Remove image "?" args (#15891)
Signed-off-by: UltralyticsAssistant <web@ultralytics.com> Co-authored-by: UltralyticsAssistant <web@ultralytics.com>
This commit is contained in:
parent
40fb3e9bde
commit
5f01e15e7b
6 changed files with 9 additions and 9 deletions
|
|
@ -4,7 +4,7 @@ description: Discover MobileSAM, a lightweight and fast image segmentation model
|
|||
keywords: MobileSAM, image segmentation, lightweight model, fast segmentation, mobile applications, SAM, ViT encoder, Tiny-ViT, Ultralytics
|
||||
---
|
||||
|
||||

|
||||

|
||||
|
||||
# Mobile Segment Anything (MobileSAM)
|
||||
|
||||
|
|
@ -53,9 +53,9 @@ Here is the comparison of the whole pipeline:
|
|||
|
||||
The performance of MobileSAM and the original SAM are demonstrated using both a point and a box as prompts.
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
With its superior performance, MobileSAM is approximately 5 times smaller and 7 times faster than the current FastSAM. More details are available at the [MobileSAM project page](https://github.com/ChaoningZhang/MobileSAM).
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ keywords: SAM 2, Segment Anything, video segmentation, image segmentation, promp
|
|||
|
||||
SAM 2, the successor to Meta's [Segment Anything Model (SAM)](sam.md), is a cutting-edge tool designed for comprehensive object segmentation in both images and videos. It excels in handling complex visual data through a unified, promptable model architecture that supports real-time processing and zero-shot generalization.
|
||||
|
||||

|
||||

|
||||
|
||||
## Key Features
|
||||
|
||||
|
|
@ -54,7 +54,7 @@ SAM 2 sets a new benchmark in the field, outperforming previous models on variou
|
|||
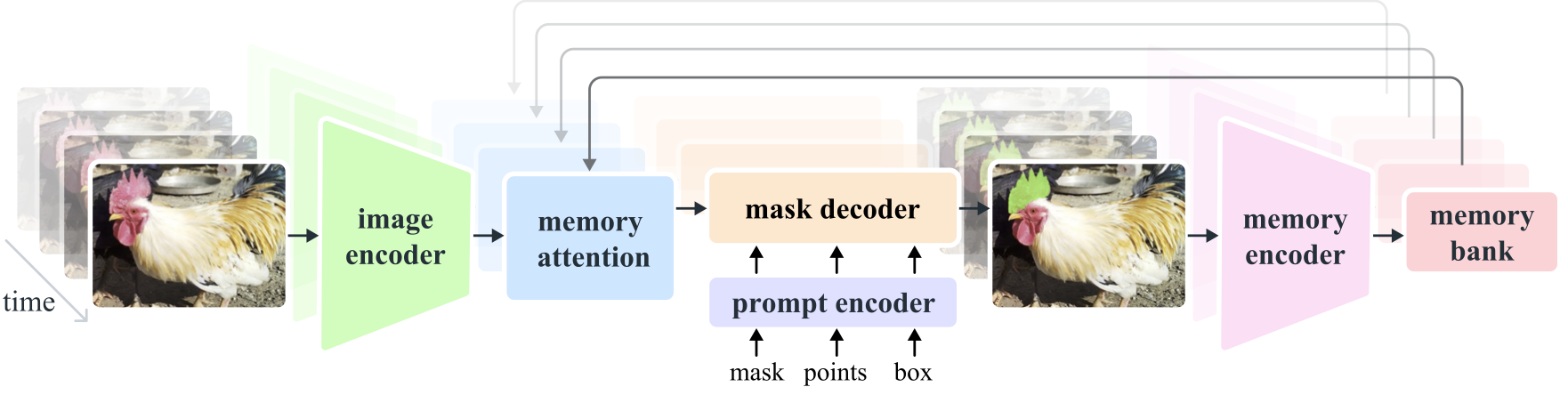
- **Memory Mechanism**: Includes a memory encoder, memory bank, and memory attention module. These components collectively store and utilize information from past frames, enabling the model to maintain consistent object tracking over time.
|
||||
- **Mask Decoder**: Generates the final segmentation masks based on the encoded image features and prompts. In video, it also uses memory context to ensure accurate tracking across frames.
|
||||
|
||||
|
||||

|
||||
|
||||
### Memory Mechanism and Occlusion Handling
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue