Add Chinese Modes and Tasks Docs (#6274)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
This commit is contained in:
parent
795b95bdcb
commit
e3a538bbde
293 changed files with 3681 additions and 736 deletions
97
docs/en/datasets/detect/argoverse.md
Normal file
97
docs/en/datasets/detect/argoverse.md
Normal file
|
|
@ -0,0 +1,97 @@
|
|||
---
|
||||
comments: true
|
||||
description: Explore Argoverse, a comprehensive dataset for autonomous driving tasks including 3D tracking, motion forecasting and depth estimation used in YOLO.
|
||||
keywords: Argoverse dataset, autonomous driving, YOLO, 3D tracking, motion forecasting, LiDAR data, HD maps, ultralytics documentation
|
||||
---
|
||||
|
||||
# Argoverse Dataset
|
||||
|
||||
The [Argoverse](https://www.argoverse.org/) dataset is a collection of data designed to support research in autonomous driving tasks, such as 3D tracking, motion forecasting, and stereo depth estimation. Developed by Argo AI, the dataset provides a wide range of high-quality sensor data, including high-resolution images, LiDAR point clouds, and map data.
|
||||
|
||||
!!! note
|
||||
|
||||
The Argoverse dataset *.zip file required for training was removed from Amazon S3 after the shutdown of Argo AI by Ford, but we have made it available for manual download on [Google Drive](https://drive.google.com/file/d/1st9qW3BeIwQsnR0t8mRpvbsSWIo16ACi/view?usp=drive_link).
|
||||
|
||||
## Key Features
|
||||
|
||||
- Argoverse contains over 290K labeled 3D object tracks and 5 million object instances across 1,263 distinct scenes.
|
||||
- The dataset includes high-resolution camera images, LiDAR point clouds, and richly annotated HD maps.
|
||||
- Annotations include 3D bounding boxes for objects, object tracks, and trajectory information.
|
||||
- Argoverse provides multiple subsets for different tasks, such as 3D tracking, motion forecasting, and stereo depth estimation.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The Argoverse dataset is organized into three main subsets:
|
||||
|
||||
1. **Argoverse 3D Tracking**: This subset contains 113 scenes with over 290K labeled 3D object tracks, focusing on 3D object tracking tasks. It includes LiDAR point clouds, camera images, and sensor calibration information.
|
||||
2. **Argoverse Motion Forecasting**: This subset consists of 324K vehicle trajectories collected from 60 hours of driving data, suitable for motion forecasting tasks.
|
||||
3. **Argoverse Stereo Depth Estimation**: This subset is designed for stereo depth estimation tasks and includes over 10K stereo image pairs with corresponding LiDAR point clouds for ground truth depth estimation.
|
||||
|
||||
## Applications
|
||||
|
||||
The Argoverse dataset is widely used for training and evaluating deep learning models in autonomous driving tasks such as 3D object tracking, motion forecasting, and stereo depth estimation. The dataset's diverse set of sensor data, object annotations, and map information make it a valuable resource for researchers and practitioners in the field of autonomous driving.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Argoverse dataset, the `Argoverse.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Argoverse.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Argoverse.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/Argoverse.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/Argoverse.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='Argoverse.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=Argoverse.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
The Argoverse dataset contains a diverse set of sensor data, including camera images, LiDAR point clouds, and HD map information, providing rich context for autonomous driving tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Argoverse 3D Tracking**: This image demonstrates an example of 3D object tracking, where objects are annotated with 3D bounding boxes. The dataset provides LiDAR point clouds and camera images to facilitate the development of models for this task.
|
||||
|
||||
The example showcases the variety and complexity of the data in the Argoverse dataset and highlights the importance of high-quality sensor data for autonomous driving tasks.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the Argoverse dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@inproceedings{chang2019argoverse,
|
||||
title={Argoverse: 3D Tracking and Forecasting with Rich Maps},
|
||||
author={Chang, Ming-Fang and Lambert, John and Sangkloy, Patsorn and Singh, Jagjeet and Bak, Slawomir and Hartnett, Andrew and Wang, Dequan and Carr, Peter and Lucey, Simon and Ramanan, Deva and others},
|
||||
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
||||
pages={8748--8757},
|
||||
year={2019}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge Argo AI for creating and maintaining the Argoverse dataset as a valuable resource for the autonomous driving research community. For more information about the Argoverse dataset and its creators, visit the [Argoverse dataset website](https://www.argoverse.org/).
|
||||
94
docs/en/datasets/detect/coco.md
Normal file
94
docs/en/datasets/detect/coco.md
Normal file
|
|
@ -0,0 +1,94 @@
|
|||
---
|
||||
comments: true
|
||||
description: Learn how COCO, a leading dataset for object detection and segmentation, integrates with Ultralytics. Discover ways to use it for training YOLO models.
|
||||
keywords: Ultralytics, COCO dataset, object detection, YOLO, YOLO model training, image segmentation, computer vision, deep learning models
|
||||
---
|
||||
|
||||
# COCO Dataset
|
||||
|
||||
The [COCO](https://cocodataset.org/#home) (Common Objects in Context) dataset is a large-scale object detection, segmentation, and captioning dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and pose estimation tasks.
|
||||
|
||||
## Key Features
|
||||
|
||||
- COCO contains 330K images, with 200K images having annotations for object detection, segmentation, and captioning tasks.
|
||||
- The dataset comprises 80 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment.
|
||||
- Annotations include object bounding boxes, segmentation masks, and captions for each image.
|
||||
- COCO provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The COCO dataset is split into three subsets:
|
||||
|
||||
1. **Train2017**: This subset contains 118K images for training object detection, segmentation, and captioning models.
|
||||
2. **Val2017**: This subset has 5K images used for validation purposes during model training.
|
||||
3. **Test2017**: This subset consists of 20K images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [COCO evaluation server](https://codalab.lisn.upsaclay.fr/competitions/7384) for performance evaluation.
|
||||
|
||||
## Applications
|
||||
|
||||
The COCO dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and keypoint detection (such as OpenPose). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO dataset, the `coco.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/coco.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/coco.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the COCO dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='coco.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Images and Annotations
|
||||
|
||||
The COCO dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
||||
|
||||
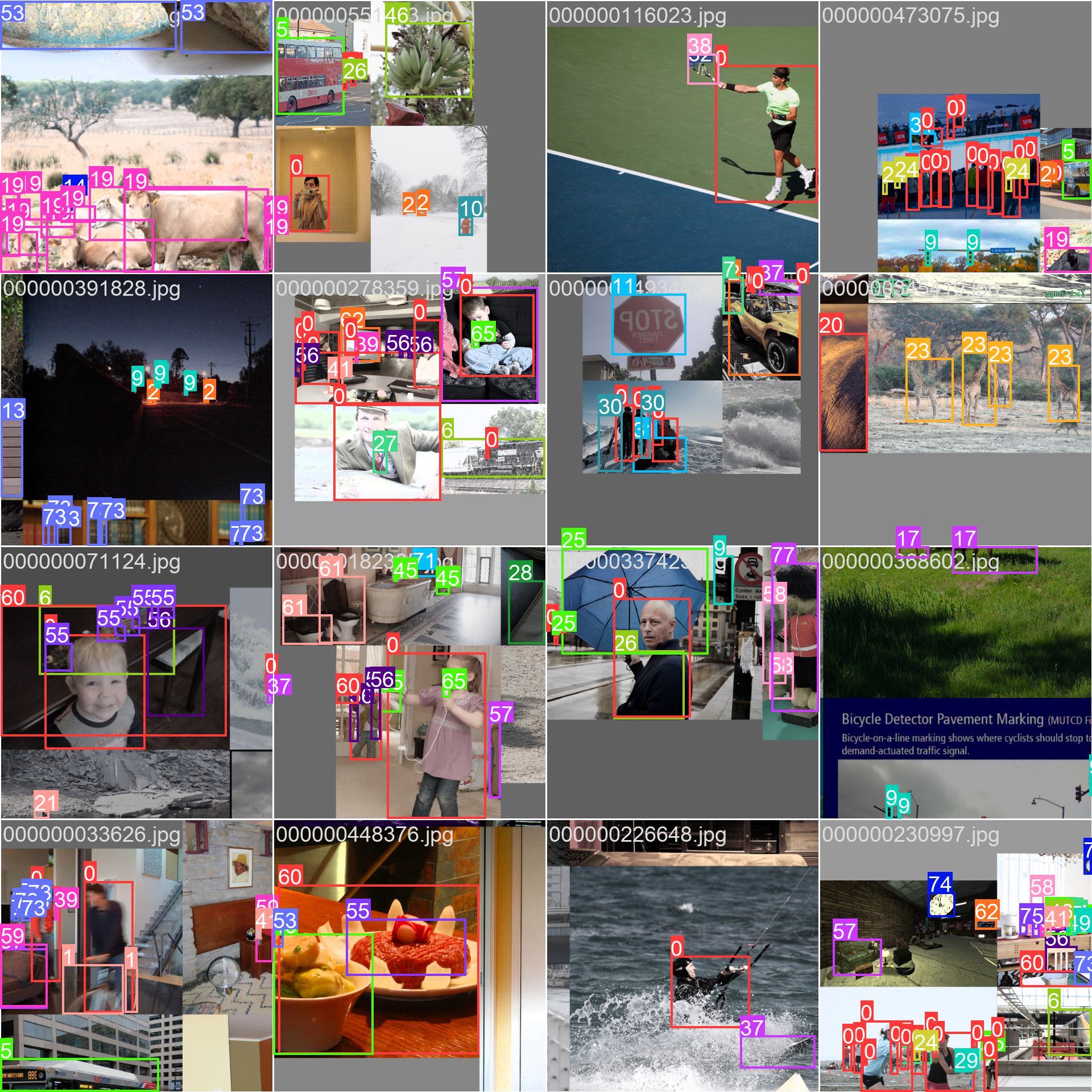
|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
The example showcases the variety and complexity of the images in the COCO dataset and the benefits of using mosaicing during the training process.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the COCO dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{lin2015microsoft,
|
||||
title={Microsoft COCO: Common Objects in Context},
|
||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||
year={2015},
|
||||
eprint={1405.0312},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||
80
docs/en/datasets/detect/coco8.md
Normal file
80
docs/en/datasets/detect/coco8.md
Normal file
|
|
@ -0,0 +1,80 @@
|
|||
---
|
||||
comments: true
|
||||
description: Discover the benefits of using the practical and diverse COCO8 dataset for object detection model testing. Learn to configure and use it via Ultralytics HUB and YOLOv8.
|
||||
keywords: Ultralytics, COCO8 dataset, object detection, model testing, dataset configuration, detection approaches, sanity check, training pipelines, YOLOv8
|
||||
---
|
||||
|
||||
# COCO8 Dataset
|
||||
|
||||
## Introduction
|
||||
|
||||
[Ultralytics](https://ultralytics.com) COCO8 is a small, but versatile object detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
|
||||
|
||||
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)
|
||||
and [YOLOv8](https://github.com/ultralytics/ultralytics).
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the COCO8 dataset, the `coco8.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/coco8.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/coco8.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/coco8.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Images and Annotations
|
||||
|
||||
Here are some examples of images from the COCO8 dataset, along with their corresponding annotations:
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/236818348-e6260a3d-0454-436b-83a9-de366ba07235.jpg" alt="Dataset sample image" width="800">
|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
The example showcases the variety and complexity of the images in the COCO8 dataset and the benefits of using mosaicing during the training process.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the COCO dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{lin2015microsoft,
|
||||
title={Microsoft COCO: Common Objects in Context},
|
||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||
year={2015},
|
||||
eprint={1405.0312},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||
91
docs/en/datasets/detect/globalwheat2020.md
Normal file
91
docs/en/datasets/detect/globalwheat2020.md
Normal file
|
|
@ -0,0 +1,91 @@
|
|||
---
|
||||
comments: true
|
||||
description: Understand how to utilize the vast Global Wheat Head Dataset for building wheat head detection models. Features, structure, applications, usage, sample data, and citation.
|
||||
keywords: Ultralytics, YOLO, Global Wheat Head Dataset, wheat head detection, plant phenotyping, crop management, deep learning, outdoor images, annotations, YAML configuration
|
||||
---
|
||||
|
||||
# Global Wheat Head Dataset
|
||||
|
||||
The [Global Wheat Head Dataset](http://www.global-wheat.com/) is a collection of images designed to support the development of accurate wheat head detection models for applications in wheat phenotyping and crop management. Wheat heads, also known as spikes, are the grain-bearing parts of the wheat plant. Accurate estimation of wheat head density and size is essential for assessing crop health, maturity, and yield potential. The dataset, created by a collaboration of nine research institutes from seven countries, covers multiple growing regions to ensure models generalize well across different environments.
|
||||
|
||||
## Key Features
|
||||
|
||||
- The dataset contains over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
|
||||
- It includes approximately 1,000 test images from Australia, Japan, and China.
|
||||
- Images are outdoor field images, capturing the natural variability in wheat head appearances.
|
||||
- Annotations include wheat head bounding boxes to support object detection tasks.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The Global Wheat Head Dataset is organized into two main subsets:
|
||||
|
||||
1. **Training Set**: This subset contains over 3,000 images from Europe and North America. The images are labeled with wheat head bounding boxes, providing ground truth for training object detection models.
|
||||
2. **Test Set**: This subset consists of approximately 1,000 images from Australia, Japan, and China. These images are used for evaluating the performance of trained models on unseen genotypes, environments, and observational conditions.
|
||||
|
||||
## Applications
|
||||
|
||||
The Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Global Wheat Head Dataset, the `GlobalWheat2020.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/GlobalWheat2020.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/GlobalWheat2020.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='GlobalWheat2020.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=GlobalWheat2020.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
|
||||
|
||||
The example showcases the variety and complexity of the data in the Global Wheat Head Dataset and highlights the importance of accurate wheat head detection for applications in wheat phenotyping and crop management.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the Global Wheat Head Dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{david2020global,
|
||||
title={Global Wheat Head Detection (GWHD) Dataset: A Large and Diverse Dataset of High-Resolution RGB-Labelled Images to Develop and Benchmark Wheat Head Detection Methods},
|
||||
author={David, Etienne and Madec, Simon and Sadeghi-Tehran, Pouria and Aasen, Helge and Zheng, Bangyou and Liu, Shouyang and Kirchgessner, Norbert and Ishikawa, Goro and Nagasawa, Koichi and Badhon, Minhajul and others},
|
||||
journal={arXiv preprint arXiv:2005.02162},
|
||||
year={2020}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](http://www.global-wheat.com/).
|
||||
108
docs/en/datasets/detect/index.md
Normal file
108
docs/en/datasets/detect/index.md
Normal file
|
|
@ -0,0 +1,108 @@
|
|||
---
|
||||
comments: true
|
||||
description: Navigate through supported dataset formats, methods to utilize them and how to add your own datasets. Get insights on porting or converting label formats.
|
||||
keywords: Ultralytics, YOLO, datasets, object detection, dataset formats, label formats, data conversion
|
||||
---
|
||||
|
||||
# Object Detection Datasets Overview
|
||||
|
||||
Training a robust and accurate object detection model requires a comprehensive dataset. This guide introduces various formats of datasets that are compatible with the Ultralytics YOLO model and provides insights into their structure, usage, and how to convert between different formats.
|
||||
|
||||
## Supported Dataset Formats
|
||||
|
||||
### Ultralytics YOLO format
|
||||
|
||||
The Ultralytics YOLO format is a dataset configuration format that allows you to define the dataset root directory, the relative paths to training/validation/testing image directories or *.txt files containing image paths, and a dictionary of class names. Here is an example:
|
||||
|
||||
```yaml
|
||||
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||
path: ../datasets/coco8 # dataset root dir
|
||||
train: images/train # train images (relative to 'path') 4 images
|
||||
val: images/val # val images (relative to 'path') 4 images
|
||||
test: # test images (optional)
|
||||
|
||||
# Classes (80 COCO classes)
|
||||
names:
|
||||
0: person
|
||||
1: bicycle
|
||||
2: car
|
||||
...
|
||||
77: teddy bear
|
||||
78: hair drier
|
||||
79: toothbrush
|
||||
```
|
||||
|
||||
Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
|
||||
|
||||
<p align="center"><img width="750" src="https://user-images.githubusercontent.com/26833433/91506361-c7965000-e886-11ea-8291-c72b98c25eec.jpg" alt="Example labelled image"></p>
|
||||
|
||||
The label file corresponding to the above image contains 2 persons (class `0`) and a tie (class `27`):
|
||||
|
||||
<p align="center"><img width="428" src="https://user-images.githubusercontent.com/26833433/112467037-d2568c00-8d66-11eb-8796-55402ac0d62f.png" alt="Example label file"></p>
|
||||
|
||||
When using the Ultralytics YOLO format, organize your training and validation images and labels as shown in the example below.
|
||||
|
||||
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/134436012-65111ad1-9541-4853-81a6-f19a3468b75f.png" alt="Example dataset directory structure"></p>
|
||||
|
||||
## Usage
|
||||
|
||||
Here's how you can use these formats to train your model:
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=coco8.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Supported Datasets
|
||||
|
||||
Here is a list of the supported datasets and a brief description for each:
|
||||
|
||||
- [**Argoverse**](./argoverse.md): A collection of sensor data collected from autonomous vehicles. It contains 3D tracking annotations for car objects.
|
||||
- [**COCO**](./coco.md): Common Objects in Context (COCO) is a large-scale object detection, segmentation, and captioning dataset with 80 object categories.
|
||||
- [**COCO8**](./coco8.md): A smaller subset of the COCO dataset, COCO8 is more lightweight and faster to train.
|
||||
- [**GlobalWheat2020**](./globalwheat2020.md): A dataset containing images of wheat heads for the Global Wheat Challenge 2020.
|
||||
- [**Objects365**](./objects365.md): A large-scale object detection dataset with 365 object categories and 600k images, aimed at advancing object detection research.
|
||||
- [**OpenImagesV7**](./open-images-v7.md): A comprehensive dataset by Google with 1.7M train images and 42k validation images.
|
||||
- [**SKU-110K**](./sku-110k.md): A dataset containing images of densely packed retail products, intended for retail environment object detection.
|
||||
- [**VisDrone**](./visdrone.md): A dataset focusing on drone-based images, containing various object categories like cars, pedestrians, and cyclists.
|
||||
- [**VOC**](./voc.md): PASCAL VOC is a popular object detection dataset with 20 object categories including vehicles, animals, and furniture.
|
||||
- [**xView**](./xview.md): A dataset containing high-resolution satellite imagery, designed for the detection of various object classes in overhead views.
|
||||
|
||||
### Adding your own dataset
|
||||
|
||||
If you have your own dataset and would like to use it for training detection models with Ultralytics YOLO format, ensure that it follows the format specified above under "Ultralytics YOLO format". Convert your annotations to the required format and specify the paths, number of classes, and class names in the YAML configuration file.
|
||||
|
||||
## Port or Convert Label Formats
|
||||
|
||||
### COCO Dataset Format to YOLO Format
|
||||
|
||||
You can easily convert labels from the popular COCO dataset format to the YOLO format using the following code snippet:
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics.data.converter import convert_coco
|
||||
|
||||
convert_coco(labels_dir='path/to/coco/annotations/')
|
||||
```
|
||||
|
||||
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
|
||||
|
||||
Remember to double-check if the dataset you want to use is compatible with your model and follows the necessary format conventions. Properly formatted datasets are crucial for training successful object detection models.
|
||||
92
docs/en/datasets/detect/objects365.md
Normal file
92
docs/en/datasets/detect/objects365.md
Normal file
|
|
@ -0,0 +1,92 @@
|
|||
---
|
||||
comments: true
|
||||
description: Discover the Objects365 dataset, a wide-scale, high-quality resource for object detection research. Learn to use it with the Ultralytics YOLO model.
|
||||
keywords: Objects365, object detection, Ultralytics, dataset, YOLO, bounding boxes, annotations, computer vision, deep learning, training models
|
||||
---
|
||||
|
||||
# Objects365 Dataset
|
||||
|
||||
The [Objects365](https://www.objects365.org/) dataset is a large-scale, high-quality dataset designed to foster object detection research with a focus on diverse objects in the wild. Created by a team of [Megvii](https://en.megvii.com/) researchers, the dataset offers a wide range of high-resolution images with a comprehensive set of annotated bounding boxes covering 365 object categories.
|
||||
|
||||
## Key Features
|
||||
|
||||
- Objects365 contains 365 object categories, with 2 million images and over 30 million bounding boxes.
|
||||
- The dataset includes diverse objects in various scenarios, providing a rich and challenging benchmark for object detection tasks.
|
||||
- Annotations include bounding boxes for objects, making it suitable for training and evaluating object detection models.
|
||||
- Objects365 pre-trained models significantly outperform ImageNet pre-trained models, leading to better generalization on various tasks.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The Objects365 dataset is organized into a single set of images with corresponding annotations:
|
||||
|
||||
- **Images**: The dataset includes 2 million high-resolution images, each containing a variety of objects across 365 categories.
|
||||
- **Annotations**: The images are annotated with over 30 million bounding boxes, providing comprehensive ground truth information for object detection tasks.
|
||||
|
||||
## Applications
|
||||
|
||||
The Objects365 dataset is widely used for training and evaluating deep learning models in object detection tasks. The dataset's diverse set of object categories and high-quality annotations make it a valuable resource for researchers and practitioners in the field of computer vision.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the Objects365 Dataset, the `Objects365.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Objects365.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/Objects365.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/Objects365.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/Objects365.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='Objects365.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=Objects365.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
The Objects365 dataset contains a diverse set of high-resolution images with objects from 365 categories, providing rich context for object detection tasks. Here are some examples of the images in the dataset:
|
||||
|
||||

|
||||
|
||||
- **Objects365**: This image demonstrates an example of object detection, where objects are annotated with bounding boxes. The dataset provides a wide range of images to facilitate the development of models for this task.
|
||||
|
||||
The example showcases the variety and complexity of the data in the Objects365 dataset and highlights the importance of accurate object detection for computer vision applications.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the Objects365 dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@inproceedings{shao2019objects365,
|
||||
title={Objects365: A Large-scale, High-quality Dataset for Object Detection},
|
||||
author={Shao, Shuai and Li, Zeming and Zhang, Tianyuan and Peng, Chao and Yu, Gang and Li, Jing and Zhang, Xiangyu and Sun, Jian},
|
||||
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
|
||||
pages={8425--8434},
|
||||
year={2019}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the team of researchers who created and maintain the Objects365 dataset as a valuable resource for the computer vision research community. For more information about the Objects365 dataset and its creators, visit the [Objects365 dataset website](https://www.objects365.org/).
|
||||
110
docs/en/datasets/detect/open-images-v7.md
Normal file
110
docs/en/datasets/detect/open-images-v7.md
Normal file
|
|
@ -0,0 +1,110 @@
|
|||
---
|
||||
comments: true
|
||||
description: Dive into Google's Open Images V7, a comprehensive dataset offering a broad scope for computer vision research. Understand its usage with deep learning models.
|
||||
keywords: Open Images V7, object detection, segmentation masks, visual relationships, localized narratives, computer vision, deep learning, annotations, bounding boxes
|
||||
---
|
||||
|
||||
# Open Images V7 Dataset
|
||||
|
||||
[Open Images V7](https://storage.googleapis.com/openimages/web/index.html) is a versatile and expansive dataset championed by Google. Aimed at propelling research in the realm of computer vision, it boasts a vast collection of images annotated with a plethora of data, including image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localized narratives.
|
||||
|
||||

|
||||
|
||||
## Key Features
|
||||
|
||||
- Encompasses ~9M images annotated in various ways to suit multiple computer vision tasks.
|
||||
- Houses a staggering 16M bounding boxes across 600 object classes in 1.9M images. These boxes are primarily hand-drawn by experts ensuring high precision.
|
||||
- Visual relationship annotations totaling 3.3M are available, detailing 1,466 unique relationship triplets, object properties, and human activities.
|
||||
- V5 introduced segmentation masks for 2.8M objects across 350 classes.
|
||||
- V6 introduced 675k localized narratives that amalgamate voice, text, and mouse traces highlighting described objects.
|
||||
- V7 introduced 66.4M point-level labels on 1.4M images, spanning 5,827 classes.
|
||||
- Encompasses 61.4M image-level labels across a diverse set of 20,638 classes.
|
||||
- Provides a unified platform for image classification, object detection, relationship detection, instance segmentation, and multimodal image descriptions.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
Open Images V7 is structured in multiple components catering to varied computer vision challenges:
|
||||
|
||||
- **Images**: About 9 million images, often showcasing intricate scenes with an average of 8.3 objects per image.
|
||||
- **Bounding Boxes**: Over 16 million boxes that demarcate objects across 600 categories.
|
||||
- **Segmentation Masks**: These detail the exact boundary of 2.8M objects across 350 classes.
|
||||
- **Visual Relationships**: 3.3M annotations indicating object relationships, properties, and actions.
|
||||
- **Localized Narratives**: 675k descriptions combining voice, text, and mouse traces.
|
||||
- **Point-Level Labels**: 66.4M labels across 1.4M images, suitable for zero/few-shot semantic segmentation.
|
||||
|
||||
## Applications
|
||||
|
||||
Open Images V7 is a cornerstone for training and evaluating state-of-the-art models in various computer vision tasks. The dataset's broad scope and high-quality annotations make it indispensable for researchers and developers specializing in computer vision.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
Typically, datasets come with a YAML (Yet Another Markup Language) file that delineates the dataset's configuration. For the case of Open Images V7, a hypothetical `OpenImagesV7.yaml` might exist. For accurate paths and configurations, one should refer to the dataset's official repository or documentation.
