Add https://youtu.be/S_J-Dyw15i0 to docs (#13099)
This commit is contained in:
parent
f3bf77b416
commit
654c37f09b
2 changed files with 11 additions and 2 deletions
|
|
@ -130,6 +130,16 @@ When the training starts, you can click **Done** and monitor the training progre
|
|||
|
||||
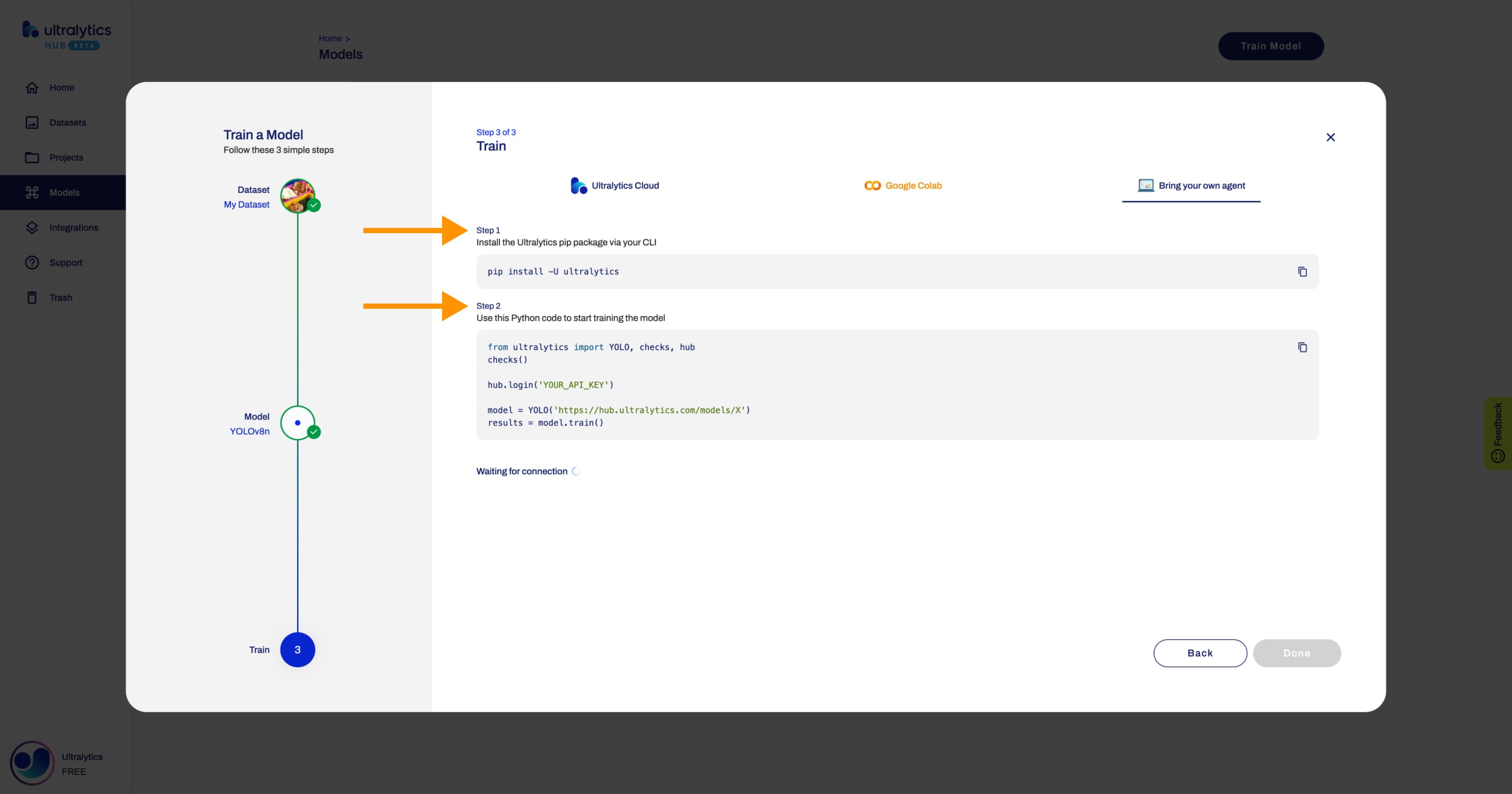
#### c. Bring your own agent
|
||||
|
||||
<p align="center">
|
||||
<iframe loading="lazy" width="720" height="405" src="https://www.youtube.com/embed/S_J-Dyw15i0"
|
||||
title="YouTube video player" frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share"
|
||||
allowfullscreen>
|
||||
</iframe>
|
||||
<br>
|
||||
<strong>Watch:</strong> Bring your Own Agent model training using Ultralytics HUB
|
||||
</p>
|
||||
|
||||
To start training your model using your own agent, follow the instructions shown in the [Ultralytics HUB](https://bit.ly/ultralytics_hub) **Train Model** dialog.
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -7,8 +7,7 @@ keywords: RT-DETR, Baidu, Vision Transformers, object detection, real-time perfo
|
|||
# Baidu's RT-DETR: A Vision Transformer-Based Real-Time Object Detector
|
||||
|
||||
## Overview
|
||||
|
||||
Real-Time Detection Transformer (RT-DETR), developed by Baidu, is a cutting-edge end-to-end object detector that provides real-time performance while maintaining high accuracy. It leverages the power of Vision Transformers (ViT) to efficiently process multiscale features by decoupling intra-scale interaction and cross-scale fusion. RT-DETR is highly adaptable, supporting flexible adjustment of inference speed using different decoder layers without retraining. The model excels on accelerated backends like CUDA with TensorRT, outperforming many other real-time object detectors.
|
||||
Real-Time Detection Transformer (RT-DETR), developed by Baidu, is a cutting-edge end-to-end object detector that provides real-time performance while maintaining high accuracy. It is based on the idea of DETR (the NMS-free framework), meanwhile introducing conv-based backbone and an efficient hybrid encoder to gain real-time speed. RT-DETR efficiently processes multiscale features by decoupling intra-scale interaction and cross-scale fusion. The model is highly adaptable, supporting flexible adjustment of inference speed using different decoder layers without retraining. RT-DETR excels on accelerated backends like CUDA with TensorRT, outperforming many other real-time object detectors.
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue