Update YOLOv3 and YOLOv5 YAMLs (#7574)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com>
This commit is contained in:
parent
596c068b18
commit
d762496989
51 changed files with 284 additions and 304 deletions
|
|
@ -10,7 +10,7 @@ The [Argoverse](https://www.argoverse.org/) dataset is a collection of data desi
|
|||
|
||||
!!! Note
|
||||
|
||||
The Argoverse dataset *.zip file required for training was removed from Amazon S3 after the shutdown of Argo AI by Ford, but we have made it available for manual download on [Google Drive](https://drive.google.com/file/d/1st9qW3BeIwQsnR0t8mRpvbsSWIo16ACi/view?usp=drive_link).
|
||||
The Argoverse dataset `*.zip` file required for training was removed from Amazon S3 after the shutdown of Argo AI by Ford, but we have made it available for manual download on [Google Drive](https://drive.google.com/file/d/1st9qW3BeIwQsnR0t8mRpvbsSWIo16ACi/view?usp=drive_link).
|
||||
|
||||
## Key Features
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ Training a robust and accurate object detection model requires a comprehensive d
|
|||
|
||||
### Ultralytics YOLO format
|
||||
|
||||
The Ultralytics YOLO format is a dataset configuration format that allows you to define the dataset root directory, the relative paths to training/validation/testing image directories or *.txt files containing image paths, and a dictionary of class names. Here is an example:
|
||||
The Ultralytics YOLO format is a dataset configuration format that allows you to define the dataset root directory, the relative paths to training/validation/testing image directories or `*.txt` files containing image paths, and a dictionary of class names. Here is an example:
|
||||
|
||||
```yaml
|
||||
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||
|
|
|
|||
|
|
@ -58,8 +58,7 @@ To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of
|
|||
=== "CLI"
|
||||
|
||||
```bash
|
||||
# Start training from
|
||||
a pretrained *.pt model
|
||||
# Start training from a pretrained *.pt model
|
||||
yolo detect train data=VOC.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -87,7 +87,7 @@ Contributing a new dataset involves several steps to ensure that it aligns well
|
|||
|
||||
2. **Annotate Images**: Annotate these images with bounding boxes, segments, or keypoints, depending on the task.
|
||||
|
||||
3. **Export Annotations**: Convert these annotations into the YOLO *.txt file format which Ultralytics supports.
|
||||
3. **Export Annotations**: Convert these annotations into the YOLO `*.txt` file format which Ultralytics supports.
|
||||
|
||||
4. **Organize Dataset**: Arrange your dataset into the correct folder structure. You should have `train/` and `val/` top-level directories, and within each, an `images/` and `labels/` subdirectory.
|
||||
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
## Recipe Walk Through
|
||||
|
||||
1. Begin with the necessary imports
|
||||
1. Begin with the necessary imports
|
||||
|
||||
```py
|
||||
from pathlib import Path
|
||||
|
|
@ -28,9 +28,9 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
See the Ultralytics [Quickstart](../quickstart.md/#install-ultralytics) Installation section for a quick walkthrough on installing the required libraries.
|
||||
|
||||
---
|
||||
***
|
||||
|
||||
2. Load a model and run `predict()` method on a source.
|
||||
2. Load a model and run `predict()` method on a source.
|
||||
|
||||
```py
|
||||
from ultralytics import YOLO
|
||||
|
|
@ -55,11 +55,11 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
For additional information about Segmentation Models, visit the [Segment Task](../tasks/segment.md#models) page. To learn more about `predict()` method, see [Predict Mode](../modes/predict.md) section of the Documentation.
|
||||
|
||||
---
|
||||
***
|
||||
|
||||
3. Now iterate over the results and the contours. For workflows that want to save an image to file, the source image `base-name` and the detection `class-label` are retrieved for later use (optional).
|
||||
3. Now iterate over the results and the contours. For workflows that want to save an image to file, the source image `base-name` and the detection `class-label` are retrieved for later use (optional).
|
||||
|
||||
``` { .py .annotate }
|
||||
```{ .py .annotate }
|
||||
# (2) Iterate detection results (helpful for multiple images)
|
||||
for r in res:
|
||||
img = np.copy(r.orig_img)
|
||||
|
|
@ -79,13 +79,13 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
A single image will only iterate the first loop once. A single image with only a single detection will iterate each loop _only_ once.
