.pt') # 载入自定义训练模型
|
||||
|
||||
# 导出模型
|
||||
model.export(format='onnx')
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
yolo export model=yolov8n-seg.pt format=onnx # 导出官方模型
|
||||
yolo export model=path/to/best.pt format=onnx # 导出自定义训练模型
|
||||
```
|
||||
|
||||
YOLOv8-seg导出格式的可用表格如下所示。您可以直接在导出的模型上进行预测或验证,例如`yolo predict model=yolov8n-seg.onnx`。导出完成后,示例用法将显示您的模型。
|
||||
|
||||
| 格式 | `format` 参数 | 模型 | 元数据 | 参数 |
|
||||
|--------------------------------------------------------------------|---------------|-------------------------------|-----|-----------------------------------------------------|
|
||||
| [PyTorch](https://pytorch.org/) | - | `yolov8n-seg.pt` | ✅ | - |
|
||||
| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n-seg.torchscript` | ✅ | `imgsz`, `optimize` |
|
||||
| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n-seg.onnx` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `opset` |
|
||||
| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n-seg_openvino_model/` | ✅ | `imgsz`, `half` |
|
||||
| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n-seg.engine` | ✅ | `imgsz`, `half`, `dynamic`, `simplify`, `workspace` |
|
||||
| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n-seg.mlpackage` | ✅ | `imgsz`, `half`, `int8`, `nms` |
|
||||
| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n-seg_saved_model/` | ✅ | `imgsz`, `keras` |
|
||||
| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n-seg.pb` | ❌ | `imgsz` |
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n-seg.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n-seg_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n-seg_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n-seg_paddle_model/` | ✅ | `imgsz` |
|
||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n-seg_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||
|
||||
导出模式的完整详情请参见[Export](https://docs.ultralytics.com/modes/export/)页面。
|
||||
Loading…
Add table
Add a link
Reference in a new issue