|
||||
|
||||
!!! example "OpenImagesV7.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/open-images-v7.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the Open Images V7 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! warning
|
||||
|
||||
The complete Open Images V7 dataset comprises 1,743,042 training images and 41,620 validation images, requiring approximately **561 GB of storage space** upon download.
|
||||
|
||||
Executing the commands provided below will trigger an automatic download of the full dataset if it's not already present locally. Before running the below example it's crucial to:
|
||||
|
||||
- Verify that your device has enough storage capacity.
|
||||
- Ensure a robust and speedy internet connection.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a COCO-pretrained YOLOv8n model
|
||||
model = YOLO('yolov8n.pt')
|
||||
|
||||
# Train the model on the Open Images V7 dataset
|
||||
results = model.train(data='open-images-v7.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Train a COCO-pretrained YOLOv8n model on the Open Images V7 dataset
|
||||
yolo detect train data=open-images-v7.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
Illustrations of the dataset help provide insights into its richness:
|
||||
|
||||

|
||||
|
||||
- **Open Images V7**: This image exemplifies the depth and detail of annotations available, including bounding boxes, relationships, and segmentation masks.
|
||||
|
||||
Researchers can gain invaluable insights into the array of computer vision challenges that the dataset addresses, from basic object detection to intricate relationship identification.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
For those employing Open Images V7 in their work, it's prudent to cite the relevant papers and acknowledge the creators:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@article{OpenImages,
|
||||
author = {Alina Kuznetsova and Hassan Rom and Neil Alldrin and Jasper Uijlings and Ivan Krasin and Jordi Pont-Tuset and Shahab Kamali and Stefan Popov and Matteo Malloci and Alexander Kolesnikov and Tom Duerig and Vittorio Ferrari},
|
||||
title = {The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale},
|
||||
year = {2020},
|
||||
journal = {IJCV}
|
||||
}
|
||||
```
|
||||
|
||||
A heartfelt acknowledgment goes out to the Google AI team for creating and maintaining the Open Images V7 dataset. For a deep dive into the dataset and its offerings, navigate to the [official Open Images V7 website](https://storage.googleapis.com/openimages/web/index.html).
|
||||
93
docs/en/datasets/detect/sku-110k.md
Normal file
93
docs/en/datasets/detect/sku-110k.md
Normal file
|
|
@ -0,0 +1,93 @@
|
|||
---
|
||||
comments: true
|
||||
description: Explore the SKU-110k dataset of densely packed retail shelf images for object detection research. Learn how to use it with Ultralytics.
|
||||
keywords: SKU-110k dataset, object detection, retail shelf images, Ultralytics, YOLO, computer vision, deep learning models
|
||||
---
|
||||
|
||||
# SKU-110k Dataset
|
||||
|
||||
The [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection of densely packed retail shelf images, designed to support research in object detection tasks. Developed by Eran Goldman et al., the dataset contains over 110,000 unique store keeping unit (SKU) categories with densely packed objects, often looking similar or even identical, positioned in close proximity.
|
||||
|
||||

|
||||
|
||||
## Key Features
|
||||
|
||||
- SKU-110k contains images of store shelves from around the world, featuring densely packed objects that pose challenges for state-of-the-art object detectors.
|
||||
- The dataset includes over 110,000 unique SKU categories, providing a diverse range of object appearances.
|
||||
- Annotations include bounding boxes for objects and SKU category labels.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The SKU-110k dataset is organized into three main subsets:
|
||||
|
||||
1. **Training set**: This subset contains images and annotations used for training object detection models.
|
||||
2. **Validation set**: This subset consists of images and annotations used for model validation during training.
|
||||
3. **Test set**: This subset is designed for the final evaluation of trained object detection models.
|
||||
|
||||
## Applications
|
||||
|
||||
The SKU-110k dataset is widely used for training and evaluating deep learning models in object detection tasks, especially in densely packed scenes such as retail shelf displays. The dataset's diverse set of SKU categories and densely packed object arrangements make it a valuable resource for researchers and practitioners in the field of computer vision.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. For the case of the SKU-110K dataset, the `SKU-110K.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/SKU-110K.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/SKU-110K.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/SKU-110K.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/SKU-110K.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='SKU-110K.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=SKU-110K.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
The SKU-110k dataset contains a diverse set of retail shelf images with densely packed objects, providing rich context for object detection tasks. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Densely packed retail shelf image**: This image demonstrates an example of densely packed objects in a retail shelf setting. Objects are annotated with bounding boxes and SKU category labels.
|
||||
|
||||
The example showcases the variety and complexity of the data in the SKU-110k dataset and highlights the importance of high-quality data for object detection tasks.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the SKU-110k dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@inproceedings{goldman2019dense,
|
||||
author = {Eran Goldman and Roei Herzig and Aviv Eisenschtat and Jacob Goldberger and Tal Hassner},
|
||||
title = {Precise Detection in Densely Packed Scenes},
|
||||
booktitle = {Proc. Conf. Comput. Vision Pattern Recognition (CVPR)},
|
||||
year = {2019}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge Eran Goldman et al. for creating and maintaining the SKU-110k dataset as a valuable resource for the computer vision research community. For more information about the SKU-110k dataset and its creators, visit the [SKU-110k dataset GitHub repository](https://github.com/eg4000/SKU110K_CVPR19).
|
||||
92
docs/en/datasets/detect/visdrone.md
Normal file
92
docs/en/datasets/detect/visdrone.md
Normal file
|
|
@ -0,0 +1,92 @@
|
|||
---
|
||||
comments: true
|
||||
description: Explore the VisDrone Dataset, a large-scale benchmark for drone-based image analysis, and learn how to train a YOLO model using it.
|
||||
keywords: VisDrone Dataset, Ultralytics, drone-based image analysis, YOLO model, object detection, object tracking, crowd counting
|
||||
---
|
||||
|
||||
# VisDrone Dataset
|
||||
|
||||
The [VisDrone Dataset](https://github.com/VisDrone/VisDrone-Dataset) is a large-scale benchmark created by the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China. It contains carefully annotated ground truth data for various computer vision tasks related to drone-based image and video analysis.
|
||||
|
||||
VisDrone is composed of 288 video clips with 261,908 frames and 10,209 static images, captured by various drone-mounted cameras. The dataset covers a wide range of aspects, including location (14 different cities across China), environment (urban and rural), objects (pedestrians, vehicles, bicycles, etc.), and density (sparse and crowded scenes). The dataset was collected using various drone platforms under different scenarios and weather and lighting conditions. These frames are manually annotated with over 2.6 million bounding boxes of targets such as pedestrians, cars, bicycles, and tricycles. Attributes like scene visibility, object class, and occlusion are also provided for better data utilization.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The VisDrone dataset is organized into five main subsets, each focusing on a specific task:
|
||||
|
||||
1. **Task 1**: Object detection in images
|
||||
2. **Task 2**: Object detection in videos
|
||||
3. **Task 3**: Single-object tracking
|
||||
4. **Task 4**: Multi-object tracking
|
||||
5. **Task 5**: Crowd counting
|
||||
|
||||
## Applications
|
||||
|
||||
The VisDrone dataset is widely used for training and evaluating deep learning models in drone-based computer vision tasks such as object detection, object tracking, and crowd counting. The dataset's diverse set of sensor data, object annotations, and attributes make it a valuable resource for researchers and practitioners in the field of drone-based computer vision.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the Visdrone dataset, the `VisDrone.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VisDrone.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VisDrone.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/VisDrone.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/VisDrone.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='VisDrone.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=VisDrone.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
The VisDrone dataset contains a diverse set of images and videos captured by drone-mounted cameras. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Task 1**: Object detection in images - This image demonstrates an example of object detection in images, where objects are annotated with bounding boxes. The dataset provides a wide variety of images taken from different locations, environments, and densities to facilitate the development of models for this task.
|
||||
|
||||
The example showcases the variety and complexity of the data in the VisDrone dataset and highlights the importance of high-quality sensor data for drone-based computer vision tasks.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the VisDrone dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@ARTICLE{9573394,
|
||||
author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},
|
||||
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
|
||||
title={Detection and Tracking Meet Drones Challenge},
|
||||
year={2021},
|
||||
volume={},
|
||||
number={},
|
||||
pages={1-1},
|
||||
doi={10.1109/TPAMI.2021.3119563}}
|
||||
```
|
||||
|
||||
We would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset).
|
||||
95
docs/en/datasets/detect/voc.md
Normal file
95
docs/en/datasets/detect/voc.md
Normal file
|
|
@ -0,0 +1,95 @@
|
|||
---
|
||||
comments: true
|
||||
description: A complete guide to the PASCAL VOC dataset used for object detection, segmentation and classification tasks with relevance to YOLO model training.
|
||||
keywords: Ultralytics, PASCAL VOC dataset, object detection, segmentation, image classification, YOLO, model training, VOC.yaml, deep learning
|
||||
---
|
||||
|
||||
# VOC Dataset
|
||||
|
||||
The [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a well-known object detection, segmentation, and classification dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and classification tasks.
|
||||
|
||||
## Key Features
|
||||
|
||||
- VOC dataset includes two main challenges: VOC2007 and VOC2012.
|
||||
- The dataset comprises 20 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as boats, sofas, and dining tables.
|
||||
- Annotations include object bounding boxes and class labels for object detection and classification tasks, and segmentation masks for the segmentation tasks.
|
||||
- VOC provides standardized evaluation metrics like mean Average Precision (mAP) for object detection and classification, making it suitable for comparing model performance.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The VOC dataset is split into three subsets:
|
||||
|
||||
1. **Train**: This subset contains images for training object detection, segmentation, and classification models.
|
||||
2. **Validation**: This subset has images used for validation purposes during model training.
|
||||
3. **Test**: This subset consists of images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [PASCAL VOC evaluation server](http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php) for performance evaluation.
|
||||
|
||||
## Applications
|
||||
|
||||
The VOC dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and image classification. The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the VOC dataset, the `VOC.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VOC.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VOC.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/VOC.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/VOC.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='VOC.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from
|
||||
a pretrained *.pt model
|
||||
yolo detect train data=VOC.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Images and Annotations
|
||||
|
||||
The VOC dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
|
||||
|
||||
The example showcases the variety and complexity of the images in the VOC dataset and the benefits of using mosaicing during the training process.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the VOC dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{everingham2010pascal,
|
||||
title={The PASCAL Visual Object Classes (VOC) Challenge},
|
||||
author={Mark Everingham and Luc Van Gool and Christopher K. I. Williams and John Winn and Andrew Zisserman},
|
||||
year={2010},
|
||||
eprint={0909.5206},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/).
|
||||
97
docs/en/datasets/detect/xview.md
Normal file
97
docs/en/datasets/detect/xview.md
Normal file
|
|
@ -0,0 +1,97 @@
|
|||
---
|
||||
comments: true
|
||||
description: Explore xView, a large-scale, high resolution satellite imagery dataset for object detection. Dive into dataset structure, usage examples & its potential applications.
|
||||
keywords: Ultralytics, YOLO, computer vision, xView dataset, satellite imagery, object detection, overhead imagery, training, deep learning, dataset YAML
|
||||
---
|
||||
|
||||
# xView Dataset
|
||||
|
||||
The [xView](http://xviewdataset.org/) dataset is one of the largest publicly available datasets of overhead imagery, containing images from complex scenes around the world annotated using bounding boxes. The goal of the xView dataset is to accelerate progress in four computer vision frontiers:
|
||||
|
||||
1. Reduce minimum resolution for detection.
|
||||
2. Improve learning efficiency.
|
||||
3. Enable discovery of more object classes.
|
||||
4. Improve detection of fine-grained classes.
|
||||
|
||||
xView builds on the success of challenges like Common Objects in Context (COCO) and aims to leverage computer vision to analyze the growing amount of available imagery from space in order to understand the visual world in new ways and address a range of important applications.
|
||||
|
||||
## Key Features
|
||||
|
||||
- xView contains over 1 million object instances across 60 classes.
|
||||
- The dataset has a resolution of 0.3 meters, providing higher resolution imagery than most public satellite imagery datasets.
|
||||
- xView features a diverse collection of small, rare, fine-grained, and multi-type objects with bounding box annotation.
|
||||
- Comes with a pre-trained baseline model using the TensorFlow object detection API and an example for PyTorch.
|
||||
|
||||
## Dataset Structure
|
||||
|
||||
The xView dataset is composed of satellite images collected from WorldView-3 satellites at a 0.3m ground sample distance. It contains over 1 million objects across 60 classes in over 1,400 km² of imagery.
|
||||
|
||||
## Applications
|
||||
|
||||
The xView dataset is widely used for training and evaluating deep learning models for object detection in overhead imagery. The dataset's diverse set of object classes and high-resolution imagery make it a valuable resource for researchers and practitioners in the field of computer vision, especially for satellite imagery analysis.
|
||||
|
||||
## Dataset YAML
|
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the xView dataset, the `xView.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/xView.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/xView.yaml).
|
||||
|
||||
!!! example "ultralytics/cfg/datasets/xView.yaml"
|
||||
|
||||
```yaml
|
||||
--8<-- "ultralytics/cfg/datasets/xView.yaml"
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
To train a model on the xView dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
|
||||
|
||||
!!! example "Train Example"
|
||||
|
||||
=== "Python"
|
||||
|
||||
```python
|
||||
from ultralytics import YOLO
|
||||
|
||||
# Load a model
|
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||
|
||||
# Train the model
|
||||
results = model.train(data='xView.yaml', epochs=100, imgsz=640)
|
||||
```
|
||||
|
||||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=xView.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
## Sample Data and Annotations
|
||||
|
||||
The xView dataset contains high-resolution satellite images with a diverse set of objects annotated using bounding boxes. Here are some examples of data from the dataset, along with their corresponding annotations:
|
||||
|
||||

|
||||
|
||||
- **Overhead Imagery**: This image demonstrates an example of object detection in overhead imagery, where objects are annotated with bounding boxes. The dataset provides high-resolution satellite images to facilitate the development of models for this task.
|
||||
|
||||
The example showcases the variety and complexity of the data in the xView dataset and highlights the importance of high-quality satellite imagery for object detection tasks.
|
||||
|
||||
## Citations and Acknowledgments
|
||||
|
||||
If you use the xView dataset in your research or development work, please cite the following paper:
|
||||
|
||||
!!! note ""
|
||||
|
||||
=== "BibTeX"
|
||||
|
||||
```bibtex
|
||||
@misc{lam2018xview,
|
||||
title={xView: Objects in Context in Overhead Imagery},
|
||||
author={Darius Lam and Richard Kuzma and Kevin McGee and Samuel Dooley and Michael Laielli and Matthew Klaric and Yaroslav Bulatov and Brendan McCord},
|
||||
year={2018},
|
||||
eprint={1802.07856},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CV}
|
||||
}
|
||||
```
|
||||
|
||||
We would like to acknowledge the [Defense Innovation Unit](https://www.diu.mil/) (DIU) and the creators of the xView dataset for their valuable contribution to the computer vision research community. For more information about the xView dataset and its creators, visit the [xView dataset website](http://xviewdataset.org/).
|
||||
Loading…
Add table
Add a link
Reference in a new issue