diff --git a/docs/en/models/rtdetr.md b/docs/en/models/rtdetr.md
index 382e79db..5cc9f094 100644
--- a/docs/en/models/rtdetr.md
+++ b/docs/en/models/rtdetr.md
@@ -8,7 +8,7 @@ keywords: RT-DETR, Baidu, Vision Transformer, real-time object detection, Paddle
## Overview
-Real-Time Detection Transformer (RT-DETR), developed by Baidu, is a cutting-edge end-to-end object detector that provides real-time performance while maintaining high [accuracy](https://www.ultralytics.com/glossary/accuracy). It is based on the idea of DETR (the NMS-free framework), meanwhile introducing conv-based backbone and an efficient hybrid encoder to gain real-time speed. RT-DETR efficiently processes multiscale features by decoupling intra-scale interaction and cross-scale fusion. The model is highly adaptable, supporting flexible adjustment of inference speed using different decoder layers without retraining. RT-DETR excels on accelerated backends like CUDA with TensorRT, outperforming many other real-time object detectors.
+Real-Time Detection Transformer (RT-DETR), developed by Baidu, is a cutting-edge end-to-end object detector that provides real-time performance while maintaining high [accuracy](https://www.ultralytics.com/glossary/accuracy). It is based on the idea of DETR (the NMS-free framework), meanwhile introducing conv-based [backbone](https://www.ultralytics.com/glossary/backbone) and an efficient hybrid encoder to gain real-time speed. RT-DETR efficiently processes multiscale features by decoupling intra-scale interaction and cross-scale fusion. The model is highly adaptable, supporting flexible adjustment of inference speed using different decoder layers without retraining. RT-DETR excels on accelerated backends like CUDA with TensorRT, outperforming many other real-time object detectors.
diff --git a/docs/en/models/sam-2.md b/docs/en/models/sam-2.md
index 4e95ec87..3193d5c7 100644
--- a/docs/en/models/sam-2.md
+++ b/docs/en/models/sam-2.md
@@ -66,7 +66,7 @@ SAM 2 sets a new benchmark in the field, outperforming previous models on variou
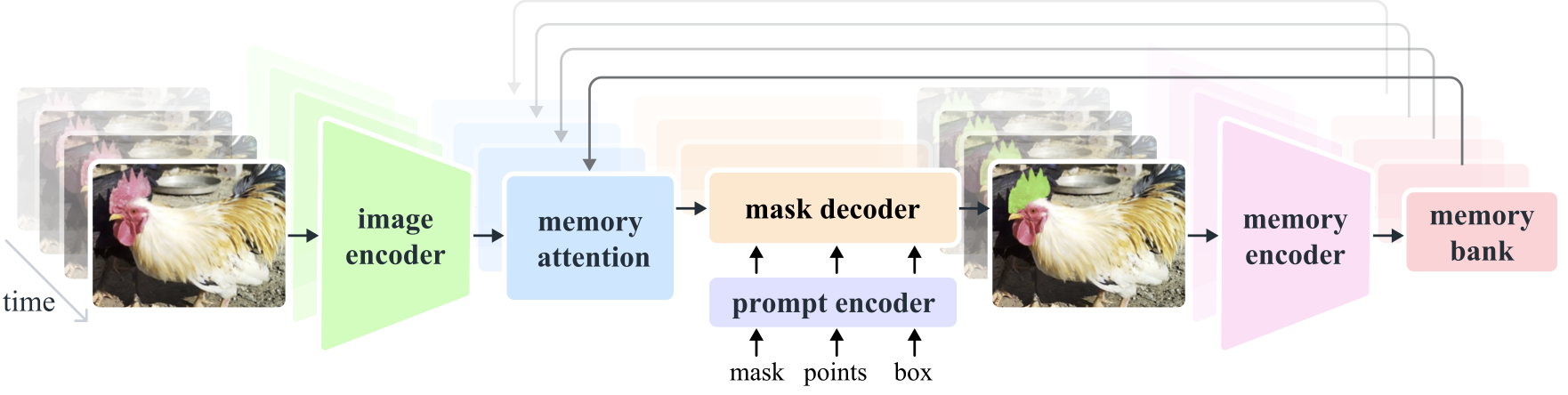
- **Image and Video Encoder**: Utilizes a [transformer](https://www.ultralytics.com/glossary/transformer)-based architecture to extract high-level features from both images and video frames. This component is responsible for understanding the visual content at each timestep.
- **Prompt Encoder**: Processes user-provided prompts (points, boxes, masks) to guide the segmentation task. This allows SAM 2 to adapt to user input and target specific objects within a scene.
-- **Memory Mechanism**: Includes a memory encoder, memory bank, and memory attention module. These components collectively store and utilize information from past frames, enabling the model to maintain consistent object tracking over time.
+- **Memory Mechanism**: Includes a memory encoder, memory bank, and memory attention module. These components collectively store and utilize information from past frames, enabling the model to maintain consistent [object tracking](https://www.ultralytics.com/glossary/object-tracking) over time.
- **Mask Decoder**: Generates the final segmentation masks based on the encoded image features and prompts. In video, it also uses memory context to ensure accurate tracking across frames.
@@ -228,14 +228,14 @@ SAM 2 can be utilized across a broad spectrum of tasks, including real-time vide
Here we compare Meta's smallest SAM 2 model, SAM2-t, with Ultralytics smallest segmentation model, [YOLOv8n-seg](../tasks/segment.md):
-| Model | Size
(MB) | Parameters
(M) | Speed (CPU)
(ms/im) |
-| ---------------------------------------------- | ----------------------- | ---------------------------- | --------------------------------- |
-| [Meta SAM-b](sam.md) | 375 | 93.7 | 161440 |
-| Meta SAM2-b | 162 | 80.8 | 121923 |
-| Meta SAM2-t | 78.1 | 38.9 | 85155 |
-| [MobileSAM](mobile-sam.md) | 40.7 | 10.1 | 98543 |
-| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 | 11.8 | 140 |
-| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7** (11.7x smaller) | **3.4** (11.4x less) | **79.5** (1071x faster) |
+| Model | Size
(MB) | Parameters
(M) | Speed (CPU)
(ms/im) |
+| ---------------------------------------------------------------------------------------------- | ----------------------- | ---------------------------- | --------------------------------- |
+| [Meta SAM-b](sam.md) | 375 | 93.7 | 161440 |
+| Meta SAM2-b | 162 | 80.8 | 121923 |
+| Meta SAM2-t | 78.1 | 38.9 | 85155 |
+| [MobileSAM](mobile-sam.md) | 40.7 | 10.1 | 98543 |
+| [FastSAM-s](fast-sam.md) with YOLOv8 [backbone](https://www.ultralytics.com/glossary/backbone) | 23.7 | 11.8 | 140 |
+| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7** (11.7x smaller) | **3.4** (11.4x less) | **79.5** (1071x faster) |
This comparison shows the order-of-magnitude differences in the model sizes and speeds between models. Whereas SAM presents unique capabilities for automatic segmenting, it is not a direct competitor to YOLOv8 segment models, which are smaller, faster and more efficient.
diff --git a/docs/en/models/sam.md b/docs/en/models/sam.md
index 15b6b442..e4695554 100644
--- a/docs/en/models/sam.md
+++ b/docs/en/models/sam.md
@@ -155,12 +155,12 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
Here we compare Meta's smallest SAM model, SAM-b, with Ultralytics smallest segmentation model, [YOLOv8n-seg](../tasks/segment.md):
-| Model | Size
(MB) | Parameters
(M) | Speed (CPU)
(ms/im) |
-| ---------------------------------------------- | ----------------------- | ---------------------------- | --------------------------------- |
-| Meta SAM-b | 358 | 94.7 | 51096 |
-| [MobileSAM](mobile-sam.md) | 40.7 | 10.1 | 46122 |
-| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 | 11.8 | 115 |
-| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7** (53.4x smaller) | **3.4** (27.9x less) | **59** (866x faster) |
+| Model | Size
(MB) | Parameters
(M) | Speed (CPU)
(ms/im) |
+| ---------------------------------------------------------------------------------------------- | ----------------------- | ---------------------------- | --------------------------------- |
+| Meta SAM-b | 358 | 94.7 | 51096 |
+| [MobileSAM](mobile-sam.md) | 40.7 | 10.1 | 46122 |
+| [FastSAM-s](fast-sam.md) with YOLOv8 [backbone](https://www.ultralytics.com/glossary/backbone) | 23.7 | 11.8 | 115 |
+| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7** (53.4x smaller) | **3.4** (27.9x less) | **59** (866x faster) |
This comparison shows the order-of-magnitude differences in the model sizes and speeds between models. Whereas SAM presents unique capabilities for automatic segmenting, it is not a direct competitor to YOLOv8 segment models, which are smaller, faster and more efficient.
diff --git a/docs/en/models/yolo-nas.md b/docs/en/models/yolo-nas.md
index 394bc831..312b5a0e 100644
--- a/docs/en/models/yolo-nas.md
+++ b/docs/en/models/yolo-nas.md
@@ -8,7 +8,7 @@ keywords: YOLO-NAS, Deci AI, object detection, deep learning, Neural Architectur
## Overview
-Developed by Deci AI, YOLO-NAS is a groundbreaking object detection foundational model. It is the product of advanced Neural Architecture Search technology, meticulously designed to address the limitations of previous YOLO models. With significant improvements in quantization support and [accuracy](https://www.ultralytics.com/glossary/accuracy)-latency trade-offs, YOLO-NAS represents a major leap in object detection.
+Developed by Deci AI, YOLO-NAS is a groundbreaking object detection foundational model. It is the product of advanced [Neural Architecture Search](https://www.ultralytics.com/glossary/neural-architecture-search-nas) technology, meticulously designed to address the limitations of previous YOLO models. With significant improvements in quantization support and [accuracy](https://www.ultralytics.com/glossary/accuracy)-latency trade-offs, YOLO-NAS represents a major leap in object detection.
 **Overview of YOLO-NAS.** YOLO-NAS employs quantization-aware blocks and selective quantization for optimal performance. The model, when converted to its INT8 quantized version, experiences a minimal precision drop, a significant improvement over other models. These advancements culminate in a superior architecture with unprecedented object detection capabilities and outstanding performance.
diff --git a/docs/en/models/yolo-world.md b/docs/en/models/yolo-world.md
index 2831fff6..5e485df6 100644
--- a/docs/en/models/yolo-world.md
+++ b/docs/en/models/yolo-world.md
@@ -166,7 +166,7 @@ Model validation on a dataset is streamlined as follows:
### Track Usage
-Object tracking with YOLO-World model on a video/images is streamlined as follows:
+[Object tracking](https://www.ultralytics.com/glossary/object-tracking) with YOLO-World model on a video/images is streamlined as follows:
!!! example
@@ -272,11 +272,11 @@ This approach provides a powerful means of customizing state-of-the-art object d
- Train data
-| Dataset | Type | Samples | Boxes | Annotation Files |
-| ----------------------------------------------------------------- | --------- | ------- | ----- | ------------------------------------------------------------------------------------------------------------------------------------------ |
-| [Objects365v1](https://opendatalab.com/OpenDataLab/Objects365_v1) | Detection | 609k | 9621k | [objects365_train.json](https://opendatalab.com/OpenDataLab/Objects365_v1) |
-| [GQA](https://downloads.cs.stanford.edu/nlp/data/gqa/images.zip) | Grounding | 621k | 3681k | [final_mixed_train_no_coco.json](https://huggingface.co/GLIPModel/GLIP/blob/main/mdetr_annotations/final_mixed_train_no_coco.json) |
-| [Flickr30k](https://shannon.cs.illinois.edu/DenotationGraph/) | Grounding | 149k | 641k | [final_flickr_separateGT_train.json](https://huggingface.co/GLIPModel/GLIP/blob/main/mdetr_annotations/final_flickr_separateGT_train.json) |
+| Dataset | Type | Samples | Boxes | Annotation Files |
+| ----------------------------------------------------------------- | ----------------------------------------------------------- | ------- | ----- | ------------------------------------------------------------------------------------------------------------------------------------------ |
+| [Objects365v1](https://opendatalab.com/OpenDataLab/Objects365_v1) | Detection | 609k | 9621k | [objects365_train.json](https://opendatalab.com/OpenDataLab/Objects365_v1) |
+| [GQA](https://downloads.cs.stanford.edu/nlp/data/gqa/images.zip) | [Grounding](https://www.ultralytics.com/glossary/grounding) | 621k | 3681k | [final_mixed_train_no_coco.json](https://huggingface.co/GLIPModel/GLIP/blob/main/mdetr_annotations/final_mixed_train_no_coco.json) |
+| [Flickr30k](https://shannon.cs.illinois.edu/DenotationGraph/) | Grounding | 149k | 641k | [final_flickr_separateGT_train.json](https://huggingface.co/GLIPModel/GLIP/blob/main/mdetr_annotations/final_flickr_separateGT_train.json) |
- Val data
diff --git a/docs/en/models/yolo11.md b/docs/en/models/yolo11.md
index 05761521..972d53ac 100644
--- a/docs/en/models/yolo11.md
+++ b/docs/en/models/yolo11.md
@@ -33,7 +33,7 @@ YOLO11 is the latest iteration in the [Ultralytics](https://www.ultralytics.com/
## Key Features
-- **Enhanced Feature Extraction:** YOLO11 employs an improved backbone and neck architecture, which enhances [feature extraction](https://www.ultralytics.com/glossary/feature-extraction) capabilities for more precise object detection and complex task performance.
+- **Enhanced Feature Extraction:** YOLO11 employs an improved [backbone](https://www.ultralytics.com/glossary/backbone) and neck architecture, which enhances [feature extraction](https://www.ultralytics.com/glossary/feature-extraction) capabilities for more precise object detection and complex task performance.
- **Optimized for Efficiency and Speed:** YOLO11 introduces refined architectural designs and optimized training pipelines, delivering faster processing speeds and maintaining an optimal balance between accuracy and performance.
- **Greater Accuracy with Fewer Parameters:** With advancements in model design, YOLO11m achieves a higher [mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) on the COCO dataset while using 22% fewer parameters than YOLOv8m, making it computationally efficient without compromising accuracy.
- **Adaptability Across Environments:** YOLO11 can be seamlessly deployed across various environments, including edge devices, cloud platforms, and systems supporting NVIDIA GPUs, ensuring maximum flexibility.
diff --git a/docs/en/models/yolo12.md b/docs/en/models/yolo12.md
new file mode 100644
index 00000000..11da8e53
--- /dev/null
+++ b/docs/en/models/yolo12.md
@@ -0,0 +1,175 @@
+---
+comments: true
+description: Discover YOLO12, featuring groundbreaking attention-centric architecture for state-of-the-art object detection with unmatched accuracy and efficiency.
+keywords: YOLO12, attention-centric object detection, YOLO series, Ultralytics, computer vision, AI, machine learning, deep learning
+---
+
+# YOLO12: Attention-Centric Object Detection
+
+## Overview
+
+YOLO12 introduces an attention-centric architecture that departs from the traditional CNN-based approaches used in previous YOLO models, yet retains the real-time inference speed essential for many applications. This model achieves state-of-the-art object detection accuracy through novel methodological innovations in attention mechanisms and overall network architecture, while maintaining real-time performance.
+
+## Key Features
+
+- **Area Attention Mechanism**: A new self-attention approach that processes large receptive fields efficiently. It divides [feature maps](https://www.ultralytics.com/glossary/feature-maps) into _l_ equal-sized regions (defaulting to 4), either horizontally or vertically, avoiding complex operations and maintaining a large effective receptive field. This significantly reduces computational cost compared to standard self-attention.
+- **Residual Efficient Layer Aggregation Networks (R-ELAN)**: An improved feature aggregation module based on ELAN, designed to address optimization challenges, especially in larger-scale attention-centric models. R-ELAN introduces:
+ - Block-level residual connections with scaling (similar to layer scaling).
+ - A redesigned feature aggregation method creating a bottleneck-like structure.
+- **Optimized Attention Architecture**: YOLO12 streamlines the standard attention mechanism for greater efficiency and compatibility with the YOLO framework. This includes:
+ - Using FlashAttention to minimize memory access overhead.
+ - Removing positional encoding for a cleaner and faster model.
+ - Adjusting the MLP ratio (from the typical 4 to 1.2 or 2) to better balance computation between attention and feed-forward layers.
+ - Reducing the depth of stacked blocks for improved optimization.
+ - Leveraging convolution operations (where appropriate) for their computational efficiency.
+ - Adding a 7x7 separable convolution (the "position perceiver") to the attention mechanism to implicitly encode positional information.
+- **Comprehensive Task Support**: YOLO12 supports a range of core computer vision tasks: object detection, [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), [image classification](https://www.ultralytics.com/glossary/image-classification), pose estimation, and oriented object detection (OBB).
+- **Enhanced Efficiency**: Achieves higher accuracy with fewer parameters compared to many prior models, demonstrating an improved balance between speed and accuracy.
+- **Flexible Deployment**: Designed for deployment across diverse platforms, from edge devices to cloud infrastructure.
+
+## Supported Tasks and Modes
+
+YOLO12 supports a variety of computer vision tasks. The table below shows task support and the operational modes (Inference, Validation, Training, and Export) enabled for each:
+
+| Model Type | Task | Inference | Validation | Training | Export |
+| ----------------------------------------------------------------------------------------------------------------- | -------------------------------------- | --------- | ---------- | -------- | ------ |
+| [YOLO12](https://github.com/ultralytics/ultralytics/blob/yolov12/ultralytics/cfg/models/12/yolo12.yaml) | [Detection](../tasks/detect.md) | ✅ | ✅ | ✅ | ✅ |
+| [YOLO12-seg](https://github.com/ultralytics/ultralytics/blob/yolov12/ultralytics/cfg/models/12/yolo12-seg.yaml) | [Segmentation](../tasks/segment.md) | ✅ | ✅ | ✅ | ✅ |
+| [YOLO12-pose](https://github.com/ultralytics/ultralytics/blob/yolov12/ultralytics/cfg/models/12/yolo12-pose.yaml) | [Pose](../tasks/pose.md) | ✅ | ✅ | ✅ | ✅ |
+| [YOLO12-cls](https://github.com/ultralytics/ultralytics/blob/yolov12/ultralytics/cfg/models/12/yolo12-cls.yaml) | [Classification](../tasks/classify.md) | ✅ | ✅ | ✅ | ✅ |
+| [YOLO12-obb](https://github.com/ultralytics/ultralytics/blob/yolov12/ultralytics/cfg/models/12/yolo12-obb.yaml) | [OBB](../tasks/obb.md) | ✅ | ✅ | ✅ | ✅ |
+
+## Performance Metrics
+
+
+
+
+
+
+YOLO12 demonstrates significant [accuracy](https://www.ultralytics.com/glossary/accuracy) improvements across all model scales, with some trade-offs in speed compared to the _fastest_ prior YOLO models. Below are quantitative results for [object detection](https://www.ultralytics.com/glossary/object-detection) on the COCO validation dataset:
+
+### Detection Performance (COCO val2017)
+
+| Model | size
(pixels) | mAPval
50-95 | Speed
CPU ONNX
(ms) | Speed
T4 TensorRT
(ms) | params
(M) | FLOPs
(B) | Comparison
(mAP/Speed) |
+| ------------------------------------------------------------------------------------ | --------------------- | -------------------- | ------------------------------ | --------------------------------- | ------------------ | ----------------- | -------------------------------- |
+| [YOLO12n](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12n.pt) | 640 | 40.6 | - | 1.64 | 2.6 | 6.5 | +2.1% / -9% (vs. YOLOv10n) |
+| [YOLO12s](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12s.pt) | 640 | 48.0 | - | 2.61 | 9.3 | 21.4 | +0.1% / +42% (vs. RT-DETRv2-R18) |
+| [YOLO12m](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12m.pt) | 640 | 52.5 | - | 4.86 | 20.2 | 67.5 | +1.0% / +3% (vs. YOLO11m) |
+| [YOLO12l](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12l.pt) | 640 | 53.7 | - | 6.77 | 26.4 | 88.9 | +0.4% / -8% (vs. YOLO11l) |
+| [YOLO12x](https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo12x.pt) | 640 | 55.2 | - | 11.79 | 59.1 | 199.0 | +0.6% / -4% (vs. YOLO11x) |
+
+- Inference speed measured on an NVIDIA T4 GPU with TensorRT FP16 [precision](https://www.ultralytics.com/glossary/precision).
+- Comparisons show the relative improvement in mAP and the percentage change in speed (positive indicates faster; negative indicates slower). Comparisons are made against published results for YOLOv10, YOLO11, and RT-DETR where available.
+
+## Usage Examples
+
+This section provides examples for training and inference with YOLO12. For more comprehensive documentation on these and other modes (including [Validation](../modes/val.md) and [Export](../modes/export.md)), consult the dedicated [Predict](../modes/predict.md) and [Train](../modes/train.md) pages.
+
+The examples below focus on YOLO12 [Detect](../tasks/detect.md) models (for object detection). For other supported tasks (segmentation, classification, oriented object detection, and pose estimation), refer to the respective task-specific documentation: [Segment](../tasks/segment.md), [Classify](../tasks/classify.md), [OBB](../tasks/obb.md), and [Pose](../tasks/pose.md).
+
+!!! example
+
+ === "Python"
+
+ Pretrained `*.pt` models (using [PyTorch](https://pytorch.org/)) and configuration `*.yaml` files can be passed to the `YOLO()` class to create a model instance in Python:
+
+ ```python
+ from ultralytics import YOLO
+
+ # Load a COCO-pretrained YOLO12n model
+ model = YOLO("yolo12n.pt")
+
+ # Train the model on the COCO8 example dataset for 100 epochs
+ results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
+
+ # Run inference with the YOLO12n model on the 'bus.jpg' image
+ results = model("path/to/bus.jpg")
+ ```
+
+ === "CLI"
+
+ Command Line Interface (CLI) commands are also available:
+
+ ```bash
+ # Load a COCO-pretrained YOLO12n model and train on the COCO8 example dataset for 100 epochs
+ yolo train model=yolo12n.pt data=coco8.yaml epochs=100 imgsz=640
+
+ # Load a COCO-pretrained YOLO12n model and run inference on the 'bus.jpg' image
+ yolo predict model=yolo12n.pt source=path/to/bus.jpg
+ ```
+
+## Key Improvements
+
+1. **Enhanced [Feature Extraction](https://www.ultralytics.com/glossary/feature-extraction)**:
+
+ - **Area Attention**: Efficiently handles large [receptive fields](https://www.ultralytics.com/glossary/receptive-field), reducing computational cost.
+ - **Optimized Balance**: Improved balance between attention and feed-forward network computations.
+ - **R-ELAN**: Enhances feature aggregation using the R-ELAN architecture.
+
+2. **Optimization Innovations**:
+
+ - **Residual Connections**: Introduces residual connections with scaling to stabilize training, especially in larger models.
+ - **Refined Feature Integration**: Implements an improved method for feature integration within R-ELAN.
+ - **FlashAttention**: Incorporates FlashAttention to reduce memory access overhead.
+
+3. **Architectural Efficiency**:
+
+ - **Reduced Parameters**: Achieves a lower parameter count while maintaining or improving accuracy compared to many previous models.
+ - **Streamlined Attention**: Uses a simplified attention implementation, avoiding positional encoding.
+ - **Optimized MLP Ratios**: Adjusts MLP ratios to more effectively allocate computational resources.
+
+## Requirements
+
+The Ultralytics YOLO12 implementation, by default, _does not require_ FlashAttention. However, FlashAttention can be optionally compiled and used with YOLO12. To compile FlashAttention, one of the following NVIDIA GPUs is needed:
+
+- [Turing GPUs](
+
+## ::: ultralytics.nn.modules.block.AAttn
+
+
+
+## ::: ultralytics.nn.modules.block.ABlock
+
+
+
+## ::: ultralytics.nn.modules.block.A2C2f
+
diff --git a/docs/overrides/javascript/benchmark.js b/docs/overrides/javascript/benchmark.js
index ea65d377..54c883ad 100644
--- a/docs/overrides/javascript/benchmark.js
+++ b/docs/overrides/javascript/benchmark.js
@@ -1,5 +1,12 @@
// YOLO models chart ---------------------------------------------------------------------------------------------------
const data = {
+ // YOLO12: {
+ // n: { speed: 1.64, mAP: 40.6 },
+ // s: { speed: 2.61, mAP: 48.0 },
+ // m: { speed: 4.86, mAP: 52.5 },
+ // l: { speed: 6.77, mAP: 53.7 },
+ // x: { speed: 11.79, mAP: 55.2 },
+ // },
YOLO11: {
n: { speed: 1.55, mAP: 39.5 },
s: { speed: 2.63, mAP: 47.0 },
diff --git a/mkdocs.yml b/mkdocs.yml
index 9580d19a..6886a40d 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -258,6 +258,7 @@ nav:
- YOLOv9: models/yolov9.md
- YOLOv10: models/yolov10.md
- YOLO11 🚀 NEW: models/yolo11.md
+ - YOLO12: models/yolo12.md
- SAM (Segment Anything Model): models/sam.md
- SAM 2 (Segment Anything Model 2): models/sam-2.md
- MobileSAM (Mobile Segment Anything Model): models/mobile-sam.md
diff --git a/ultralytics/__init__.py b/ultralytics/__init__.py
index e781bb33..fd153110 100644
--- a/ultralytics/__init__.py
+++ b/ultralytics/__init__.py
@@ -1,6 +1,6 @@
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
-__version__ = "8.3.77"
+__version__ = "8.3.78"
import os
diff --git a/ultralytics/cfg/models/12/yolo12-cls.yaml b/ultralytics/cfg/models/12/yolo12-cls.yaml
new file mode 100644
index 00000000..b0e15cee
--- /dev/null
+++ b/ultralytics/cfg/models/12/yolo12-cls.yaml
@@ -0,0 +1,32 @@
+# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
+
+# YOLO12-cls image classification model
+# Model docs: https://docs.ultralytics.com/models/yolo12
+# Task docs: https://docs.ultralytics.com/tasks/classify
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolo12n-cls.yaml' will call yolo12-cls.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.50, 0.25, 1024] # summary: 152 layers, 1,820,976 parameters, 1,820,976 gradients, 3.7 GFLOPs
+ s: [0.50, 0.50, 1024] # summary: 152 layers, 6,206,992 parameters, 6,206,992 gradients, 13.6 GFLOPs
+ m: [0.50, 1.00, 512] # summary: 172 layers, 12,083,088 parameters, 12,083,088 gradients, 44.2 GFLOPs
+ l: [1.00, 1.00, 512] # summary: 312 layers, 15,558,640 parameters, 15,558,640 gradients, 56.9 GFLOPs
+ x: [1.00, 1.50, 512] # summary: 312 layers, 34,172,592 parameters, 34,172,592 gradients, 126.5 GFLOPs
+
+# YOLO12n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 2, C3k2, [256, False, 0.25]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 2, C3k2, [512, False, 0.25]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 4, A2C2f, [512, True, 4]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 4, A2C2f, [1024, True, 1]] # 8
+
+# YOLO12n head
+head:
+ - [-1, 1, Classify, [nc]] # Classify
diff --git a/ultralytics/cfg/models/12/yolo12-obb.yaml b/ultralytics/cfg/models/12/yolo12-obb.yaml
new file mode 100644
index 00000000..e5c36f0c
--- /dev/null
+++ b/ultralytics/cfg/models/12/yolo12-obb.yaml
@@ -0,0 +1,48 @@
+# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
+
+# YOLO12-obb Oriented Bounding Boxes (OBB) model with P3/8 - P5/32 outputs
+# Model docs: https://docs.ultralytics.com/models/yolo12
+# Task docs: https://docs.ultralytics.com/tasks/obb
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolo12n-obb.yaml' will call yolo12-obb.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.50, 0.25, 1024] # summary: 287 layers, 2,673,955 parameters, 2,673,939 gradients, 6.9 GFLOPs
+ s: [0.50, 0.50, 1024] # summary: 287 layers, 9,570,275 parameters, 9,570,259 gradients, 22.7 GFLOPs
+ m: [0.50, 1.00, 512] # summary: 307 layers, 21,048,003 parameters, 21,047,987 gradients, 71.8 GFLOPs
+ l: [1.00, 1.00, 512] # summary: 503 layers, 27,299,619 parameters, 27,299,603 gradients, 93.4 GFLOPs
+ x: [1.00, 1.50, 512] # summary: 503 layers, 61,119,939 parameters, 61,119,923 gradients, 208.6 GFLOPs
+
+# YOLO12n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 2, C3k2, [256, False, 0.25]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 2, C3k2, [512, False, 0.25]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 4, A2C2f, [512, True, 4]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 4, A2C2f, [1024, True, 1]] # 8
+
+# YOLO12n head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 2, A2C2f, [512, False, -1]] # 11
+
+ - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 2, A2C2f, [256, False, -1]] # 14
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 11], 1, Concat, [1]] # cat head P4
+ - [-1, 2, A2C2f, [512, False, -1]] # 17
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 8], 1, Concat, [1]] # cat head P5
+ - [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)
+
+ - [[14, 17, 20], 1, OBB, [nc, 1]] # Detect(P3, P4, P5)
diff --git a/ultralytics/cfg/models/12/yolo12-pose.yaml b/ultralytics/cfg/models/12/yolo12-pose.yaml
new file mode 100644
index 00000000..104a1865
--- /dev/null
+++ b/ultralytics/cfg/models/12/yolo12-pose.yaml
@@ -0,0 +1,49 @@
+# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
+
+# YOLO12-pose keypoints/pose estimation model with P3/8 - P5/32 outputs
+# Model docs: https://docs.ultralytics.com/models/yolo12
+# Task docs: https://docs.ultralytics.com/tasks/pose
+
+# Parameters
+nc: 80 # number of classes
+kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
+scales: # model compound scaling constants, i.e. 'model=yolo12n-pose.yaml' will call yolo12-pose.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.50, 0.25, 1024] # summary: 287 layers, 2,886,715 parameters, 2,886,699 gradients, 7.8 GFLOPs
+ s: [0.50, 0.50, 1024] # summary: 287 layers, 9,774,155 parameters, 9,774,139 gradients, 23.5 GFLOPs
+ m: [0.50, 1.00, 512] # summary: 307 layers, 21,057,753 parameters, 21,057,737 gradients, 71.8 GFLOPs
+ l: [1.00, 1.00, 512] # summary: 503 layers, 27,309,369 parameters, 27,309,353 gradients, 93.5 GFLOPs
+ x: [1.00, 1.50, 512] # summary: 503 layers, 61,134,489 parameters, 61,134,473 gradients, 208.7 GFLOPs
+
+# YOLO12n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 2, C3k2, [256, False, 0.25]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 2, C3k2, [512, False, 0.25]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 4, A2C2f, [512, True, 4]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 4, A2C2f, [1024, True, 1]] # 8
+
+# YOLO12n head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 2, A2C2f, [512, False, -1]] # 11
+
+ - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 2, A2C2f, [256, False, -1]] # 14
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 11], 1, Concat, [1]] # cat head P4
+ - [-1, 2, A2C2f, [512, False, -1]] # 17
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 8], 1, Concat, [1]] # cat head P5
+ - [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)
+
+ - [[14, 17, 20], 1, Pose, [nc, kpt_shape]] # Detect(P3, P4, P5)
diff --git a/ultralytics/cfg/models/12/yolo12-seg.yaml b/ultralytics/cfg/models/12/yolo12-seg.yaml
new file mode 100644
index 00000000..6d03a3e2
--- /dev/null
+++ b/ultralytics/cfg/models/12/yolo12-seg.yaml
@@ -0,0 +1,48 @@
+# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
+
+# YOLO12-seg instance segmentation model with P3/8 - P5/32 outputs
+# Model docs: https://docs.ultralytics.com/models/yolo12
+# Task docs: https://docs.ultralytics.com/tasks/segment
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolo12n-seg.yaml' will call yolo12-seg.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.50, 0.25, 1024] # summary: 294 layers, 2,855,056 parameters, 2,855,040 gradients, 10.6 GFLOPs
+ s: [0.50, 0.50, 1024] # summary: 294 layers, 9,938,592 parameters, 9,938,576 gradients, 35.7 GFLOPs
+ m: [0.50, 1.00, 512] # summary: 314 layers, 22,505,376 parameters, 22,505,360 gradients, 123.5 GFLOPs
+ l: [1.00, 1.00, 512] # summary: 510 layers, 28,756,992 parameters, 28,756,976 gradients, 145.1 GFLOPs
+ x: [1.00, 1.50, 512] # summary: 510 layers, 64,387,264 parameters, 64,387,248 gradients, 324.6 GFLOPs
+
+# YOLO12n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 2, C3k2, [256, False, 0.25]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 2, C3k2, [512, False, 0.25]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 4, A2C2f, [512, True, 4]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 4, A2C2f, [1024, True, 1]] # 8
+
+# YOLO12n head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 2, A2C2f, [512, False, -1]] # 11
+
+ - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 2, A2C2f, [256, False, -1]] # 14
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 11], 1, Concat, [1]] # cat head P4
+ - [-1, 2, A2C2f, [512, False, -1]] # 17
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 8], 1, Concat, [1]] # cat head P5
+ - [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)
+
+ - [[14, 17, 20], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)
diff --git a/ultralytics/cfg/models/12/yolo12.yaml b/ultralytics/cfg/models/12/yolo12.yaml
new file mode 100644
index 00000000..737c0333
--- /dev/null
+++ b/ultralytics/cfg/models/12/yolo12.yaml
@@ -0,0 +1,48 @@
+# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
+
+# YOLO12 object detection model with P3/8 - P5/32 outputs
+# Model docs: https://docs.ultralytics.com/models/yolo12
+# Task docs: https://docs.ultralytics.com/tasks/detect
+
+# Parameters
+nc: 80 # number of classes
+scales: # model compound scaling constants, i.e. 'model=yolo12n.yaml' will call yolo12.yaml with scale 'n'
+ # [depth, width, max_channels]
+ n: [0.50, 0.25, 1024] # summary: 272 layers, 2,602,288 parameters, 2,602,272 gradients, 6.7 GFLOPs
+ s: [0.50, 0.50, 1024] # summary: 272 layers, 9,284,096 parameters, 9,284,080 gradients, 21.7 GFLOPs
+ m: [0.50, 1.00, 512] # summary: 292 layers, 20,199,168 parameters, 20,199,152 gradients, 68.1 GFLOPs
+ l: [1.00, 1.00, 512] # summary: 488 layers, 26,450,784 parameters, 26,450,768 gradients, 89.7 GFLOPs
+ x: [1.00, 1.50, 512] # summary: 488 layers, 59,210,784 parameters, 59,210,768 gradients, 200.3 GFLOPs
+
+# YOLO12n backbone
+backbone:
+ # [from, repeats, module, args]
+ - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
+ - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
+ - [-1, 2, C3k2, [256, False, 0.25]]
+ - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
+ - [-1, 2, C3k2, [512, False, 0.25]]
+ - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
+ - [-1, 4, A2C2f, [512, True, 4]]
+ - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
+ - [-1, 4, A2C2f, [1024, True, 1]] # 8
+
+# YOLO12n head
+head:
+ - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
+ - [[-1, 6], 1, Concat, [1]] # cat backbone P4
+ - [-1, 2, A2C2f, [512, False, -1]] # 11
+
+ - [-1, 1, nn.Upsample, [None, 2, "nearest"]]
+ - [[-1, 4], 1, Concat, [1]] # cat backbone P3
+ - [-1, 2, A2C2f, [256, False, -1]] # 14
+
+ - [-1, 1, Conv, [256, 3, 2]]
+ - [[-1, 11], 1, Concat, [1]] # cat head P4
+ - [-1, 2, A2C2f, [512, False, -1]] # 17
+
+ - [-1, 1, Conv, [512, 3, 2]]
+ - [[-1, 8], 1, Concat, [1]] # cat head P5
+ - [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)
+
+ - [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)
diff --git a/ultralytics/nn/modules/__init__.py b/ultralytics/nn/modules/__init__.py
index 0a01d706..db951634 100644
--- a/ultralytics/nn/modules/__init__.py
+++ b/ultralytics/nn/modules/__init__.py
@@ -30,6 +30,7 @@ from .block import (
SPP,
SPPELAN,
SPPF,
+ A2C2f,
AConv,
ADown,
Attention,
@@ -160,4 +161,5 @@ __all__ = (
"PSA",
"TorchVision",
"Index",
+ "A2C2f",
)
diff --git a/ultralytics/nn/modules/block.py b/ultralytics/nn/modules/block.py
index beb03c20..567e1aaf 100644
--- a/ultralytics/nn/modules/block.py
+++ b/ultralytics/nn/modules/block.py
@@ -1154,3 +1154,205 @@ class TorchVision(nn.Module):
else:
y = self.m(x)
return y
+
+
+class AAttn(nn.Module):
+ """
+ Area-attention module for YOLO models, providing efficient attention mechanisms.
+
+ This module implements an area-based attention mechanism that processes input features in a spatially-aware manner,
+ making it particularly effective for object detection tasks.
+
+ Attributes:
+ area (int): Number of areas the feature map is divided.
+ num_heads (int): Number of heads into which the attention mechanism is divided.
+ head_dim (int): Dimension of each attention head.
+ qkv (Conv): Convolution layer for computing query, key and value tensors.
+ proj (Conv): Projection convolution layer.
+ pe (Conv): Position encoding convolution layer.
+
+ Methods:
+ forward: Applies area-attention to input tensor.
+
+ Examples:
+ >>> attn = AAttn(dim=256, num_heads=8, area=4)
+ >>> x = torch.randn(1, 256, 32, 32)
+ >>> output = attn(x)
+ >>> print(output.shape)
+ torch.Size([1, 256, 32, 32])
+ """
+
+ def __init__(self, dim, num_heads, area=1):
+ """
+ Initializes an Area-attention module for YOLO models.
+
+ Args:
+ dim (int): Number of hidden channels.
+ num_heads (int): Number of heads into which the attention mechanism is divided.
+ area (int): Number of areas the feature map is divided, default is 1.
+ """
+ super().__init__()
+ self.area = area
+
+ self.num_heads = num_heads
+ self.head_dim = head_dim = dim // num_heads
+ all_head_dim = head_dim * self.num_heads
+
+ self.qkv = Conv(dim, all_head_dim * 3, 1, act=False)
+ self.proj = Conv(all_head_dim, dim, 1, act=False)
+ self.pe = Conv(all_head_dim, dim, 7, 1, 3, g=dim, act=False)
+
+ def forward(self, x):
+ """Processes the input tensor 'x' through the area-attention."""
+ B, C, H, W = x.shape
+ N = H * W
+
+ qkv = self.qkv(x).flatten(2).transpose(1, 2)
+ if self.area > 1:
+ qkv = qkv.reshape(B * self.area, N // self.area, C * 3)
+ B, N, _ = qkv.shape
+ q, k, v = (
+ qkv.view(B, N, self.num_heads, self.head_dim * 3)
+ .permute(0, 2, 3, 1)
+ .split([self.head_dim, self.head_dim, self.head_dim], dim=2)
+ )
+ attn = (q.transpose(-2, -1) @ k) * (self.head_dim**-0.5)
+ attn = attn.softmax(dim=-1)
+ x = v @ attn.transpose(-2, -1)
+ x = x.permute(0, 3, 1, 2)
+ v = v.permute(0, 3, 1, 2)
+
+ if self.area > 1:
+ x = x.reshape(B // self.area, N * self.area, C)
+ v = v.reshape(B // self.area, N * self.area, C)
+ B, N, _ = x.shape
+
+ x = x.reshape(B, H, W, C).permute(0, 3, 1, 2)
+ v = v.reshape(B, H, W, C).permute(0, 3, 1, 2)
+
+ x = x + self.pe(v)
+ return self.proj(x)
+
+
+class ABlock(nn.Module):
+ """
+ Area-attention block module for efficient feature extraction in YOLO models.
+
+ This module implements an area-attention mechanism combined with a feed-forward network for processing feature maps.
+ It uses a novel area-based attention approach that is more efficient than traditional self-attention while
+ maintaining effectiveness.
+
+ Attributes:
+ attn (AAttn): Area-attention module for processing spatial features.
+ mlp (nn.Sequential): Multi-layer perceptron for feature transformation.
+
+ Methods:
+ _init_weights: Initializes module weights using truncated normal distribution.
+ forward: Applies area-attention and feed-forward processing to input tensor.
+
+ Examples:
+ >>> block = ABlock(dim=256, num_heads=8, mlp_ratio=1.2, area=1)
+ >>> x = torch.randn(1, 256, 32, 32)
+ >>> output = block(x)
+ >>> print(output.shape)
+ torch.Size([1, 256, 32, 32])
+ """
+
+ def __init__(self, dim, num_heads, mlp_ratio=1.2, area=1):
+ """
+ Initializes an Area-attention block module for efficient feature extraction in YOLO models.
+
+ This module implements an area-attention mechanism combined with a feed-forward network for processing feature
+ maps. It uses a novel area-based attention approach that is more efficient than traditional self-attention
+ while maintaining effectiveness.
+
+ Args:
+ dim (int): Number of input channels.
+ num_heads (int): Number of heads into which the attention mechanism is divided.
+ mlp_ratio (float): Expansion ratio for MLP hidden dimension.
+ area (int): Number of areas the feature map is divided.
+ """
+ super().__init__()
+
+ self.attn = AAttn(dim, num_heads=num_heads, area=area)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = nn.Sequential(Conv(dim, mlp_hidden_dim, 1), Conv(mlp_hidden_dim, dim, 1, act=False))
+
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ """Initialize weights using a truncated normal distribution."""
+ if isinstance(m, nn.Conv2d):
+ nn.init.trunc_normal_(m.weight, std=0.02)
+ if m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+
+ def forward(self, x):
+ """Forward pass through ABlock, applying area-attention and feed-forward layers to the input tensor."""
+ x = x + self.attn(x)
+ return x + self.mlp(x)
+
+
+class A2C2f(nn.Module):
+ """
+ Area-Attention C2f module for enhanced feature extraction with area-based attention mechanisms.
+
+ This module extends the C2f architecture by incorporating area-attention and ABlock layers for improved feature
+ processing. It supports both area-attention and standard convolution modes.
+
+ Attributes:
+ cv1 (Conv): Initial 1x1 convolution layer that reduces input channels to hidden channels.
+ cv2 (Conv): Final 1x1 convolution layer that processes concatenated features.
+ gamma (nn.Parameter | None): Learnable parameter for residual scaling when using area attention.
+ m (nn.ModuleList): List of either ABlock or C3k modules for feature processing.
+
+ Methods:
+ forward: Processes input through area-attention or standard convolution pathway.
+
+ Examples:
+ >>> m = A2C2f(512, 512, n=1, a2=True, area=1)
+ >>> x = torch.randn(1, 512, 32, 32)
+ >>> output = m(x)
+ >>> print(output.shape)
+ torch.Size([1, 512, 32, 32])
+ """
+
+ def __init__(self, c1, c2, n=1, a2=True, area=1, residual=False, mlp_ratio=2.0, e=0.5, g=1, shortcut=True):
+ """
+ Area-Attention C2f module for enhanced feature extraction with area-based attention mechanisms.
+
+ Args:
+ c1 (int): Number of input channels.
+ c2 (int): Number of output channels.
+ n (int): Number of ABlock or C3k modules to stack.
+ a2 (bool): Whether to use area attention blocks. If False, uses C3k blocks instead.
+ area (int): Number of areas the feature map is divided.
+ residual (bool): Whether to use residual connections with learnable gamma parameter.
+ mlp_ratio (float): Expansion ratio for MLP hidden dimension.
+ e (float): Channel expansion ratio for hidden channels.
+ g (int): Number of groups for grouped convolutions.
+ shortcut (bool): Whether to use shortcut connections in C3k blocks.
+ """
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ assert c_ % 32 == 0, "Dimension of ABlock be a multiple of 32."
+
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv((1 + n) * c_, c2, 1)
+
+ self.gamma = nn.Parameter(0.01 * torch.ones(c2), requires_grad=True) if a2 and residual else None
+ self.m = nn.ModuleList(
+ nn.Sequential(*(ABlock(c_, c_ // 32, mlp_ratio, area) for _ in range(2)))
+ if a2
+ else C3k(c_, c_, 2, shortcut, g)
+ for _ in range(n)
+ )
+
+ def forward(self, x):
+ """Forward pass through R-ELAN layer."""
+ y = [self.cv1(x)]
+ y.extend(m(y[-1]) for m in self.m)
+ y = self.cv2(torch.cat(y, 1))
+ if self.gamma is not None:
+ return x + self.gamma.view(-1, len(self.gamma), 1, 1) * y
+ return y
diff --git a/ultralytics/nn/tasks.py b/ultralytics/nn/tasks.py
index 5a5052fd..44e7b75c 100644
--- a/ultralytics/nn/tasks.py
+++ b/ultralytics/nn/tasks.py
@@ -22,6 +22,7 @@ from ultralytics.nn.modules import (
SPP,
SPPELAN,
SPPF,
+ A2C2f,
AConv,
ADown,
Bottleneck,
@@ -985,6 +986,7 @@ def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
PSA,
SCDown,
C2fCIB,
+ A2C2f,
}
)
repeat_modules = frozenset( # modules with 'repeat' arguments
@@ -1003,6 +1005,7 @@ def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
C2fPSA,
C2fCIB,
C2PSA,
+ A2C2f,
}
)
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
@@ -1034,6 +1037,10 @@ def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
legacy = False
if scale in "mlx":
args[3] = True
+ if m is A2C2f:
+ legacy = False
+ if scale in "lx": # for L/X sizes
+ args.extend((True, 1.2))
elif m is AIFI:
args = [ch[f], *args]
elif m in frozenset({HGStem, HGBlock}):
diff --git a/ultralytics/utils/downloads.py b/ultralytics/utils/downloads.py
index be33ae8a..48b95067 100644
--- a/ultralytics/utils/downloads.py
+++ b/ultralytics/utils/downloads.py
@@ -18,6 +18,7 @@ GITHUB_ASSETS_REPO = "ultralytics/assets"
GITHUB_ASSETS_NAMES = (
[f"yolov8{k}{suffix}.pt" for k in "nsmlx" for suffix in ("", "-cls", "-seg", "-pose", "-obb", "-oiv7")]
+ [f"yolo11{k}{suffix}.pt" for k in "nsmlx" for suffix in ("", "-cls", "-seg", "-pose", "-obb")]
+ + [f"yolo12{k}{suffix}.pt" for k in "nsmlx" for suffix in ("",)] # detect models only currently
+ [f"yolov5{k}{resolution}u.pt" for k in "nsmlx" for resolution in ("", "6")]
+ [f"yolov3{k}u.pt" for k in ("", "-spp", "-tiny")]
+ [f"yolov8{k}-world.pt" for k in "smlx"]