|
||||
|
||||
---
|
||||
***
|
||||
|
||||
4. Start with generating a binary mask from the source image and then draw a filled contour onto the mask. This will allow the object to be isolated from the other parts of the image. An example from `bus.jpg` for one of the detected `person` class objects is shown on the right.
|
||||
4. Start with generating a binary mask from the source image and then draw a filled contour onto the mask. This will allow the object to be isolated from the other parts of the image. An example from `bus.jpg` for one of the detected `person` class objects is shown on the right.
|
||||
|
||||
{ width="240", align="right" }
|
||||
|
||||
``` { .py .annotate }
|
||||
```{ .py .annotate }
|
||||
# Create binary mask
|
||||
b_mask = np.zeros(img.shape[:2], np.uint8)
|
||||
|
||||
|
|
@ -116,7 +116,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
<summary> Expand to understand what is happening when defining the <code>contour</code> variable.</summary>
|
||||
<p>
|
||||
|
||||
- `c.masks.xy` :: Provides the coordinates of the mask contour points in the format `(x, y)`. For more details, refer to the [Masks Section from Predict Mode](../modes/predict.md#masks).
|
||||
- `c.masks.xy` :: Provides the coordinates of the mask contour points in the format `(x, y)`. For more details, refer to the [Masks Section from Predict Mode](../modes/predict.md#masks).
|
||||
|
||||
- `.pop()` :: As `masks.xy` is a list containing a single element, this element is extracted using the `pop()` method.
|
||||
|
||||
|
|
@ -143,9 +143,9 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
</details>
|
||||
<p></p>
|
||||
|
||||
---
|
||||
***
|
||||
|
||||
5. Next the there are 2 options for how to move forward with the image from this point and a subsequent option for each.
|
||||
5. Next the there are 2 options for how to move forward with the image from this point and a subsequent option for each.
|
||||
|
||||
### Object Isolation Options
|
||||
|
||||
|
|
@ -256,9 +256,9 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
This is a built in feature for the Ultralytics library. See the `save_crop` argument for [Predict Mode Inference Arguments](../modes/predict.md/#inference-arguments) for details.
|
||||
|
||||
---
|
||||
***
|
||||
|
||||
6. <u>What to do next is entirely left to you as the developer.</u> A basic example of one possible next step (saving the image to file for future use) is shown.
|
||||
6. <u>What to do next is entirely left to you as the developer.</u> A basic example of one possible next step (saving the image to file for future use) is shown.
|
||||
|
||||
- **NOTE:** this step is optional and can be skipped if not required for your specific use case.
|
||||
|
||||
|
|
@ -275,7 +275,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
|
|||
|
||||
Here, all steps from the previous section are combined into a single block of code. For repeated use, it would be optimal to define a function to do some or all commands contained in the `for`-loops, but that is an exercise left to the reader.
|
||||
|
||||
``` { .py .annotate }
|
||||
```{ .py .annotate }
|
||||
from pathlib import Path
|
||||
|
||||
import cv2 as cv
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: YOLOv8, Deployment, PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, Co
|
|||
|
||||
## Introduction
|
||||
|
||||
*Setting the Scene:* You've come a long way on your journey with YOLOv8. You've diligently collected data, meticulously annotated it, and put in the hours to train and rigorously evaluate your custom YOLOv8 model. Now, it’s time to put your model to work for your specific application, use case, or project. But there's a critical decision that stands before you: how to export and deploy your model effectively.
|
||||
You've come a long way on your journey with YOLOv8. You've diligently collected data, meticulously annotated it, and put in the hours to train and rigorously evaluate your custom YOLOv8 model. Now, it’s time to put your model to work for your specific application, use case, or project. But there's a critical decision that stands before you: how to export and deploy your model effectively.
|
||||
|
||||
This guide walks you through YOLOv8’s deployment options and the essential factors to consider to choose the right option for your project.
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: Ultralytics, YOLOv8, Object Detection, Object Blurring, Privacy Protec
|
|||
|
||||
## What is Object Blurring?
|
||||
|
||||
Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves applying a blurring effect to specific detected objects in an image or video. This can be achieved using the YOLOv8 model capabilities to identify and manipulate objects within a given scene.
|
||||
Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves applying a blurring effect to specific detected objects in an image or video. This can be achieved using the YOLOv8 model capabilities to identify and manipulate objects within a given scene.
|
||||
|
||||
## Advantages of Object Blurring?
|
||||
|
||||
|
|
|
|||
|
|
@ -56,6 +56,6 @@ We hope that the resources here will help you get the most out of HUB. Please br
|
|||
- [**Models: Training and Exporting**](models.md). Train YOLOv5 and YOLOv8 models on your custom datasets and export them to various formats for deployment.
|
||||
- [**Integrations: Options**](integrations.md). Explore different integration options for your trained models, such as TensorFlow, ONNX, OpenVINO, CoreML, and PaddlePaddle.
|
||||
- [**Ultralytics HUB App**](app/index.md). Learn about the Ultralytics App for iOS and Android, which allows you to run models directly on your mobile device.
|
||||
* [**iOS**](app/ios.md). Learn about YOLO CoreML models accelerated on Apple's Neural Engine on iPhones and iPads.
|
||||
* [**Android**](app/android.md). Explore TFLite acceleration on mobile devices.
|
||||
- [**iOS**](app/ios.md). Learn about YOLO CoreML models accelerated on Apple's Neural Engine on iPhones and iPads.
|
||||
- [**Android**](app/android.md). Explore TFLite acceleration on mobile devices.
|
||||
- [**Inference API**](inference_api.md). Understand how to use the Inference API for running your trained models in the cloud to generate predictions.
|
||||
|
|
|
|||
|
|
@ -56,7 +56,7 @@ import comet_ml
|
|||
comet_ml.init(project_name="comet-example-yolov8-coco128")
|
||||
```
|
||||
|
||||
*Note:* If you are using a Google Colab notebook, the code above will prompt you to enter your API key for initialization.
|
||||
If you are using a Google Colab notebook, the code above will prompt you to enter your API key for initialization.
|
||||
|
||||
## Usage
|
||||
|
||||
|
|
|
|||
|
|
@ -122,17 +122,20 @@ FastSAM is also available directly from the [https://github.com/CASIA-IVA-Lab/Fa
|
|||
### Installation
|
||||
|
||||
1. Clone the FastSAM repository:
|
||||
|
||||
```shell
|
||||
git clone https://github.com/CASIA-IVA-Lab/FastSAM.git
|
||||
```
|
||||
|
||||
2. Create and activate a Conda environment with Python 3.9:
|
||||
|
||||
```shell
|
||||
conda create -n FastSAM python=3.9
|
||||
conda activate FastSAM
|
||||
```
|
||||
|
||||
3. Navigate to the cloned repository and install the required packages:
|
||||
|
||||
```shell
|
||||
cd FastSAM
|
||||
pip install -r requirements.txt
|
||||
|
|
@ -149,25 +152,28 @@ FastSAM is also available directly from the [https://github.com/CASIA-IVA-Lab/Fa
|
|||
|
||||
2. Use FastSAM for inference. Example commands:
|
||||
|
||||
- Segment everything in an image:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg
|
||||
```
|
||||
- Segment everything in an image:
|
||||
|
||||
- Segment specific objects using text prompt:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
|
||||
```
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg
|
||||
```
|
||||
|
||||
- Segment objects within a bounding box (provide box coordinates in xywh format):
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --box_prompt "[570,200,230,400]"
|
||||
```
|
||||
- Segment specific objects using text prompt:
|
||||
|
||||
- Segment objects near specific points:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
|
||||
```
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
|
||||
```
|
||||
|
||||
- Segment objects within a bounding box (provide box coordinates in xywh format):
|
||||
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --box_prompt "[570,200,230,400]"
|
||||
```
|
||||
|
||||
- Segment objects near specific points:
|
||||
```shell
|
||||
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
|
||||
```
|
||||
|
||||
Additionally, you can try FastSAM through a [Colab demo](https://colab.research.google.com/drive/1oX14f6IneGGw612WgVlAiy91UHwFAvr9?usp=sharing) or on the [HuggingFace web demo](https://huggingface.co/spaces/An-619/FastSAM) for a visual experience.
|
||||
|
||||
|
|
|
|||
|
|
@ -89,4 +89,4 @@ If you use Baidu's RT-DETR in your research or development work, please cite the
|
|||
|
||||
We would like to acknowledge Baidu and the [PaddlePaddle](https://github.com/PaddlePaddle/PaddleDetection) team for creating and maintaining this valuable resource for the computer vision community. Their contribution to the field with the development of the Vision Transformers-based real-time object detector, RT-DETR, is greatly appreciated.
|
||||
|
||||
*Keywords: RT-DETR, Transformer, ViT, Vision Transformers, Baidu RT-DETR, PaddlePaddle, Paddle Paddle RT-DETR, real-time object detection, Vision Transformers-based object detection, pre-trained PaddlePaddle RT-DETR models, Baidu's RT-DETR usage, Ultralytics Python API*
|
||||
_Keywords: RT-DETR, Transformer, ViT, Vision Transformers, Baidu RT-DETR, PaddlePaddle, Paddle Paddle RT-DETR, real-time object detection, Vision Transformers-based object detection, pre-trained PaddlePaddle RT-DETR models, Baidu's RT-DETR usage, Ultralytics Python API_
|
||||
|
|
|
|||
|
|
@ -222,4 +222,4 @@ If you find SAM useful in your research or development work, please consider cit
|
|||
|
||||
We would like to express our gratitude to Meta AI for creating and maintaining this valuable resource for the computer vision community.
|
||||
|
||||
*keywords: Segment Anything, Segment Anything Model, SAM, Meta SAM, image segmentation, promptable segmentation, zero-shot performance, SA-1B dataset, advanced architecture, auto-annotation, Ultralytics, pre-trained models, SAM base, SAM large, instance segmentation, computer vision, AI, artificial intelligence, machine learning, data annotation, segmentation masks, detection model, YOLO detection model, bibtex, Meta AI.*
|
||||
_keywords: Segment Anything, Segment Anything Model, SAM, Meta SAM, image segmentation, promptable segmentation, zero-shot performance, SA-1B dataset, advanced architecture, auto-annotation, Ultralytics, pre-trained models, SAM base, SAM large, instance segmentation, computer vision, AI, artificial intelligence, machine learning, data annotation, segmentation masks, detection model, YOLO detection model, bibtex, Meta AI._
|
||||
|
|
|
|||
|
|
@ -117,4 +117,4 @@ If you employ YOLO-NAS in your research or development work, please cite SuperGr
|
|||
|
||||
We express our gratitude to Deci AI's [SuperGradients](https://github.com/Deci-AI/super-gradients/) team for their efforts in creating and maintaining this valuable resource for the computer vision community. We believe YOLO-NAS, with its innovative architecture and superior object detection capabilities, will become a critical tool for developers and researchers alike.
|
||||
|
||||
*Keywords: YOLO-NAS, Deci AI, object detection, deep learning, neural architecture search, Ultralytics Python API, YOLO model, SuperGradients, pre-trained models, quantization-friendly basic block, advanced training schemes, post-training quantization, AutoNAC optimization, COCO, Objects365, Roboflow 100*
|
||||
_Keywords: YOLO-NAS, Deci AI, object detection, deep learning, neural architecture search, Ultralytics Python API, YOLO model, SuperGradients, pre-trained models, quantization-friendly basic block, advanced training schemes, post-training quantization, AutoNAC optimization, COCO, Objects365, Roboflow 100_
|
||||
|
|
|
|||
|
|
@ -761,7 +761,5 @@ Here's a Python script using OpenCV (`cv2`) and YOLOv8 to run inference on video
|
|||
This script will run predictions on each frame of the video, visualize the results, and display them in a window. The loop can be exited by pressing 'q'.
|
||||
|
||||
[car spare parts]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/a0f802a8-0776-44cf-8f17-93974a4a28a1
|
||||
|
||||
[football player detect]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/7d320e1f-fc57-4d7f-a691-78ee579c3442
|
||||
|
||||
[human fall detect]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/86437c4a-3227-4eee-90ef-9efb697bdb43
|
||||
|
|
|
|||
|
|
@ -354,7 +354,5 @@ To initiate your contribution, please refer to our [Contributing Guide](https://
|
|||
Together, let's enhance the tracking capabilities of the Ultralytics YOLO ecosystem 🙏!
|
||||
|
||||
[fish track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/a5146d0f-bfa8-4e0a-b7df-3c1446cd8142
|
||||
|
||||
[people track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/93bb4ee2-77a0-4e4e-8eb6-eb8f527f0527
|
||||
|
||||
[vehicle track]: https://github.com/RizwanMunawar/ultralytics/assets/62513924/ee6e6038-383b-4f21-ac29-b2a1c7d386ab
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ keywords: Ultralytics, neural network, nn.modules.utils, bias_init_with_prob, in
|
|||
|
||||
<br><br>
|
||||
|
||||
## ::: ultralytics.nn.modules.utils.linear_init_
|
||||
## ::: ultralytics.nn.modules.utils.linear_init
|
||||
|
||||
<br><br>
|
||||
|
||||
|
|
|
|||
|
|
@ -18,7 +18,6 @@ The output of an oriented object detector is a set of rotated bounding boxes tha
|
|||
|
||||
YOLOv8 OBB models use the `-obb` suffix, i.e. `yolov8n-obb.pt` and are pretrained on [DOTAv1](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/DOTAv1.yaml).
|
||||
|
||||
|
||||
| Ships Detection using OBB | Vehicle Detection using OBB |
|
||||
|:-------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------:|
|
||||
|  | 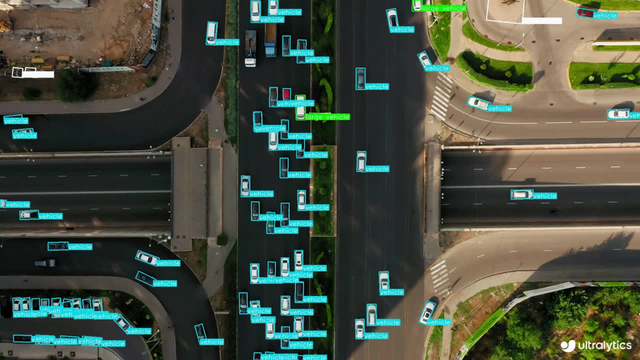 |
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
---
|
||||
comments: true
|
||||
description: 'Learn how to use Ultralytics YOLO through Command Line: train models, run predictions and exports models to different formats easily using terminal commands.'
|
||||
description: Learn how to use Ultralytics YOLO through Command Line: train models, run predictions and exports models to different formats easily using terminal commands.
|
||||
keywords: Ultralytics, YOLO, CLI, train, validation, prediction, command line interface, YOLO CLI, YOLO terminal, model training, prediction, exporting
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -161,8 +161,8 @@ The objectness losses of the three prediction layers (`P3`, `P4`, `P5`) are weig
|
|||
|
||||
The YOLOv5 architecture makes some important changes to the box prediction strategy compared to earlier versions of YOLO. In YOLOv2 and YOLOv3, the box coordinates were directly predicted using the activation of the last layer.
|
||||
|
||||
+c_x)
|
||||
+c_y)
|
||||
+c_x>)
|
||||
+c_y>)
|
||||

|
||||

|
||||
|
||||
|
|
@ -172,10 +172,10 @@ However, in YOLOv5, the formula for predicting the box coordinates has been upda
|
|||
|
||||
The revised formulas for calculating the predicted bounding box are as follows:
|
||||
|
||||
-0.5)+c_x)
|
||||
-0.5)+c_y)
|
||||
)^2)
|
||||
)^2)
|
||||
-0.5)+c_x>)
|
||||
-0.5)+c_y>)
|
||||
)^2>)
|
||||
)^2>)
|
||||
|
||||
Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5). Therefore, offset can easily get 0 or 1.
|
||||
|
||||
|
|
@ -197,11 +197,11 @@ This process follows these steps:
|
|||
|
||||

|
||||
|
||||
)
|
||||
>)
|
||||
|
||||
)
|
||||
>)
|
||||
|
||||
)
|
||||
>)
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -77,7 +77,7 @@ Export in `YOLOv5 Pytorch` format, then copy the snippet into your training scri
|
|||
|
||||
### 2.1 Create `dataset.yaml`
|
||||
|
||||
[COCO128](https://www.kaggle.com/ultralytics/coco128) is an example small tutorial dataset composed of the first 128 images in [COCO](https://cocodataset.org/) train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of overfitting. [data/coco128.yaml](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), shown below, is the dataset config file that defines 1) the dataset root directory `path` and relative paths to `train` / `val` / `test` image directories (or *.txt files with image paths) and 2) a class `names` dictionary:
|
||||
[COCO128](https://www.kaggle.com/ultralytics/coco128) is an example small tutorial dataset composed of the first 128 images in [COCO](https://cocodataset.org/) train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of overfitting. [data/coco128.yaml](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), shown below, is the dataset config file that defines 1) the dataset root directory `path` and relative paths to `train` / `val` / `test` image directories (or `*.txt` files with image paths) and 2) a class `names` dictionary:
|
||||
|
||||
```yaml
|
||||
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||
|
|
@ -114,7 +114,7 @@ The label file corresponding to the above image contains 2 persons (class `0`) a
|
|||
|
||||
### 2.3 Organize Directories
|
||||
|
||||
Organize your train and val images and labels according to the example below. YOLOv5 assumes `/coco128` is inside a `/datasets` directory **next to** the `/yolov5` directory. **YOLOv5 locates labels automatically for each image** by replacing the last instance of `/images/` in each image path with `/labels/`. For example:
|
||||
Organize your train and val images and labels according to the example below. YOLOv5 assumes `/coco128` is inside a `/datasets` directory **next to** the `/yolov5` directory. **YOLOv5 locates labels automatically for each image** by replacing the last instance of `/images/` in each image path with `/labels/`. For example:
|
||||
|
||||
```bash
|
||||
../datasets/coco128/images/im0.jpg # image
|
||||
|
|
|
|||
|
|
@ -60,43 +60,42 @@ model.24.m.2.bias
|
|||
Looking at the model architecture we can see that the model backbone is layers 0-9:
|
||||
|
||||
```yaml
|
||||
# YOLOv5 backbone
|
||||
# YOLOv5 v6.0 backbone
|
||||
backbone:
|
||||
# [from, number, module, args]
|
||||
[[-1, 1, Focus, [64, 3]], # 0-P1/2
|
||||
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
|
||||
[-1, 3, BottleneckCSP, [128]],
|
||||
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
|
||||
[-1, 9, BottleneckCSP, [256]],
|
||||
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
|
||||
[-1, 9, BottleneckCSP, [512]],
|
||||
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
|
||||
[-1, 1, SPP, [1024, [5, 9, 13]]],
|
||||
[-1, 3, BottleneckCSP, [1024, False]], # 9
|
||||
]
|
||||
- [-1, 1, Conv, [64, 6, 2, 2]] # 0-P1/2
|
||||
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
|
||||
- [-1, 3, C3, [128]]
|
||||
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
|
||||
- [-1, 6, C3, [256]]
|
||||
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
|
||||
- [-1, 9, C3, [512]]
|
||||
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
|
||||
- [-1, 3, C3, [1024]]
|
||||
- [-1, 1, SPPF, [1024, 5]] # 9
|
||||
|
||||
# YOLOv5 head
|
||||
|
||||
# YOLOv5 v6.0 head
|
||||
head:
|
||||
[[-1, 1, Conv, [512, 1, 1]],
|
||||
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
||||
[[-1, 6], 1, Concat, [1]], # cat backbone P4
|
||||
[-1, 3, BottleneckCSP, [512, False]], # 13
|
||||
- [-1, 1, Conv, [512, 1, 1]]
|
||||
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
|
||||
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
|
||||
- [-1, 3, C3, [512, False]] # 13
|
||||
|
||||
[-1, 1, Conv, [256, 1, 1]],
|
||||
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
||||
[[-1, 4], 1, Concat, [1]], # cat backbone P3
|
||||
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
|
||||
- [-1, 1, Conv, [256, 1, 1]]
|
||||
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
|
||||
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
|
||||
- [-1, 3, C3, [256, False]] # 17 (P3/8-small)
|
||||
|
||||
[-1, 1, Conv, [256, 3, 2]],
|
||||
[[-1, 14], 1, Concat, [1]], # cat head P4
|
||||
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
|
||||
- [-1, 1, Conv, [256, 3, 2]]
|
||||
- [[-1, 14], 1, Concat, [1]] # cat head P4
|
||||
- [-1, 3, C3, [512, False]] # 20 (P4/16-medium)
|
||||
|
||||
[-1, 1, Conv, [512, 3, 2]],
|
||||
[[-1, 10], 1, Concat, [1]], # cat head P5
|
||||
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
|
||||
- [-1, 1, Conv, [512, 3, 2]]
|
||||
- [[-1, 10], 1, Concat, [1]] # cat head P5
|
||||
- [-1, 3, C3, [1024, False]] # 23 (P5/32-large)
|
||||
|
||||
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
|
||||
]
|
||||
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
|
||||
```
|
||||
|
||||
so we can define the freeze list to contain all modules with 'model.0.' - 'model.9.' in their names:
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue